計算機程序設計並行計算概念及定義全面詳解
(本人剛剛完成這篇長文章的翻譯,尚未認真校對。若裡面有翻譯錯誤和打字錯誤敬請諒解,並請參考原貼)
1 摘要
帖子的原文: Introduction to Parallel Computing Tutorial
這篇帖子旨在為並行計算這一廣泛而宏大的話題提供一個非常快
速的概述,作為隨後教程的先導。因此,它隻涵蓋瞭並行計算的基礎知識,實用於剛剛開始熟悉該主題的初學者。我們並不會深入討論並行計算,因為這將花費大量的時間。本教程從對並行計算是什麼以及如何使用開始,討論與其相關的概念和術語,然後解析並行內存架構(parallel memory architecture)以及編程模型(programming models)等。這些主題之後是一系列關於設計和運行並行計算程序的復雜問題的實踐討論。最後,本教程給出瞭幾個並行化簡單串行程序的示例。
2 概述
2.1 什麼是並行計算?
串行計算: 傳統的軟件通常被設計成為串行計算模式,具有如下特點:
- 一個問題被分解成為一系列離散的指令;
- 這些指令被順次執行;
- 所有指令均在一個處理器上被執行;
- 在任何時刻,最多隻有一個指令能夠被執行。
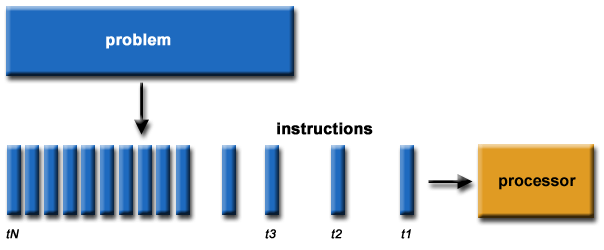
例如,

並行計算: 簡單來講,並行計算就是同時使用多個計算資源來解決一個計算問題:
一個問題被分解成為一系列可以並發執行的離散部分;
每個部分可以進一步被分解成為一系列離散指令;
來自每個部分的指令可以在不同的處理器上被同時執行;
需要一個總體的控制/協作機制來負責對不同部分的執行情況進行調度。

例如,

這裡的 計算問題 需要具有如下特點:
- 能夠被分解成為並發執行離散片段;
- 不同的離散片段能夠被在任意時刻執行;
- 采用多個計算資源的花費時間要小於采用單個計算資源所花費的時間。
這裡的 計算資源 通常包括:
- 具有多處理器/多核(multiple processors/cores)的計算機;
- 任意數量的被連接在一起的計算機。
並行計算機:
通常來講,從硬件的角度來講,當前所有的單機都可以被認為是並行的:
- 多功能單元(L1緩存,L2緩存,分支,預取,解碼,浮點數,圖形處理器,整數等)
- 多執行單元/內核
- 多硬件線程

IBM BG/Q Compute Chip with 18 cores (PU) and 16 L2 Cache units (L2)
通過網絡連接起來的多個單機也可以形成更大的並行計算機集群:
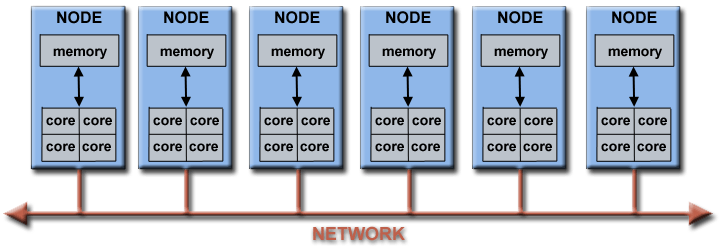
例如,下面的圖解就顯示瞭一個典型的LLNL並行計算機集群:
- 每個計算結點就是一個多處理器的並行計算機;
- 多個計算結點用無限寬帶網絡連接起來;
- 某些特殊的結點(通常也是多處理器單機)被用來執行特定的任務。
2.2 為什麼要並行計算?
真實世界就是高度並行的:
- 自然界中的萬事萬物都在並發的,按照其內在時間序列運行著;
- 和串行計算相比,並行計算更適用於對現實世界中的復雜現象進行建模,模擬和理解;
- 例如,可以想象對這些進行順序建模:

主要理由:
節約時間和成本:
1)理論上來講,在一個任務上投入更多的資源有利於縮短其完成時間,從而降低成本;
2)並行計算機可以由大量廉價的單機構成,從而節約成本。

解決更大規模更復雜的問題:
1)很多問題的規模和復雜度使得其難以在一個單機上面完成;
2)一個有趣的例子:(Grand Challenge Problems)。
3)網頁搜索引擎/數據庫每秒處理百萬級別的吞吐量。
提供並發性:
1)單個計算資源某個時間段隻能做一件事情,而多計算資源則可以同時做多件事情;
2)協同網絡可以使得來自世界不同地區的人同時虛擬地溝通。

利用非局部的資源:
1)可以利用更廣范圍中的網絡資源;
2)SETI@home的例子;
以及3)Folding@home的例子。

更好地利用並行硬件:
1)現代計算機甚至筆記本電腦在架構上都屬於多處理器/多核的;
2)並行軟件已經適用於多核的並行硬件條件,例如線程等;
3)在大多數情況下,運行在現代計算機上的串行程序實際上浪費瞭大量的計算資源。

並行計算的未來:
在過去的二十多年中,快速發展的網絡,分佈式系統以及多處理器計算機架構(甚至在桌面機級別上)表明並行化才是計算的未來;
在同一時期,超級計算機的性能已經有瞭至少50萬倍的增加,而且目前還沒有達到極限的跡象;
目前的峰值計算速度已經達到瞭10181018/秒

2.3 誰都在使用並行計算?
科學界和工程界:
從歷史上來講,並行計算就被認為是“計算的高端”,許多科學和工程領域的研究團隊在對很多領域的問題建模上都采用瞭並行計算這一模式,包括:大氣與地球環境、應用物理、生物科學、遺傳學、化學、分子科學、機械工程、電氣工程、計算機科學、數學、國防和武器研發等。

工業界和商業界:
如今,商業應用為更快速計算機的研發提供瞭更強勁的動力。這些商業應用程序需要以更復雜的方式處理大量數據,例如:大數據、數據庫、數據挖掘、石油勘探、網頁搜索引擎、基於web的商業服務、醫學成像和診斷、跨國公司管理、高級圖形學技術以及虛擬現實、網絡視頻和多媒體技術、協同工作環境等。

全球應用:
並行計算目前在實際上被廣泛采用於大量應用中

3 概念和術語
3.1 馮諾依曼體系結構
以匈牙利數學傢約翰·馮諾依曼命名的這一計算機體系結構,出現在他1945年發表的一篇論文中。這也通常被稱為“存儲程序計算機”——程序指令和數據都被保存在存儲器中,這與早期通過“硬接線”編程的計算機不同。從此以後,所有的計算機走遵從這一基本架構:
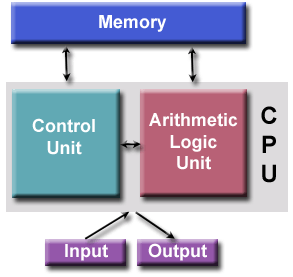

– 四個組成部分:1)內存;2)控制器;3)處理器;4)輸入輸出。
– 讀寫操作:支持隨機存儲的內存用來同時保存程序指令和數據:
1)程序指令用來指導計算機操作;
2)數據是程序用來操作的對象。
– 控制器:從內存中讀取指令或者數據,對這些指令進行解碼並且順序執行這些指令。
– 處理器:提供基本的算術和邏輯操作。
– 輸入輸出設備:是人機交互的接口。
那麼馮諾依曼體系結構和並行計算有什麼關系呢?答案是:並行計算機仍然遵從這一基本架構,隻是處理單元多於一個而已,其它的基本架構完全保持不變。
3.2 弗林的經典分類
有不同的方法對並行計算機進行分類(具體例子可參見並行計算分類)。
一種被廣泛采用的分類被稱為弗林經典分類,誕生於1966年。弗林分類法從指令流和數據流兩個維度區分多處理器計算機體系結構。每個維度有且僅有兩個狀態:單個或者多個。
下面個矩陣定義瞭弗林分類的四個可能狀態:
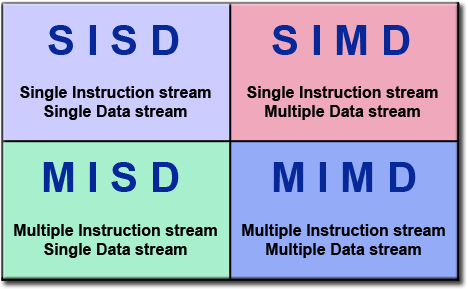
單指令單數據(SISD): SISD是標準意義上的串行機,具有如下特點:
1)單指令:在每一個時鐘周期內,CPU隻能執行一個指令流;
2)單數據:在每一個時鐘周期內,輸入設備隻能輸入一個數據流;
3)執行結果是確定的。這是最古老的一種計算機類型。

