Mysql數據庫的主從復制與讀寫分離精講教程
前言
在實際的生產環境中,如果對MySQL數據庫的讀和寫都在一臺數據庫服務中操作,無論在安全性、高可用性,還是高並發性等各個方面都是完全不能滿足實際需求的,一般來說都是通過主從復制(Master-Slave)的方式來同步數據,再通過讀寫分離來提升數據庫的並發負載能力這樣的方案進行部署與實施
一、MySQL主從復制
1.支持的復制類型
基於語句的復制(statement):在服務器上執行sql語句,在從服務器上執行同樣的語句,mysql默認采用基於語句的復制,執行效率高基於行的復制(row): 把改變的內容復制過去,而不是把命令在從服務器上執行一遍混合類型的復制(mixed): 在服務器上執行sql語句,在從服務器上執行同樣的語句,mysql默認采用基於語句的復制,執行效率高
2.主從復制的工作過程是基於日志
master二進制日志
slave中繼日志
3.請求方式
I/O線程
dump線程
SQL線程
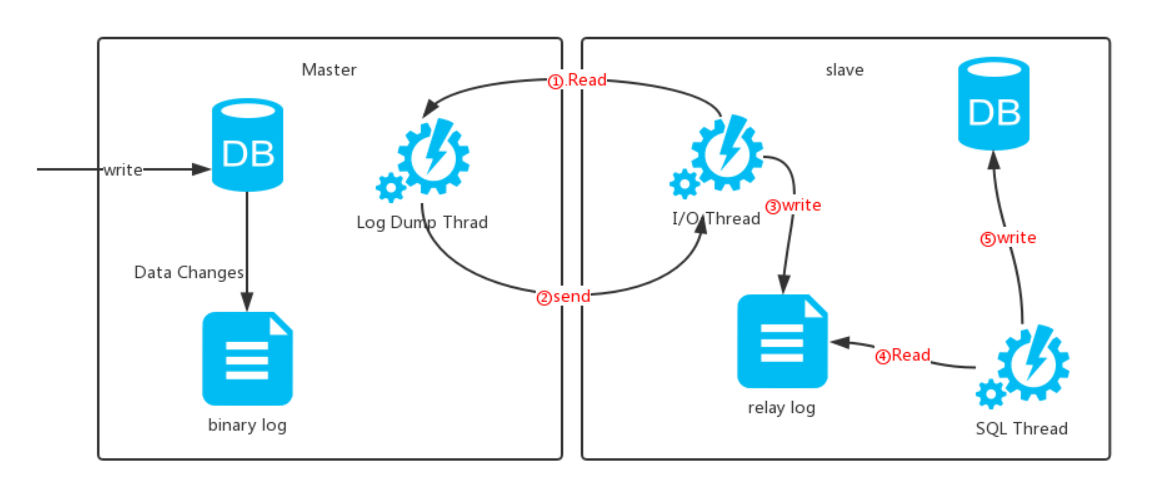
4.主從復制的原理
①Master節點將數據的改變記錄成二進制日志(bin log),當Master上的數據發生改變時,則將其改變寫入二進制日志中
②Slave節點會在一定時間間隔內對Master的二進制日志進行探測其是否發生改變
如果發生改變,則開始一個I/O線程請求 Master的二進制事件
③同時Master節點為每個I/O線程啟動一個dump線程,用於向其發送二進制事件,並保存至Slave節點本地的中繼日志(Relay log)中
④Slave節點將啟動SQL線程從中繼日志中讀取二進制日志,在本地重放,即解析成 sql 語句逐一執行,使得其數據和 Master節點的保持一致,最後I/O線程和SQL線程將進入睡眠狀態,等待下一次被喚醒
復制過程有一個很重要的限制,即復制在 Slave 上是串行化的,也就是說 Master 上的並行更新操作不能在 Slave 上並行操作
中繼日志通常會位於OS緩存中,所以中繼日志的開銷很小
5.MySQL集群和主從復制分別適合在什麼場景下使用
集群和主從復制是為瞭應對高並發、大訪問量的情況,如果網站訪問量和並發量太大瞭,少量的數據庫服務器是處理不過來的,會造成網站訪問慢,數據寫入會造成數據表或記錄被鎖住,鎖住的意思就是其他訪問線程暫時不能讀寫要等寫入完成才能繼續,這樣會影響其他用戶讀取速度,采用主從復制可以讓一些服務器專門讀,一些專門寫可以解決這個問題
6.為什麼使用主從復制、讀寫分離
主從復制、讀寫分離一般是一起使用的,目的很簡單,就是為瞭提高數據庫的並發性能。你想,假設是單機,讀寫都在一臺MySQL上面完成,性能肯定不高。如果有三臺MySQL,一臺mater隻負責寫操作,兩臺salve隻負責讀操作,性能不就能大大提高瞭嗎?
