pandas中對文本類型數據的處理小結
下面看下pandas中字符串類處理函數吧,內容如下所示:
1.英文字母大小寫轉換及填充
s = pd.Series(['lower', 'CAPITALS', 'this is a sentence', 'SwApCaSe'])
- 大寫轉小寫: s.str.lower()
- 小寫轉大寫:s.str.upper()
- 轉為新聞標題形式:s.str.title()
- 首字母大寫,其餘小寫:s.str.capitalize()
- 將原來的大寫和小寫,分別轉為小寫和大寫,即大小寫互換:s.str.swapcase()
- 將文字內容用某種字符填充到固定長度,會從兩邊進行填充:s.str.center(4,’*’)
- 將文字內容用某種字符填充到固定長度,可以設置填充方向(默認為left,可以設置為left,right,both):s.str.pad(width=10, side=‘right’, fillchar=’-‘)
- 將文字內容用某種字符填充到固定長度,會從文字的右方進行填充,即原來的字符串在左邊:s.str.ljust(4,’-‘)
- 將文字內容用某種字符填充到固定長度,會從文字的左方進行填充,即原來的字符串在右邊:s.str.rjust(4,’-‘)
- 將文字內容用某種字符按照指定的方向(left,right,both)填充到固定長度: s.str.pad(3,side=‘left’,fillchar=’*’)
- 在字符串前添加0到指定長度:
- s = pd.Series([‘-1′, ‘1′, ‘1000’, 10, np.nan])
- s.str.zfill(3)
2.字符串合並與拆分
2.1 多列字符串合並
註意:多列字符串在合並時,推薦使用cat函數,該函數是按照索引進行合並的。
s=pd.DataFrame({'col1':['a', 'b', np.nan, 'd'],'col2':['A', 'B', 'C', 'D']})
# 1.有一個缺失值的行不進行合並
s['col1'].str.cat([s['col2']])
# 2.用固定字符(*)替換缺失值,並進行合並
s['col1'].str.cat([s['col2']],na_rep='*')
# 3.用固定字符(*)替換缺失值,並用分隔符(,)進行合並
s['col1'].str.cat([s['col2']],na_rep='*',sep=',')
# 4.索引不一致的合並
#創建series
s = pd.Series(['a', 'b', np.nan, 'd'])
t = pd.Series(['d', 'a', 'e', 'c'], index=[3, 0, 4, 2])
#合並
s.str.cat(t, join='left', na_rep='-')
s.str.cat(t, join='right', na_rep='-')
s.str.cat(t, join='outer', na_rep='-')
s.str.cat(t, join='inner', na_rep='-')
2.2 一列 列表形式的文本合並為一列
s = pd.Series([['lion', 'elephant', 'zebra'], [1.1, 2.2, 3.3], [
'cat', np.nan, 'dog'], ['cow', 4.5, 'goat'], ['duck', ['swan', 'fish'], 'guppy']])
#以下劃線進行拼接
s.str.join('_')
使用前:

使用後:

2.3 一列字符串與自身合並成為一列
s = pd.Series(['a', 'b', 'c']) #指定數字 s.str.repeat(repeats=2) #指定列表 s.str.repeat(repeats=[1, 2, 3])
使用該函數後,效果圖分別如下:


2.4 一列字符串拆分為多列
2.4.1 partition函數
partition函數,會將某列字符串拆分為3列,其中2列為值,1列為分隔符。
有兩個參數進行設置,分別為:sep(分隔符,默認為空格),expand(是否生成dataframe,默認為True)
s = pd.Series(['Linda van der Berg', 'George Pitt-Rivers'])
#默認寫法,以空格分割,會以第一個分隔符進行拆分
s.str.partition()
#另一寫法,會以最後一個分隔符進行拆分
s.str.rpartition()
#以固定符號作為分隔符
s.str.partition('-', expand=False)
#拆分索引
idx = pd.Index(['X 123', 'Y 999'])
idx.str.partition()
2.4.2 split函數
split函數會按照分隔符拆分為多個值。
參數:
pat(分隔符,默認為空格);
n(限制分隔的輸出,即查找幾個分隔符,默認-1,表示全部);
expend(是否生成dataframe,默認為False)。
s = pd.Series(["this is a regular sentence","https://docs.python.org/3/tutorial/index.html",np.nan]) #1.默認按照空格進行拆分 s.str.split() #2.按照空格進行拆分,並限制2個分隔符的輸出 s.str.split(n=2) #3.以指定符號拆分,並生成新的dataframe s.str.split(pat = "/",expend=True) #4.使用正則表達式來進行拆分,並生成新的dataframe s = pd.Series(["1+1=2"]) s.str.split(r"\+|=", expand=True)
2.4.3 rsplit函數
如果不設置n的值,rsplit和split效果是相同的。區別是,split是從開始進行限制,rsplit是從末尾進行限制。
s = pd.Series(["this is a regular sentence","https://docs.python.org/3/tutorial/index.html",np.nan]) #區別於split s.str.rsplit(n=2)
3.字符串統計
3.1 統計某列字符串中包含某個字符串的個數
s = pd.Series(['dog', '', 5,{'foo' : 'bar'},[2, 3, 5, 7],('one', 'two', 'three')])
s.str.len()
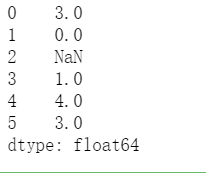
3.2 統計字符串長度
s = pd.Series(['dog', '', 5,{'foo' : 'bar'},[2, 3, 5, 7],('one', 'two', 'three')])
s.str.len()
效果圖如下:
4.字符串內容查找(包含正則)
4.1 extract
可通過正則表達式來提取指定內容,小括號內的會生成一列
s = pd.Series(['a1', 'b2', 'c3']) #按照小括號內的進行提取,生成兩列 s.str.extract(r'([ab])(\d)') #加上問號後,如果有一個匹配不上,還可以繼續匹配 s.str.extract(r'([ab])?(\d)') #可以對生成的新列進行重命名 s.str.extract(r'(?P<letter>[ab])(?P<digit>\d)') #生成1列 s.str.extract(r'[ab](\d)', expand=True)
4.2 extractall
區別於extract,該函數可以提取所有符合條件的元素
s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"]) #提取所有符合條件的數字,結果為多重索引1列 s.str.extractall(r"[ab](\d)") #提取符合條件的數字,並重命名,結果為多重索引1列 s.str.extractall(r"[ab](?P<digit>\d)") #提取符合條件的a、b和數字,結果為多重索引多列 s.str.extractall(r"(?P<letter>[ab])(?P<digit>\d)") #提取符合條件的a、b和數字,添加問號後,一個匹配不上可以繼續向後匹配,結果為多重索引多列 s.str.extractall(r"(?P<letter>[ab])?(?P<digit>\d)")
4.3 find
查詢固定字符串在目標字符串中的最小索引。
若需要查詢的字符串未出現在目標字符串中,則顯示為-1
s = pd.Series(['appoint', 'price', 'sleep','amount'])
s.str.find('p')
顯示結果如下:

4.4 rfind
查詢固定字符串在目標字符串中的最大索引。
若需要查詢的字符串未出現在目標字符串中,則顯示為-1。
s = pd.Series(['appoint', 'price', 'sleep','amount'])
s.str.rfind('p',start=1)
查詢結果如下:

4.5 findall
查找系列/索引中所有出現的模式或正則表達式
s = pd.Series(['appoint', 'price', 'sleep','amount']) s.str.findall(r'[ac]')
顯示結果如下:

4.6 get
從列表、元組或字符串中的每個元素中提取元素的系列/索引。
s = pd.Series(["String",
(1, 2, 3),
["a", "b", "c"],
123,
-456,
{1: "Hello", "2": "World"}])
s.str.get(1)
效果如下圖:

4.7 match
確定每個字符串是否與參數中的正則表達式匹配。
s = pd.Series(['appoint', 'price', 'sleep','amount'])
s.str.match('^[ap].*t')
匹配效果圖如下:

5.字符串邏輯判斷
5.1 contains函數
測試模式或正則表達式是否包含在系列或索引的字符串中。
參數:
pat,字符串或正則表達式;
case,是否區分大小寫,默認為True,即區分大小寫;
flags,是否傳遞到re模塊,默認為0;
na,對缺失值的處理方法,默認為nan;
regex,是否將pat參數當作正則表達式來處理,默認為True。
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.contains('ap',case=True,na=False,regex=False)
效果圖如下:

5.2 endswith函數
測試每個字符串元素的結尾是否與字符串匹配。
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.endswith('e')
匹配結果如下:

處理nan值
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.endswith('e',na=False)
效果如下:

5.3 startswith函數
測試每個字符串元素的開頭是否與字符串匹配。
s = pd.Series(['APpoint', 'Price', 'cap','approve',123])
s.str.startswith('a',na=False)
匹配如下:

5.4 isalnum函數
檢查每個字符串中的所有字符是否都是字母數字。
s1 = pd.Series(['one', 'one1', '1', '']) s1.str.isalnum()
效果如下:

5.5 isalpha函數
檢查每個字符串中的所有字符是否都是字母。
s1 = pd.Series(['one', 'one1', '1', '']) s1.str.isalpha()
效果如下:

5.6 isdecimal函數
檢查每個字符串中的所有字符是否都是十進制的。
s1 = pd.Series(['one', 'one1', '1','']) s1.str.isdecimal()
效果如下:

5.7 isdigit函數
檢查每個字符串中的所有字符是否都是數字。
s1 = pd.Series(['one', 'one1', '1','']) s1.str.isdigit()
效果如下:

5.8 islower函數
檢查每個字符串中的所有字符是否都是小寫。
s1 = pd.Series(['one', 'one1', '1','']) s1.str.islower()
效果如下:

5.9 isnumeric函數
檢查每個字符串中的所有字符是否都是數字。
s1 = pd.Series(['one', 'one1', '1','','3.6']) s1.str.isnumeric()
效果如下:

5.10 isspace函數
檢查每個字符串中的所有字符是否都是空格。
s1 = pd.Series([' one', '\t\r\n','1', '',' ']) s1.str.isspace()
效果如下:

5.11 istitle函數
檢查每個字符串中的所有字符是否都是標題形式的大小寫。
s1 = pd.Series(['leopard', 'Golden Eagle', 'SNAKE', '']) s1.str.istitle()
效果如下:

5.12 isupper函數
檢查每個字符串中的所有字符是否都是大寫。
s1 = pd.Series(['leopard', 'Golden Eagle', 'SNAKE', '']) s1.str.isupper()
效果如下:

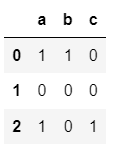
5.13 get_dummies函數
按 sep 拆分系列中的每個字符串並返回一個 虛擬/指標變量的dataframe。
s1 = pd.Series(['leopard', 'Golden Eagle', 'SNAKE', '']) s1.str.get_dummies()
效果如下:

該函數還可以進行此類匹配,註意輸入的形式
s1=pd.Series(['a|b', np.nan, 'a|c']) s1.str.get_dummies()
效果如下:
6.其他
6.1 strip
刪除前導和尾隨字符。
s1 = pd.Series(['1. Ant. ', '2. Bee!\n', '3. Cat?\t', np.nan]) s1.str.strip()
效果如下:

6.2 lstrip
刪除系列/索引中的前導字符。
6.3 rstrip
刪除系列/索引中的尾隨字符。
到此這篇關於pandas中對於文本類型數據的處理匯總的文章就介紹到這瞭,更多相關pandas文本類型數據處理內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 讓你一文弄懂Pandas文本數據處理
- Python學習之str 以及常用的命令
- Python字符串常用方法以及其應用場景詳解
- Python 字符串操作詳情
- Python Pandas數據處理高頻操作詳解