單指令多數據(SIMD): SIMD屬於一種類型的並行計算機,具有如下特點:
1)單指令:所有處理單元在任何一個時鐘周期內都執行同一條指令;
2)多數據:每個處理單元可以處理不同的數據元素;
3)非常適合於處理高度有序的任務,例如圖形/圖像處理;
4)同步(鎖步)及確定性執行;
5)兩個主要類型:處理器陣列和矢量管道。
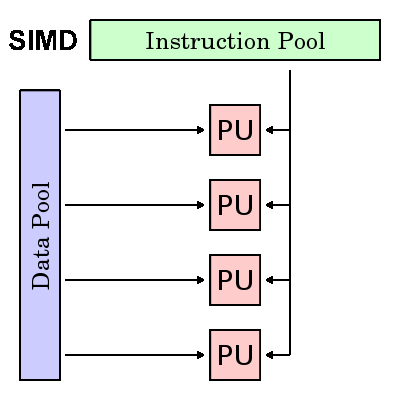

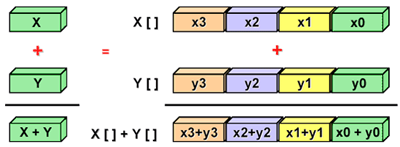
多指令單數據(MISD):MISD屬於一種類型的並行計算機,具有如下特點:
1)多指令:不同的處理單元可以獨立地執行不同的指令流;
2)單數據:不同的處理單元接收的是同一單數據流。這種架構理論上是有的,但是工業實踐中這種機型非常少。

多指令多數據(MIMD): MIMD屬於最常見的一種類型的並行計算機,具有如下特點:
1)多指令:不同的處理器可以在同一時刻處理不同的指令流;
2)多數據:不同的處理器可以在同一時刻處理不同的數據;
3)執行可以是同步的,也可以是異步的,可以是確定性的,也可以是不確定性的。這是目前主流的計算機架構類型,目前的超級計算機、並行計算機集群系統,網格,多處理器計算機,多核計算機等都屬於這種類型。
值得註意的是,許多MIMD類型的架構中實際也可能包括SIMD的子架構。
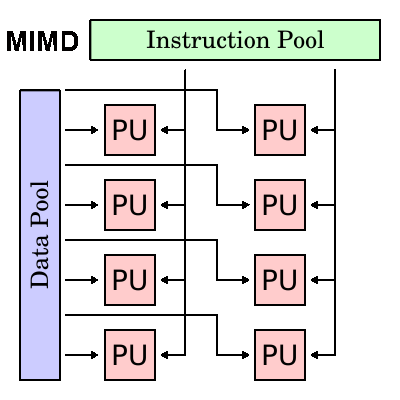
3.3 一些常見的並行計算術語
和其它一些領域一樣,並行計算也有自己的“術語”。下面列出瞭與並行計算相關聯的一些常用術語,其中大部分術語我們在後面還會進行更詳細的討論。
- 結點(Node):
也就是一個獨立的“計算機單元”。通常由多個CPU處理器/處理內核,內存,網絡接口等組成。結點聯網在一起以構成超級計算機。
- 中央處理器/套接字/處理器/核(CPU / Socket / Processor / Core):
這些術語也取決於我們討論的語境。在過去,中央處理器通常是計算機中的一個單個執行單元。之後多處理器被植入到一個結點中。接著處理器又被設計成為多核,每個核成為一個獨立的處理單元。具有多核的中央處理器有時候又被稱為“套接字”——實際上也沒有統一標準。所以目前來講,我們稱一個結點上具有多個中央處理器,每個中央處理器上又具有多個內核。

- 任務(Task):
任務通常是指一個邏輯上離散的計算工作部分。一個任務通常是一段程序或者一段類似於程序的指令集合,可以由一個處理器進行處理。一個並行程序通常由多個任務構成,並且可以運行在多個處理器上。
- 流水線(Pipelining):
可以將任務分解成為不同的步驟,並且由不同的處理單元完成,裡面有輸入流通過。這非常類似於一個裝配線,屬於一種類型的並行計算。
- 共享內存(Shared Memory):
從嚴格的硬件角度來講,共享內存描述瞭一種計算機架構,其中所有的處理器都可以對共同的物理內存進行直接存取(通常是通過總線)。從編程的角度來講,共享內存描述瞭一種模型,其中所有的並行任務都具有同一內存形態,並且都可以直接對同一內存區域進行直接定位和存取,而無論該物理內存實際上在哪裡(也許在千裡之外的另外一個計算機上?)。
- 對稱多處理器(Symmetric Multi-Processor (SMP)):
屬於一種共享內存的硬件架構,並且不同的處理器對內存以及其它資源都具有同等的訪問權限(個人理解,就是不同處理器在角色上沒有任何區別)。
- 分佈式內存(Distributed Memory):
在硬件中,表示基於網絡的內存存取方式;在編程模型中,表示任務僅僅能夠從邏輯上“看到”本機上的內存,但是在其它任務執行的時候,必須通過通訊才能對其它任務所運行的機器上的內存進行存取。
- 通訊(communications):
並行任務通常需要數據交換。實現數據交換的方式有多種,例如通過共享內存或者通過網絡。但是通常意義上,數據交換指的就是通訊,而無論其實現方式。
- 同步(Synchronization):
指的是並行任務之間的實時協調,通常伴隨著通訊(communication)。同步通常由在程序中設立同步點來實現,也就是說,在其它任務沒有執行到這一同步點的時候,某一任務不能進一步執行後面的指令。同步通常涉及到需要等待其它任務的完成,因此有時候會增加並行程序的執行時間。
- 粒度(Granularity):
在並行計算中,粒度定量地描述瞭計算與通訊的比率。粗粒度表示在通訊過程中需要做大量的計算性工作;細粒度則表示在通訊過程中需要做的計算性工作並不多。
- 加速比(Observed Speedup):
這是檢測並行計算性能的最簡單並且最被廣泛使用的度量策略,其定義如下:串行計算的時鐘周期數並行計算的時鐘周期數串行計算的時鐘周期數並行計算的時鐘周期數。
- 並行開銷(Parallel Overhead):
指的是相對於做實際計算,做協調並行任務所需要花費的時間總數。影響並行開銷的因素主要包括:
1)任務啟動時間;
2)同步;
3)數據通訊;
4)由並行語言,鏈接庫,操作系統等因素而導致的軟件開銷;
5)任務終止時間。
- 大規模並行(Massive Parallel):
指那些包含並行系統的硬件——擁有很多的處理元件。這裡的“很多”可能會隨著硬件條件的進步而不斷增加,但目前,最大的並行系統所擁有的處理元件高達上百萬件。
- 尷尬並行(Embarrassingly Parallel):
指的是同時解決很多類似而又獨立的任務,其中任務之間幾乎沒有需要協調的地方。
- 可擴展性(Scalability):
指的是並行系統(包括軟件和硬件)通過添加更多資源來成比例增加並行速度的能力。影響可擴展性的因素主要包括:
1)硬件,尤其是內存-處理器帶寬以及網絡通訊的質量和速度;
2)應用算法;
3)相對並行開銷;
4)具體應用的特征。
3.4 並行程序的缺陷和代價
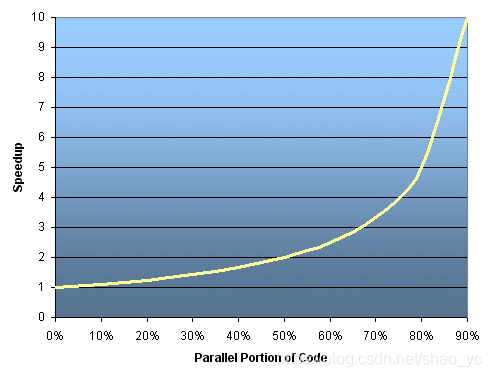
阿姆達爾定律: 阿姆達爾定律說一個程序的加速比潛力由其可以並行的部分所占的比例而決定,即:
speedup=11−Pspeedup=11−P.
如果沒有代碼可以被並行,那麼p = 0,所以加速比為1。如果所有的代碼都可以被並行,那麼 p = 1,加速比為無窮大(當然隻是理論上而言)。如果50%的代碼可以被並行,那麼最大的加速比為2,意味著的運行速度最快可以被加速到2倍。
如果引入並行程序中的處理器個數,則加速比可以被重新定義為:
speedup=1PN+S=11−P+PNspeedup=1PN+S=11−P+PN,
其中P仍然是並行代碼所占的比例,N是處理器個數,S是串行代碼所占比例(S = 1 – P)。