所以主從復制、讀寫分離就是為瞭數據庫能支持更大的並發
隨著業務量的擴展、如果是單機部署的MySQL,會導致I/O頻率過高。采用主從復制、讀寫分離可以提高數據庫的可用性
7.用途及條件
mysql主從復制用途:
實時災備,用於故障切換
讀寫分離,提供查詢服務
備份,避免影響服務
必要條件:
主庫開啟binlog日志(設置log-bin參數)
主從server-id不同
從庫服務器能連通主庫
8.mysql主從復制存在的問題
主庫宕機後,數據可能丟失
從庫隻有一個SQL Thread,主庫寫壓力大,復制很可能延時
解決辦法
半同步復制——解決數據丟失的問題
並行復制——解決從庫復制延遲的問題
9.MySQL主從復制延遲
①master服務器高並發,形成大量事務
②網絡延遲
③主從硬件設備導致——cpu主頻、內存io、硬盤io
④本來就不是同步復制、而是異步復制
- 從庫優化Mysql參數。比如增大innodb_buffer_pool_size,讓更多操作在Mysql內存中完成,減少磁盤操作
- 從庫使用高性能主機,包括cpu強悍、內存加大。避免使用虛擬雲主機,使用物理主機,這樣提升瞭i/o方面性
- 從庫使用SSD磁盤
- 網絡優化,避免跨機房實現同步
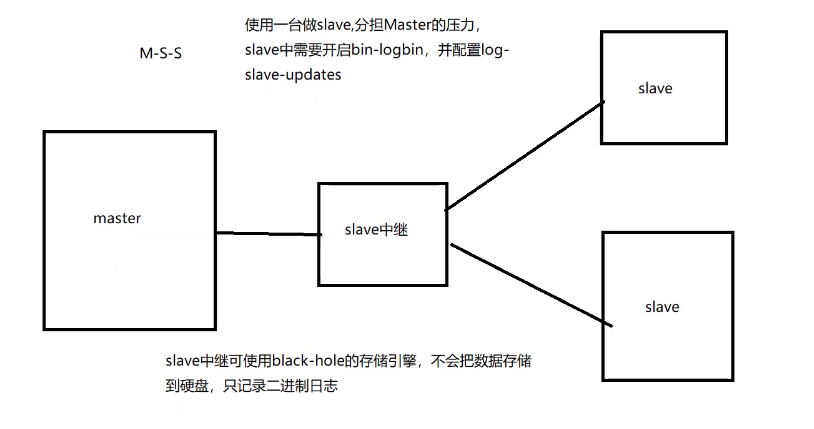
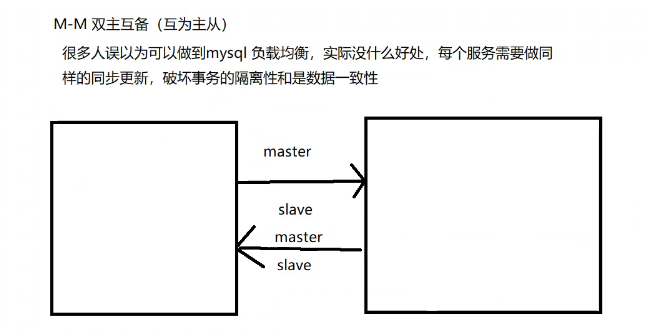
二、主從復制的形式

三、讀寫分離
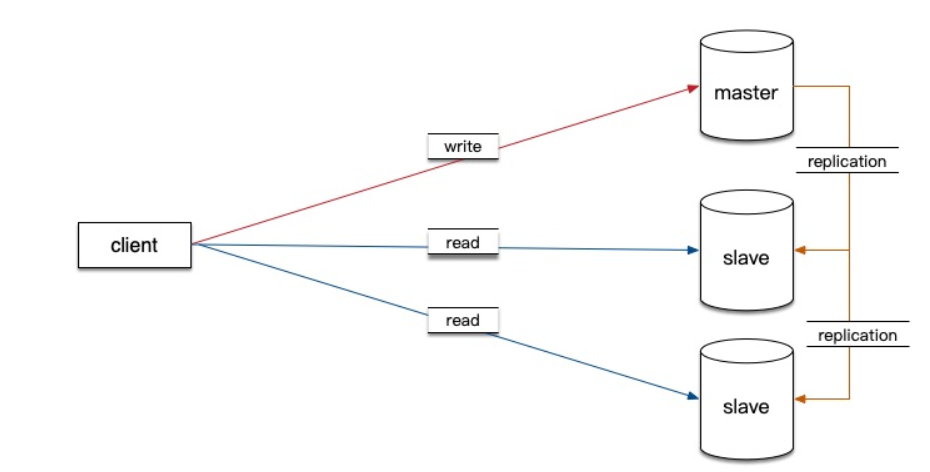
1.原理
①隻在主服務器上寫,隻在從服務器上讀
②主數據庫處理事務性查詢,從數據庫處理select查詢
③數據庫復制用於將事務性查詢導致的變更同步到集群中的從數據庫
2.為什麼要讀寫分離呢?