| N | P = 0.50 | p = 0.90 | p = 0.95 | p = 0.99 |
|---|---|---|---|---|
| 10 | 1.82 | 5.26 | 6.89 | 9.17 |
| 100 | 1.98 | 9.17 | 16.80 | 50.25 |
| 1000 | 1.99 | 9.91 | 19.62 | 90.99 |
| 10000 | 1.99 | 9.91 | 19.96 | 99。02 |
| 100000 | 1.99 | 9.99 | 19.99 | 99.90 |
之後我們就迅速意識到並行計算的極限所在,例如上表所示。
“註明引言:”你可以花費一生的時間使得你的代碼的95%都可以被並行,然而你如論投入多少處理器,都不會獲得20倍的加速比。
然而,某些問題我們可以通過增加問題的大小來提高其性能。例如:
| 類型 | 時間 | 比例 |
|---|---|---|
| 2D網格計算 | 85秒 | 85% |
| 串行比例 | 15秒 | 15% |
我們可以增加網格的維度,並且將時間步長減半。其結果是四倍的網格點數量,以及兩倍的時間步長。之後的花費時間將變為:
| 類型 | 時間 | 比例 |
|---|---|---|
| 2D網格計算 | 680秒 | 97.84% |
| 串行比例 | 15秒 | 2.16% |
復雜性:
通常而言,並行計算的程序要比相應的串行計算程序更加復雜,也許復雜一個量級。你不僅需要同時執行不同的指令流,而且需要註意他們之間數據的通信。復雜性通常由涉及軟件開發周期各個方面的時間來確定,主要包括:
1)設計;2)編碼;3)調試;4)調參;5)維護。
遵循良好的軟件開發實踐對並行應用開發是至關重要的,尤其是在除你之外的其他人還需要和你合作的情況下。
可移植性:
由於一些API的標準化,例如MPI,POSIX線程以及OpenMP,並行程序的可移植性問題並不像過去那麼嚴重,然而:
- 所有串行程序中所遇到的可移植性問題都會出現在相應的並行程序中。
- 盡管一些API已經被標準話,但是在一些細節的實現上任然有差異,有時候這些細節實現會影響到可移植性。
- 操作系統也會是導致可移植性的關鍵因素。
- 硬件架構的不同有時候也會影響到可移植性。
資源需求:
並行編程的主要目標就是降低時鐘等待時間。然而要做到這一點,需要更多的CPU時間。例如,一個在8個處理器上跑瞭一個小時的並行程序實際上花費瞭8小時的CPU時間。
並行程序所需要的內存開銷往往要大於相對應的串行程序,這是因為我們有時候需要復制數據,以滿足庫和子系統對並行算法的要求。
對於運行時間較短的並行陳顧,實際性能反而有可能比相對應的串行程序有所降低。這是由於並行環境的建立,任務創建,通訊,任務結束等在這個運行時間中有可能會占有比較大的比例。
可擴展性:
基於時間和解決方案的不同,可以將擴展性分為強可擴展性和弱可擴展性:
強可擴展性的特點是:
1)在更多處理器被加入的時候,問題本身的規模不會增加;
2)目標是將同一問題運行的更快;
3)理想狀態下,相比於對應的串行程序,運行時間為1/P。
弱可擴展性的特點是:
1)隨著更多處理器被加入,每個處理上需要處理的問題規模保持一致;
2)目標是在相同的時間內解決更多規模的問題;
3)理想狀態下,在相同時間內,可以解決的問題規模增加為原問題規模的P倍。
並行程序的性能提高取決於一系列相互依賴的因素,簡單地增加更多的處理器並不一定是唯一的方法。
此外,某些問題可能本身存在擴展性的極限,因此添加更多的資源有時候反而會降低性能。這種情形會出現在很多並行程序中。
硬件在可擴展性方面也扮演者重要角色,例如:1)內存-CPU之間的帶寬;2)通訊網絡的帶寬;3)某個機器或者某個機器集合中的內存大小;4)時鐘處理速度。
支持並行的庫或者子系統同樣也會限制並行程序的可擴展性。

4 並行計算機的內存架構
4.1 共享內存
一般特征:
共享內存的並行計算機雖然也分很多種,但是通常而言,它們都可以讓所有處理器以全局尋址的方式訪問所有的內存空間。多個處理器可以獨立地操作,但是它們共享同一片內存。一個處理器對內存地址的改變對其它處理器來說是可見的。根據內存訪問時間,可以將已有的共享內存機器分為統一內存存取和非統一內存存取兩種類型。
統一內存存取(Uniform Memory Access):
目前更多地被稱為對稱多處理器機器(Symmetric Multiprocessor (SMP)),每個處理器都是相同的,並且其對內存的存取和存取之間都是無差別的。有時候也會被稱為CC-UMA (Cache coherent – UMA)。緩存想幹意味著如果一個處理器更新共享內存中的位置,則所有其它處理器都會瞭解該更新。緩存一致性是在硬件級別上實現的。
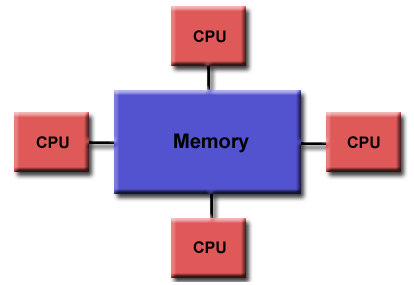
非統一內存存取(Non-Uniform Memory Access):
通常由兩個或者多個物理上相連的SMP。一個SMP可以存取其它SMP上的內存。不是所有處理器對所有內存都具有相同的存取或者存取時間。通過連接而進行內存存取速度會更慢一些。如果緩存相緩存想幹的特性在這裡仍然被保持,那麼也可以被稱為CC-NUMA。

優點:
全局地址空間提供瞭一種用戶友好的編程方式,並且由於內存與CPU的階級程度,使得任務之間的數據共享既快速又統一。
缺點:
最大的缺點是內存和CPU之間缺少較好的可擴展性。增加更多的CPU意味著更加共享內存和緩存想幹系統上的存取流量,從而幾何級別地增加緩存/內存管理的工作量。同時也增加瞭程序員的責任,因為他需要確保全局內存“正確”的訪問以及同步。
4.2 分佈式內存
一般概念: 分佈式內存架構也可以分為很多種,但是它們仍然有一些共同特征。分佈式內存結構需要通訊網絡,將不同的內存連接起來。一般而言,處理器會有它們所對應的內存。一個處理器所對應的內存地址不會映射到其它處理器上,所以在這種分佈式內存架構中,不存在各個處理器所共享的全局內存地址。
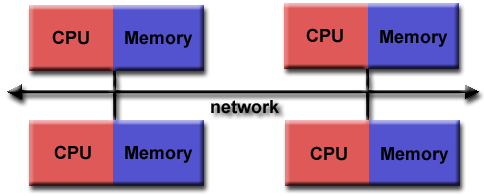
由於每個處理器具有它所對應的局部內存,所以它們可以獨立進行操作。一個本地內存上所發生的變化並不會被其它處理器所知曉。因此,緩存想幹的概念在分佈式內存架構中並不存在。
如果一個處理器需要對其它處理器上的數據進行存取,那麼往往程序員需要明確地定義數據通訊的時間和方式,任務之間的同步因此就成為程序員的職責。盡管分佈式內存架構中用於數據傳輸的網絡結構可以像以太網一樣簡單,但在實踐中它們的變化往往也很大。
優點:
1)內存可以隨著處理器的數量而擴展,增加處理器的數量的同時,內存的大小也在成比例地增加;
2)每個處理器可以快速地訪問自己的內存而不會受到幹擾,並且沒有維護全局告訴緩存一致性所帶來的開銷;
3)成本效益:可以使用現有的處理器和網絡。
缺點:
1)程序員需要負責處理器之間數據通訊相關的許多細節;
2)將基於全局內存的現有數據結構映射到該分佈式內存組織可能會存在困難;
3)非均勻的內存訪問時間——駐留在遠程結點上的數據比本地結點上的數據需要長的多的訪問時間。
4.3 混合分佈式-共享內存
一般概念: 目前世界上最大和最快的並行計算機往往同時具有分佈式和共享式的內存架構。共享式內存架構可以是共線內存機器或者圖形處理單元(GPU)。分佈式內存組件可以是由多個共享內存/GPU連接而成的系統。每個結點隻知道自己的內存,不知道網絡上其它結點的內存。因此,需要在不同的機器上通過網絡進行數據通訊。
從目前的趨勢來看,這種混合式的內存架構將長期占有主導地位,並且成為高端計算在可見的未來中的最好選擇。
優缺點:
1)繼承瞭共享式內存和分佈式內存的優缺點;
2)優點之一是可擴展性;
3)缺點之一是編程的復雜性。
5. 並行計算模型
5.1 概述
常見的並行編程模型包括:共享內存模型(無線程),線程模型,分佈式內存/消息傳遞模型,數據並行模型,混合模型,單程序多數據模型,多程序多數據模型。
並行計算模型是作為硬件和內存架構之上的一種抽象存在。雖然不一定顯而易見,但這些模型並不和特定的機器和內存架構有關。事實上,任何一個並行計算模型從理論上來講都可以實現在任何一種硬件上。下面是兩個例子。
在分佈式內存架構上的共享內存模型
機器內存分佈於網絡上的不同結點,但是對於用戶而言,看到的確實一個具有全局地址空間的共享內存。這種方法通常被稱為“虛擬共享存儲器”。

在共享內存架構上的分佈式內存模型
最主要的是消息傳遞接口(MPI)。每個任務都可以直接訪問跨所有機器的全局地址空間。然而,它們之間數據交換卻是通過消息傳遞機制實現的,就像在分佈式內存網絡中所進行的那樣。

那麼到底使用哪一種呢?這往往取決於現有條件以及用戶的偏好。沒有最好的模型,但對模型的實現質量卻可能存在差別。下面我們將分別描述上面提到的各種並行計算模型,並且討論它們在實踐中的一些實現方式。
5.2 共享內存模型(無線程)
在這種並行計算模型中,處理器/任務共享內存空間,並且可以異步地對內存進行讀寫。很多機制被用來控制對內存的存取,例如鎖/信號量等,用來解決訪問沖突以及避免死鎖。這應該是最簡單的並行計算模型瞭。
從編程者的角度來看,這種模型的好處之一數據“擁有者”的缺失,所以他們不必明確地指定數據之間的通訊。所有的處理器都可以看到和平等地存取共享內存。程序開發將因此而變得容易。
性能方面的一個重要缺點是對數據局部性的理解和管理講變得困難:1)保持數據的局部性將有利於減少內存的存取負擔,緩存刷新次數以及總線流量。而當多個處理器使用同一數據時,這些負擔將會經常發生;2)不幸的是,保持數據的局部性往往比較難以理解,並且其難度超過一般用戶的水平。
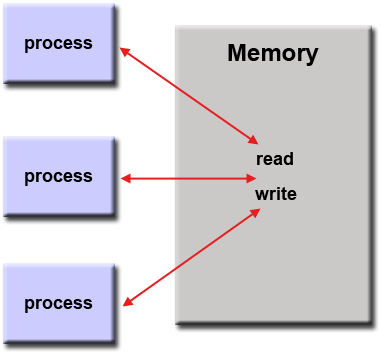
實現: 單機共享內存機器,本地操作系統,編譯器及其對應的硬件都支持共享內存編程。在分佈式內存機器上,內存在物理上存在於網絡上不同的結點上,但是可以通過特殊的硬件和軟件,將其變為全局可見。
5.3 線程模型
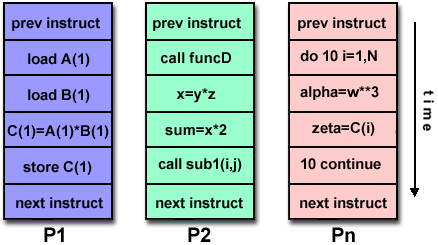
這是共享內存編程的一種模式。在線程模型中,一個單個的“重量級”進程可以擁有多個“輕量級”的並發執行路徑。例如下圖所示:
- 主程序 a.out 在本地操作系統上運行。a.out 需要加載所有的系統和用戶資源來運行,這是裡面的“重量級”進程。a.out 首先執行一些串行工作,然後生成一系列任務(線程),而這些線程可以在操作系統中被並發地執行。
- 每個線程具有本地數據,但同時也共享 a.out 的所有資源。這節約瞭所有線程都復制程序資源的的開銷。而每個線程同時也從全局內存中獲益,因為它可以共享 a.out 的內存空間。
- 一個線程的工作可以被描述為主程序的一個子程序。任何線程都可以在其它線程運行的同時執行任何子程序。
- 線程之間的通訊通過全局內存來實現(對全局地址的更新)。這需要建立一種同步機制,以保證在同一時刻,不會有多個線程對同一塊地址空間進行更新。
- 線程可以隨時生成和結束,但是 a.out 卻一直存在,以提供所需的共享資源,直到整個應用程序結束。

實現: 從編程的角度來講,線程的實現通常包括如下兩個方面:
- 庫函數或者子程序,這些庫函數或者子程序可以在並行源代碼中被調用;
- 嵌入在並行或者串行源代碼中的一組編譯器指令集合。
程序員需要同時定義上面的兩個方面(盡管有時候編譯器可以提供幫助)。
線程並不是一個新概念。之前硬件供應商就曾經實現過他們自己的線程。由於這些線程的實現各不相同,所以使得程序員很難開發可移植的多線程應用程序。
而標準化工作卻導致瞭兩種完全不同的線程實現方式:POSIX Threads 和 OpenMP。
POSIX Threads:
由IEEE POSIX 1003.1c standard (1995)定義,僅支持C語言,是Unix/Linux操作系統的一部分,是基於庫函數的,也通常被稱為“Pthreads”。是非常明確的並行機制,需要程序員註意大量的細節。更多信息可見:POSIX Threads tutorial。
OpenMP:
是一個工業標準,有一組主要計算機硬件和軟件提供商,組織和個人聯合發起和定義,是基於編譯器指令的,具有可移植性/跨平臺性,目前支持的包括Unix和Windows平臺,目前支持C/C++和Fortran語言。非常簡單和醫用,提供瞭“增量並行”,可以從串行代碼開始。更多信息可見:OpenMP tutorial。
也有一些其它的常見線程實現,但是在這裡沒有討論,包括:
Microsoft threads
Java, Python threads
CUDA threads for GPUs
5.4 分佈式內存/消息傳遞模型
這種模型具有如下特點:
- 在計算的過程中,每個任務都僅僅使用它們自身的本地內存。多個任務既可以寄宿在同一個物理機器上,也可以跨越不同的物理機器。
- 任務之間的數據交換是通過發送和接收消息而實現的。
- 數據傳輸通常需要不同進程之間的協同操作才能實現。例如,一個發送操作需要同時對應一個接收操作。

實現: 從編程的角度來講,消息傳遞的實現通常包括子程序庫。對這些子程序的調用往往就嵌入在源代碼中。編程者負責並行機制的實現。
自從1980年代以來,出現瞭多種消息傳遞庫函數。這些實現各不相同,導致編程者很難開發出移植性好的應用程序。自從1992年開始,MPI Forum形成,其主要目標是建立消息傳遞的標準接口。消息傳遞接口(Message Passing Interface (MPI))的第一部分在1994年發佈,第二部分在1996年發佈,第三部分在2012年發佈。所有的MPI說明可以參見 MPI Documents
。MPI成為瞭事實上的消息傳遞的工業標準,取代瞭所有其它消息傳遞的實現。幾乎所有流行的並行計算平臺都存在MPI的實現,但並不是所有的實現都包含瞭MPI-1,MPI-2和MPI-3的所有內容。關於MPI的更多信息可以參見 MPI tutorial。
5.5 數據並行模型
通常也被稱為“全局地址空間分區”(Partitioned Global Address Space (PGAS))模型。具有如下特點:
- 地址空間被認為是全局的。
- 大多數的並行工作聚焦於在數據集上的操作。數據集通常被組織成為常用的結構,例如數組,數立方等。
- 一系列任務在同一塊數據結構上操作,但是每個任務卻操作在該數據結構的不同分區上。
- 每個任務在數據結構的不同分區上執行相同的操作,例如,“給每個數組元素加上4”。

在共享內存的架構下,所有的任務通過全局內存方式來對數據進行存取;在分佈式內存架構下,根據任務分配,全局數據結構在物理或者邏輯上被進行分割。
實現: 目前,基於數據並行/PGAS模型,有如下幾個相對有名的實現:
Coarray Fortran: 為瞭支持SPMD並行編程而在Fortran 95上做的一個小的擴展,是編譯器相關的,更多信息可以參見: Coarray_Fortran
Unified Parallel C (UPC): 為瞭支持SPMD並行編程而在C語言基礎上做的擴展,也是編譯器相關的,更多信息可以參見: The UPC Language
5.6 混合模型
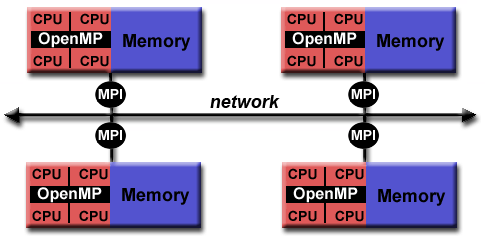
混合模型指的是包含瞭至少兩個我們前面提到的並行計算模型的模型。目前,最常見的混合模型的例子是消息傳遞模型(MPI)和線程模型(OpenMP)的結合:
- 線程使用本地數據完成計算密集型的任務;
- 不同的進程則在不同的結點上通過MPI完成數據通訊。
這種混合模型非常適合目前流行的硬件環境——多核計算機組成的集群系統。
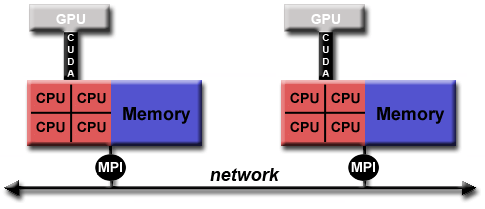
另外一種類似的,但原來越流行的例子是采用MPI和CPU-GPU的混合編程:
- 采用MPI的任務運行於CPU上,使用本地內存上的數據,但是通過網絡與其它任務進行數據交換;
- 而計算密集型的核則被加載到GPU上進行計算;
- 而結點內部的內存和GPU上的數據交換則通過CUDA(或者類似的東西)進行數據交換。
其它混合模型還包括:
- MPI和Pthreads的混合;
- MPI和non-GPU加速器的混合。
- …
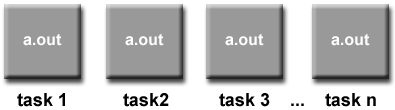
5.7 單程序多數據模型(SPMD)和多程序多數據模型(MPMD)
單程序多數據模型(Single Program Multiple Data (SPMD)):
SPMD事實上是一種可以架構在其它並行編程模型之上的更“高級”的編程模型:
- 單程序:所有任務都執行同一個程序的拷貝,而這裡的程序可以是線程,消息傳遞,數據並行甚至混合;
- 多數據:不同的任務操作於不同的數據。
SMPD通常需要指定任務的執行邏輯,也就是不同的任務可能會根據分支和邏輯關系,去執行整個程序的某個部分,也就是說,不是所有的任務都必須執行整個程序——有可能隻是整個程序的某個部分。(譯者註:如果不強調這一點,SPMD就退化成瞭數據並行模型瞭。)
而這種采用消息消息傳遞或者混合編程的SPMD模型,有可能是今天運行在多核集群系統上的最常見的並行計算模型瞭。
多程序多數據模型(Multiple Program Multiple Data (MPMD)):
和SPMD一樣,多程序多數據模型實際上也是一種可以架構在其它並行編程模型基礎上的“高級”並行編程模型:
- 多程序:任務可以同時執行不同的程序,這裡的程序可以是線程,消息傳遞,數據並行或者它們的混合。
- 多數據:所有的任務可以使用不同的數據。
MPMD應用並不像SPMD應用那麼常見,但是它可能更適合於特定類型的程序。

6 並行程序設計
6.1 自動 vs. 手動並行化
設計和實現並行程序是一個非常手動的過程,程序員通常需要負責識別和實現並行化,而通常手動開發並行程序是一個耗時,復雜,易於出錯並且迭代的過程。很多年來,很多工具被開發出來,用以協助程序員將串行程序轉化為並行程序,而最常見的工具就是可以自動並行化串行程序的並行編譯器(parallelizing compiler)或者預處理器 (pre-processor)。
並行編譯器通常以如下兩種方式工作:
完全自動:
由編譯器分析源代碼並且識別可以並行化的部分,這裡的分析包括識別出哪些部分滿足並行化的條件,以及權衡並行化是否真的可以提高性能。循環(包括do, for)通常是最容易被並行化的部分。
程序員指令:
通過采用“編譯器指令”或者編譯器標識,程序員明確地告訴編譯器如何並行化代碼,而這可能會和某些自動化的並行過程結合起來使用。
最常見的由編譯器生成的並行化程序是通過使用結點內部的共享內存和線程實現的(例如OpenMP)。
如果你已經有瞭串行的程序,並且有時間和預算方面的限制,那麼自動並行化也許是一個好的選擇,但是有幾個重要的註意事項:1)可能會產生錯誤的結果;2)性能實際上可能會降低;3)可能不如手動並行那麼靈活;4)隻局限於代碼的某個子集(通常是循環);5)可能實際上無法真正並行化,由於編譯器發現裡面有依賴或者代碼過於復雜。
接下來的部分僅適用於手動開發並行程序。
6.2 理解問題和程序
毫無疑問,開發並行程序的第一步就是理解你將要通過並行化來解決的問題。如果你是從一個已有的串行程序開始的,那麼你需要首先理解這個串行程序。
在開始嘗試開發並行解決方案之前,需要確定該問題是否真正可以被並行化。
- 一個容易被並行化的問題如下。該問題容易被並行化,因為每個分子構象都是獨立且確定的。計算最小能量構象也是一個可以被並行化的問題。
計算數千個獨立分子構象中每一個的勢能,完成之後,找出能量構象最小的那一個。
- 一個不太可能被並行化的問題如下。由於F(n)同時依賴於F(n-1)和F(n-2),而後者需要提前被計算出來。
采用如下公式計算菲波那切數列 (0,1,1,2,3,5,8,13,21,…):F(n) = F(n-1) + F(n-2)。
識別程序的關鍵點 (hotspots):
瞭解哪個部分完成瞭程序的大多數工作。大多數的科學和技術程序中,大多數的工作都是在某些小片段中完成的。可以通過剖析器或者性能分析工具來幫助你分析。專註於程序中這些關鍵點,忽略那些占用少量CPU的其餘部分。
識別程序中的瓶頸 (bottlenecks):
- 有沒有導致程序不成比例地變慢的,或者導致並行程序停止或者延遲的部分?例如有時候輸入輸出操作會導致程序變慢。
- 有時候也可能通過重構程序,或者采用不同的算法來降低或者消除這些執行很慢的區域。
識別並行化的抑制因素。一個常見的類型是數據依賴性 (data dependence),例如上面提到的菲波那切數列的例子。
如果可能的話,研究其它算法。這可能是設計並行程序的過程中最重要的一點。
利用成熟的第三方並行軟件,或者高度成熟的數學庫(例如IBM的ESSL,Intel的MKL,AMD的AMCL等)。

6.3 分割 (Partitioning)
設計並行程序的第一步就是將程序分解成為可以分配到不同任務中去的“塊”。這被稱為程序的分解 (decomposition) 或者分割 (partitioning)。通常有兩種基本方法可以將並行任務進行分解:域分解和功能分解。
域分解: 在這種分割方式中,將數根據問題進行分解。每個並行任務操作數據的一部分。
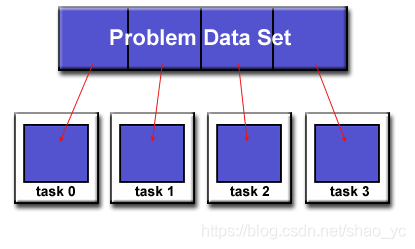
通常由不同的方式來對數據進行分割:

功能分解:
在這種方法中,重點在於要執行的計算,而不是計算所操縱的數據。問題根據要做的工作進行分解,然後每個任務執行整個工作的一部分。

這種功能分解非常適合於可分為不同任務的問題,例如:
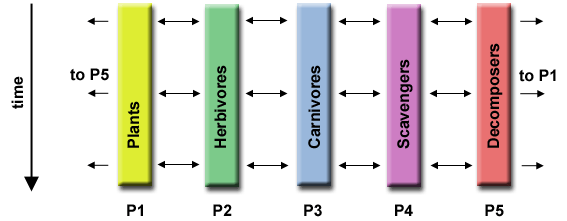
生態系統建模:
每個程序計算給定組的人口,其中每個組的正常取決於其鄰居的增長。鎖著時間的推移,每個進程計算當前狀態,然後與相鄰群體交換信息。然後所有任務進行下一步計算。
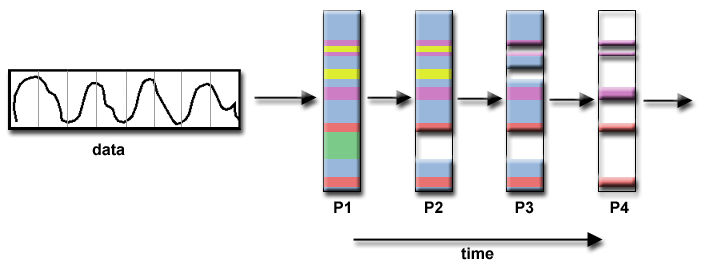
信號處理:
音頻信號數據集通過四個不同的計算濾波器,每個濾波器是一個單獨的過程。第一段數據必須通過第一個濾波器,然後才能進入第二個濾波器。當這樣做時,第二段數據通過瞭第一個濾波器。當第四個數據段處於第一個濾波器時(以及之後),四個任務都會變得很忙。
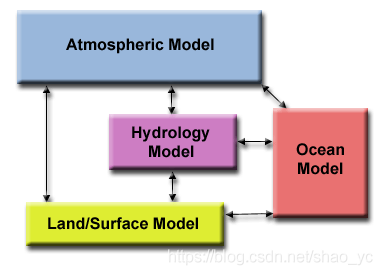
氣候建模:
每個模型組件都可以被認為是一個單獨的任務。箭頭表示計算期間組件之間的數據交換:大氣模型需要使用風速數據生成海洋模型;海洋模型使用海面溫度數據生成大氣模型等。
在實踐中將這兩種分解方式結合起來是很自然的,也是很常見的。
6.4 通訊 (Communications)
任務之間的通訊需求取決於你的問題:
不需要通訊的情況:
一些程序可以被分解成為並發執行的任務,而這些任務之間不需要共享數據。這類問題往往被稱為“尷尬並行”——任務之間不需要數據通訊。例如如果我們需要對下面一副圖片的顏色進行取反(黑色的部分變為白色的,白色的變為黑色的),那麼圖像數據可以被簡單地分解為多個任務,並且每個任務可以被獨立地執行。

需要通訊的情況:
大多數並行程序並不像上一問題這麼簡單,任務之間確實需要共享數據。例如下面這幅熱度擴散圖需要一個任務知道其它任務在它的鄰居方格中的計算結果。鄰居數據的變化將直接影響到該任務的數據。

設計通訊需要考慮的因素: 在設計程序任務之間的通訊時,有大量的重要因素需要考慮:
通訊開銷:
1)任務間通訊幾乎總是意味著開銷。
2)而可以用於計算的機器周期以及資源會轉而用於對數據的封裝和傳輸。
3)頻繁的通訊也需要任務之間的同步,這有可能會導致任務花費時間等待而不是執行。
4)競爭通訊流量可能使可用的網絡帶寬飽和,從而進一步加劇性能問題。
延遲 vs. 帶寬:
1)延遲 指的是從A點到B點發送最小量的信息所需要花費的時間,通常以毫秒計。
2)帶寬 指的是單位時間內可以傳輸的數據總量,通常以M/S或者G/S來計。
3)發送大量的短消息可能會導致延遲成為通訊的主要開銷。通常情況下將大量小信息封裝成為大消息會更加有效,從而提高通訊帶寬的利用效率。
通訊可見性:
1)在消息傳遞模型中,通訊往往是顯式和可見的,並且在編程者的控制之下。
2)在數據並行模型中,通訊對編程者來說往往是透明的,尤其是在分佈式內存架構中。編程者往往甚至不能明確知道任務之間的通訊是如何完成的。
同步 vs. 異步通訊:
1) 同步通訊需要共享數據的任務之間某種意義上的“握手”。這既可以由編程者顯式地指定,也可以在底層被隱式地實現而不為編程者所知。
2)同步通訊業常常被稱為“阻塞通訊”,因為一些任務必須等待直到它們和其它任務之間的通訊完成。
3)異步通訊允許任務之間獨立地傳輸數據。例如任務1可以準備並且發送消息給任務2然後立即開始做其它工作,它並不關心任務2什麼時候真正受到數據。
4)異步通訊也常常被稱為“非阻塞通訊”,因為在通訊發生的過程中,任務還可以完成其它工作。
5)在計算和通訊自由轉換是異步通訊的最大優勢所在。
通訊的范圍:
明確哪些任務之間需要通訊在設計並行代碼的過程中是非常關鍵的。下面兩種通訊范圍既可以被設計為同步的,也可以被設計為異步的:
1)點對點通訊: 涉及到兩個任務,其中一個扮演消息發送者/生產者的角色,另外一個扮演消息接受者/消費者的角色。
2)廣播通訊: 涉及到多於兩個任務之間的數據共享。這些任務通常處於一個組或者集合中。

通訊的效率:
通常編程者具有影響通訊性能的選擇,這裡列舉其中一些:1)對於一個給定的模型,究竟應該采用哪一種實現?例如對於消息傳遞模型而言,一種MPI的實現可能在某個給定的硬件下比其它實現要快。2)什麼采用什麼類型的通訊操作?正如前面所提到的,異步通訊操作往往可以提高程序的整體性能。3)網絡結構(network fabric):某些平臺可能會提供多於一個的網絡結構。那麼究竟哪一個最好?
開銷和復雜性:

最後需要意識到,上面提到的僅僅是需要註意的問題的一部分!
6.5 同步 (Synchronization)
管理工作的順序和執行它的任務是大多數並行程序設計的關鍵,它也可能是提升程序性能的關鍵,通常也需要對某些程序進行“串行化”。

同步的類型:
屏障:
1)這通常意味著會涉及到所有任務;
2)每個任務都執行自身的工作,直到它遇到屏障,然後它們就停止,或者“阻塞”;
3)當最後一個任務到達屏障時,所有任務得以同步;
4)接下來可能發生的事情就有所變化瞭。通常會執行一段串行代碼,或者所有的任務在這裡都結束瞭。
鎖/信號量:
1)可以涉及任意多個任務;
2)通常用於對全局數據或者某段代碼的存取串行化(保護),在任一時刻,隻有一個任務可以使用鎖/信號量;
3)第一個任務會獲得一個鎖,然後該任務就可以安全地對該保護數據進行存取;
4)其它任務可以嘗試去獲得鎖,但必須等到當前擁有該鎖的任務釋放鎖才行;
5)可以是阻塞的也可以是非阻塞的。
同步通訊操作:
1)僅僅涉及到執行數據通訊操作的任務;
2)當一個任務執行數據通訊操作時,通常需要在參與通訊的任務之間建立某種協調機制。例如,在一個任務發送消息時,它必須收到接受任務的確認,以明確當前是可以發送消息的;
3)在消息通訊一節中也已經說明。
6.6 數據依賴性 (Data Dependencies)
定義:
- 依賴: 當語句的執行順序影響程序的運行結果時,我們稱程序語句之間存在依賴關系。
- 數據依賴: 數據依賴是由不同任務多次存取相同的內存位置而產生的。
數據依賴也是並行程序設計中的關鍵,因為它是並行化中一個重要的抑制因素。

例子:
循環相關的數據依賴:下面這段代碼中,A(J-1) 必須在A(J) 之前被計算出來,因此說A(J) 與 A(J-1) 之間存在數據依賴,所以並行化在這裡被抑制。如果任務2中有A(J),任務1中有A(J-1),那麼要計算出正確的A(J) 則需要:1)分佈式內存架構:任務2必須在任務1計算結束之後,從任務1處中獲取A(J-1) 的值。2)共享內存架構:任務2在任務1完成對A(J-1) 的更新之後,對A(J-1) 進行讀取。
DO J = MYSTART,MYEND
A(J) = A(J-1) * 2.0
END DO
循環無關的數據依賴:在下面的例子中並行化也同樣被抑制。Y的值依賴於:1)分佈式內存架構: 在任務之間是否需要或者何時需要對X的值的通訊。2)共享內存架構: 哪個任務最後存儲X的值。
task 1 task 2
—— ——X = 2 X = 4
. .
. .
Y = X**2 Y = X**3
盡管在並行程序設計中,對所有數據依賴的識別都是重要的,但循環相關的數據依賴尤其重要,因為循環往往是最常見的可並行化部分。
處理方法:
1)分佈式內存架構:在同步點傳輸所需數據;
2)共享式內存結構:在任務之間同步讀寫操作。
6.7 負載均衡 (Load Balancing)
負載均衡是指在任務之間分配大約相等數量的工作的做法,以便所有任務在所有時間保持繁忙,它也可以被認為是使任務空閑時間最小化。出於性能原因方面的考慮,負載均衡對並行程序很重要。例如如果所有恩物都收到屏障同步點的影響,那麼最慢的任務將決定整體性能。
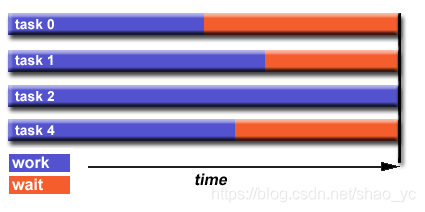

如何實現負載均衡:
- 平均分配任務量:
對於數組/矩陣而言,如果每個任務都執行相同或者類似的工作,那麼在任務之間平均分配數據集;2)對於循環迭代而言,如果每個迭代完成的工作量大小類似,則在每個任務中分配相同或者類似的迭代次數;3)如果你的架構是由具有不同性能特征的機器異構組合而成,那麼請確保使用某種性能分析工具來簡則任何的負載不平衡,並相應調整工作。
- 采用動態任務分配方法:
即使數據在任務之間被平均分配,但是某些特定類型的問題也會導致負載不平衡,如下面三個例子所示。
稀疏矩陣:某些任務會具有真實數據,而大多數任務對應的數據卻為0。

自適應網格:某些方格需要被細分,而其它的不需要。

N體模擬:粒子可能會跨任務域遷移,因此某些任務會需要承擔更多的工作。
當每個任務的工作量是可變的,或者無法預測的,那麼可以采用 調度任務池 (Scheduler-task pool) 方法。每當某個任務完成瞭它的工作,它就可以從工作隊列中領取新的任務。

最終來看,可能需要設計一種在代碼中動態發生和處理負載不平衡的算法。
6.8 粒度 (Granularity)
計算通訊比 (computation / Communication Ratio):
在並行計算中,粒度是對計算與通訊的比例的定性度量。計算周期通常通過同步時間與通訊周期分離。
細粒度並行化 (Fine-grain Parallelism):
1)在通訊事件之外進行相對較少的計算工作;
2)計算通訊率較低;
3)方便負載均衡;
4)意味著較高的通訊開銷以及較少的性能提升機會;
5)如果粒度過細,任務之間的通訊和同步的開銷可能需要比計算更長的時間。

粗粒度並行化 (Coarse-grain Parallelism):
1)在通訊/同步事件之外需要較大量的計算工作;
2)較高的計算/通訊比;
3)意味著較大的性能提升機會;
4)難以進行較好的負載均衡。

最佳選擇:
最有效的粒度取決於具體算法及其所運行的硬件環境。在大多數情況下,與通訊/同步相關的開銷相對於執行速度很高,因此具有粗粒度的問題是相對有利的。而從另外一方面來講,細粒度則可以幫助減少由負載不均衡所造成的開銷。
6.9 輸入輸出 (I/O)
壞消息:
1)I/O操作通常被認為是並行化的抑制劑;
2)I/O操作通常比內存操作需要多個數量級的時間;
3)並行I/O系統可能不成熟或者不適用於所有平臺;
4)在所有任務均可以看到相同文件空間的環境中,寫操作可能導致文件被覆蓋;
5)讀操作可能受到文件服務器同時處理多個讀取請求的能力影響;
6)必須通過網絡進行的I/O操作(NFS,非本地)可能導致嚴重的性能瓶頸,甚至導致文件服務器崩潰。

好消息:
已經具有不少並行文件系統,例如:
GPFS:通用並行文件系統 (General Parallel File System)(IBM),現在也被稱為IBM Spectrum Scale。
Lustre:針對Linux的集群(Intel)。
HDFS:Hadoop分佈式文件系統(Apache)。
PanFS:Panasas ActiveScale File System for Linux clusters (Panasas, Inc.)更多並行文件系統可以參加這裡。
作為MPI-2的一部分,1996年以來MPI的並行I/O編程借口規范已經可用。
註意事項:
1)盡可能減少整體I/O操作;
2)如果你有權訪問並行文件系統,請使用它;
3)在大塊數據上執行少量寫操作往往比在小塊數據上進行大量寫操作有著更明顯的效率提升;
4)較少的文件比許多小文件更好;
5)將I/O操作限制在作業的特定串行部分,然後使用並行通訊將數據分發到並行任務中。例如任務1可以讀輸入文件,然後將所需數據傳送到其它任務。同樣,任務2可以再從所有其它任務收到所需數據之後執行寫入操作;
6)跨任務的I/O整合——相比於很多任務都執行I/O操作,更好地策略是隻讓一部分任務執行I/O操作。
6.10 調試 (Debugging)
調試並行代碼可能非常困難,特別是隨著代碼量的擴展。而好消息是有一些優秀的調試器可以提供幫助:
1)Threaded – Pthreads和OpenMP;
2)MPI;
3)GPU/accelerator;
4)Hybrid。
在LC集群上也安裝有一些並行調試工具:
1)TotalView (RogueWave Software);
2)DDT (Allinea);
3)Inspector(Intel);
4)Stack Trace Analysis Tool(STAT)(本地開發)。
更多的信息可以參考:LC web pages,TotalView tutorial。
6.11 性能分析和調優 (Performance Analysis and Tuning)
對於調試而言,並行程序的性能分析和調優比串行程序更具挑戰性。幸運的是,並行程序性能分析和調優有很多優秀的工具。Livemore計算機用戶可以訪問這種類似工具,其中大部分都在集群系統上。一些安裝在LC系統上的工具包括:
LC’s web pages:https://hpc.llnl.gov/software/development-environment-software
TAU: http://www.cs.uoregon.edu/research/tau/docs.php
HPCToolkit: http://hpctoolkit.org/documentation.html
Open|Speedshop: http://www.openspeedshop.org/
Vampir / Vampirtrace: http://vampir.eu/
Valgrind: http://valgrind.org/
PAPI: http://icl.cs.utk.edu/papi/
mpitrace:https://computing.llnl.gov/tutorials/bgq/index.html#mpitrace
mpiP: http://mpip.sourceforge.net/
memP: http://memp.sourceforge.net/

7 並行示例
7.1 數組處理
此示例演示瞭對二維數組元素的操作:將某個函數作用於二維數組中的每個元素,其中對每個數組元素的操作都是獨立於其它數組元素的,並且該問題是計算密集型的。對於串行程序而言,我們依次對每個元素進行操作,其代碼類似於:
do j = 1,n
do i = 1,n
a(i,j) = fcn(i,j)
end do
end do

問題:
- 該問題是否可以被並行化?
- 如果對該問題進行分割?需要數據通訊嗎?
- 有沒有數據依賴?
- 有沒有同步需求?
- 是否需要考慮負載均衡?
並行方案1:
由於對元素的計算彼此之間是獨立的,所以可以有“尷尬並行”的解決方案。
由於數組元素是均勻分佈的,所以每個進程可以擁有陣列的一部分(子陣列)。
- 1)可以選擇最佳分配方案以實現高效的內存訪問,例如選擇步幅為1,或者選擇合適的步幅以最大化緩存/內存使用。
- 2)由於可以使單元跨越子陣列,所以分配方案的選擇也取決於編程語言,有關選項可以參見第 6.3 節。
由於數組元素的計算是彼此獨立的,所以不需要任務之間的通訊和同步。
由於任務之間的工作量是被平均分配的,所以不需要考慮負載均衡。
對數組分割之後,每個任務執行與其擁有的數據相對應的循環部分,其源代碼類似於:
請註意隻有外部循環變量與串行解決方案不同。
for i (i = mystart; i < myend; i++) {
for j (j = 0; j < n; j++) {
a(i,j) = fcn(i,j);
}
}
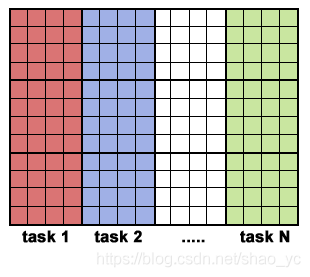
一種可能的解決方案:
1)采用單程序多數據 (SPMD) 模型進行實現,每個任務執行相同的程序;
2)主進程對數組進行初始化,將信息發送給子任務,並且接收計算結果;
3)子進程接收到信息之後,執行計算任務,並且將結果發送給主進程;
4)采用Fortran的存儲結構,對數組進行塊劃分;
5)偽代碼如下所示。
6)具體的C代碼可以參見MPI Program in C:
find out if I am MASTER or WORKER
if I am MASTER
initialize the array
send each WORKER info on part of array it owns
send each WORKER its portion of initial array
receive from each WORKER results
else if I am WORKER
receive from MASTER info on part of array I own
receive from MASTER my portion of initial array
# calculate my portion of array
do j = my first column,my last column
do i = 1,n
a(i,j) = fcn(i,j)
end do
end do
send MASTER results
endif
並行方案2:
上一個並行方案展示瞭靜態負載均衡:1)每個任務執行固定量的工作;2)某些很快或者負載較輕的處理器將會擁有空閑時間,而最慢執行的任務最終決定整體性能。
如果所有任務在同一臺機器上運行相同量的工作,那麼靜態負載均衡往往並不是一個主要問題。但是如果你確實有負載均衡方面的問題(某些任務比其它任務運行的快),那麼你可以采用“任務池”(pool of tasks)模式。
任務池模式: 裡面包含兩個進程:
主進程:
1)擁有任務池;2)如果得到請求,給工作進程發送工作任務;3)從工作進程出收集返回結果。
工作進程:
1)從主進程處獲取任務;2)執行計算任務;3)向主進程發送結果。
工作進程在運行之前不知道它將處理數組的哪一部分,以及它將執行多少任務。動態負載均衡發生在運行時:運行最快的任務將完成更多的任務。一段可能的源代碼如下:
find out if I am MASTER or WORKER
if I am MASTER
do until no more jobs
if request send to WORKER next job
else receive results from WORKER
end do
else if I am WORKER
do until no more jobs
request job from MASTER
receive from MASTER next job
calculate array element: a(i,j) = fcn(i,j)
send results to MASTER
end do
endif
討論:
1)在上述任務池例子中,每個任務計算數組的某一個元素,計算與通訊比率是細粒度的;
2)細粒度的解決方案為瞭減少任務空閑時間,往往會導致更多的通訊開銷;
3)更好地解決方案可能是在每個任務中分配更多的工作,“正確”的工作量依然是依賴於具體問題的。
7.2 圓周率計算


該問題的串行代碼大約是這樣的:
npoints = 10000 circle_count = 0 do j = 1,npoints generate 2 random numbers between 0 and 1 xcoordinate = random1 ycoordinate = random2 if (xcoordinate, ycoordinate) inside circle then circle_count = circle_count + 1 end do PI = 4.0*circle_count/npoints
該問題是計算密集型的——大多數時間將花費在對循環的執行。
問題:
- 該問題是否可以被並行化?
- 如何對該問題進行分割?
- 任務之間是否需要通訊?
- 是否存在數據依賴?
- 任務之間是否有同步需求?需
- 要考慮負載均衡嗎?
解決方案:
又一個容易被並行化的問題:
1)每個點的計算都是獨立的,不存在數據依賴;
2)工作可以被平均分配,不需要考慮負載均衡;
3)任務之間不需要通訊和同步。


下面是並行化之後的偽代碼:
npoints = 10000 circle_count = 0 p = number of tasks num = npoints/p find out if I am MASTER or WORKER do j = 1,num generate 2 random numbers between 0 and 1 xcoordinate = random1 ycoordinate = random2 if (xcoordinate, ycoordinate) inside circle then circle_count = circle_count + 1 end do if I am MASTER receive from WORKERS their circle_counts compute PI (use MASTER and WORKER calculations) else if I am WORKER send to MASTER circle_count endif
C語言的示例程序可以參考這裡:MPI Program in C。
7.3 簡單熱方程
大多數並行計算問題需要任務之間的通訊,其中一大部分問題需要“相鄰”任務之間的通訊。

二維熱方程問題描述瞭在給定初始溫度分佈以及邊界條件的情況下,溫度隨著時間的變化。有限差分方案可以采用數值方法求解正方形區域內的熱擴散方程:
二維數組的元素用來表示正方形區域內的點的溫度;
邊界處的初始問題是0,中心點的問題最高;
邊界處的問題會保持為0;
采用時間步長算法。
每個元素的文圖的計算取決於它的鄰居的溫度:

串行程序的代碼可能使這個樣子:
do iy = 2, ny - 1
do ix = 2, nx - 1
u2(ix, iy) = u1(ix, iy) +
cx * (u1(ix+1,iy) + u1(ix-1,iy) - 2.*u1(ix,iy)) +
cy * (u1(ix,iy+1) + u1(ix,iy-1) - 2.*u1(ix,iy))
end do
end do
問題:
該問題是否可以被並行化?
如何對該問題進行分割?
任務之間是否需要通訊?
是否存在數據依賴?
任務之間是否需要同步?
是否需要考慮負載均衡?
解決方案:
該問題更具有挑戰性。因為存在數據依賴,所以需要任務之間的通訊和同步。整個數組需要被風格成為子數組,並分配給不同任務,每個任務擁有整個數組的一部分。由於任務量是均勻劃分的,所以不需要考慮負載均衡。
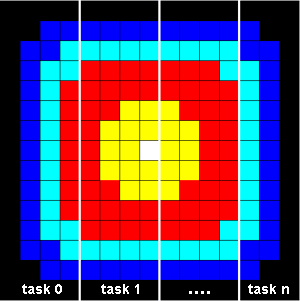
確定數據依賴:
1)一個任務的 內部元素 和其它任務之間不存在數據依賴;
2)一個任務的 邊界元素 則和它的鄰居任務之間需要產生數據通訊。
采用單程序多數據模型(SPMD)進行實現:
1)主進程向工作進程發送初始信息,然後等待並收集來自工作進程的計算結果;
2)工作進程在特定的時間步長內計算結果,並與鄰居進程之間進行數據交換。
偽代碼如下:
find out if I am MASTER or WORKER
if I am MASTER
initialize array
send each WORKER starting info and subarray
receive results from each WORKER
else if I am WORKER
receive from MASTER starting info and subarray
# Perform time steps
do t = 1, nsteps
update time
send neighbors my border info
receive from neighbors their border info
update my portion of solution array
end do
send MASTER results
endif
示例程序可以參加:MPI Program in C。
7.4 一維波動方程
在這個例子中,我們計算經過指定時間量之後,一維波動曲線的振幅。其中的計算會涉及到:
1)y軸上的振幅;
2)x軸上的位置索引i;
3)沿著波動曲線的節點;
4)以離散時間步長更新振幅。

這裡需要求解的是如下一維波動方程,其中c是常數。
A(i,t+1) = (2.0 * A(i,t)) - A(i,t-1) + (c * (A(i-1,t) - (2.0 * A(i,t)) + A(i+1,t)))
我們註意到,t時刻的振幅取決於前一刻的時間步長(t, t-1)以及相鄰點(i – 1, i + 1)。
問題:
該問題是否可以被並行化?
如何對該問題進行分割?
任務之間是否需要通訊?
人物之間是否存在數據依賴?
任務之間是否需要同步?
是否需要考慮負載均衡?
解決方案:
這是涉及到數據依賴的另外一個例子,其並行方案將會涉及到任務見的通訊和同步。整個振幅陣列被分割並分配給所有的子任務,每個任務擁有總陳列的相等的部分。由於所有點需要相等的工作,所以我們應該均勻地分配節點。我們可以將工作分成多個塊,並且允許每個任務擁有大多數連續的數據點。而通訊隻需要在數據邊界上進行,塊大小越大,則所需的通信越少。

采用單程序多數據(SPMD)模型的實現:
1)主進程向工作進程發送初始信息,並且等到各個工作進程返回計算結果;
2)工作進程對特定步長之內的任務進行計算,並且在必要的時候和鄰居進程進行數據通訊。
其偽代碼如下:
find out number of tasks and task identities
#Identify left and right neighbors
left_neighbor = mytaskid - 1
right_neighbor = mytaskid +1
if mytaskid = first then left_neigbor = last
if mytaskid = last then right_neighbor = first
find out if I am MASTER or WORKER
if I am MASTER
initialize array
send each WORKER starting info and subarray
else if I am WORKER`
receive starting info and subarray from MASTER
endif
#Perform time steps
#In this example the master participates in calculations
do t = 1, nsteps
send left endpoint to left neighbor
receive left endpoint from right neighbor
send right endpoint to right neighbor
receive right endpoint from left neighbor
#Update points along line
do i = 1, npoints
newval(i) = (2.0 * values(i)) - oldval(i)
+ (sqtau * (values(i-1) - (2.0 * values(i)) + values(i+1)))
end do
end do
#Collect results and write to file
if I am MASTER
receive results from each WORKER
write results to file
else if I am WORKER
send results to MASTER
endif
程序示例可以參見:MPI Program in C。
8 參考文獻和更多信息
作者:Blaise Barney,Livermore Computing.
在萬維網上搜索“parallel programming”或者“parallel computing”將會獲得大量信息。
推薦閱讀:
”Designing and Building Parallel Programs”. Lan Foster.
http://www.mcs.anl.gov/~itf/dbpp/“
Introduction to Parallel Computing”. Ananth Grama, Anshul Gupta, George Karpis, Vpin Kumar.
http://www-users.cs.umn.edu/~karypis/parbook/“
Overview of Recent Supercomputers”. A.J. van der Steen, Jack Dongarra.
OverviewRecentSupercomputers.2008.pdf
圖片/圖像由作者以及其它LLNL成員創建,或者從不涉及版權的政府或公領域()獲取,或者經所有者同意從其演示文稿或者網頁上獲取。
歷史:該材料有下面的資源演化而來,而這些資源將不再被維護或者不再可用。
Tutorials located in the Maui High Performance Computing Center’s “SP Parallel Programming Workshop”.
Tutorials located at the Cornell Theory Center’s “Education and Training” web page.
以上就是並行計算概念及定義全面詳解的詳細內容,更多關於並行計算的資料請關註WalkonNet其它相關文章!