因為數據庫的“寫”(寫10000條數據可能要3分鐘)操作是比較耗時的但是數據庫的“讀”(讀10000條數據可能隻要5秒鐘)所以讀寫分離,解決的是,數據庫的寫入,影響瞭查詢的效率
3.什麼時候要讀寫分離?
數據庫不一定要讀寫分離,如果程序使用數據庫較多時,而更新少,查詢多的情況下會考慮使用利用數據庫主從同步,再通過讀寫分離可以分擔數據庫壓力,提高性能 4.主從復制與讀寫分離 在實際的生產環境中,對數據庫的讀和寫都在同一個數據庫服務器中,是不能滿足實際需求的
5.目前較為常見的MySQL讀寫分離
分為以下兩種
①基於程序代碼內部實現
在代碼中根據 select、insert 進行路由分類,這類方法也是目前生產環境應用最廣泛的優點是性能較好,因為在程序代碼中實現,不需要增加額外的設備為硬件開支;缺點是需要開發人員來實現,運維人員無從下手但是並不是所有的應用都適合在程序代碼中實現讀寫分離,像一些大型復雜的Java應用,如果在程序代碼中實現讀寫分離對代碼改動就較大
②基於中間代理層實現
代理一般位於客戶端和服務器之間,代理服務器接到客戶端請求後通過判斷後轉發到後端數據庫,有以下代表性程序
(1)MySQL-Proxy,MySQL-Proxy 為 MySQL 開源項目,通過其自帶的 lua 腳本進行SQL 判斷。
(2)Atlas,是由奇虎360的Web平臺部基礎架構團隊開發維護的一個基於MySQL協議的數據中間層項目,它是在mysql-proxy 0.8.2版本的基礎上,對其進行瞭優化,增加瞭一些新的功能特性。360內部使用Atlas運行的mysql業務,每天承載的讀寫請求數達幾十億條。支持事物以及存儲過程
(3)Amoeba,由陳思儒開發,作者曾就職於阿裡巴巴。該程序由Java語言進行開發,阿裡巴巴將其用於生產環境。但是它不支持事務和存儲過程。
由於使用MySQL Proxy 需要寫大量的Lua腳本,這些Lua並不是現成的,而是需要自己去寫,這對於並不熟悉MySQL Proxy 內置變量和MySQL Protocol 的人來說是非常困難的Amoeba是一個非常容易使用、可移植性非常強的軟件。因此它在生產環境中被廣泛應用於數據庫的代理層
四、案例實施
1.案例環境
本案例環境使用舞臺服務器磨你搭建,拓撲圖如下
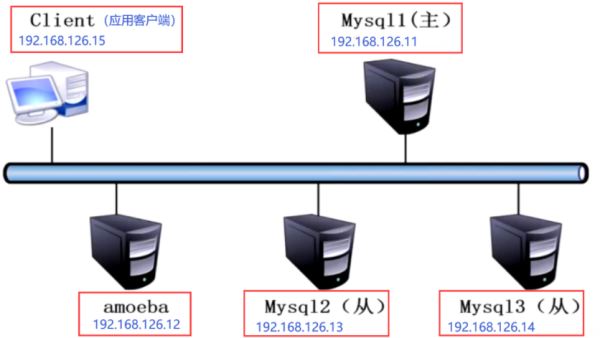
| 主機名 | 主機 | 操作系統 | IP 地址 | 主要軟件 |
|---|---|---|---|---|
| CentOS 7-1 | Master | CentOS 7 | 192.168.126.11 | ntp 、 mysql-boost-5.7.17.tar.gz |
| CentOS 7-2 | Amoeba | CentOS 7 | 192.168.126.12 | jdk-6u14-linux-x64.bin、amoeba-mysql-binary-2.2.0.tar.gz |
| CentOS 7-3 | Slave1 | CentOS 7 | 192.168.126.13 | ntp 、ntpdate 、 mysql-boost-5.7.20.tar.gz |
| CengOS 7-4 | Slave2 | CentOS 7 | 192.168.126.14 | ntp 、ntpdate 、mysql-boost-5.7.17.tar.gz |
| CentOS 7-5 | 客戶端 | CentOS 7-5 | 192.168.126.15 | mysql5.7 |
2.實驗思路(解決需求)
客戶端訪問代理服務器
代理服務器寫入到主服務器
主服務器將增刪改寫入自己二進制日志
從服務器將主服務器的二進制日志同步至自己中繼日志
從服務器重放中繼日志到數據庫中
客戶端讀,則代理服務器直接訪問從服務器
降低負載,起到負載均衡作用
3.準備
- 除瞭客戶端,都需要先源碼編譯安裝好MySQL
- 都需關閉防火墻及控制訪問機制
systemctl stop firewalld systemctl disable firewalld #關閉防火墻(及開機禁用) setenforce 0 #關閉安全訪問控制機制
4.搭建MySQL主從復制
①Mysql主從服務器時間同步
主服務器設置
#安裝 NTP yum -y install ntp #配置 NTP vim /etc/ntp.conf #末行添加以下內容 server 127.127.126.0 fudge 127.127.126.0 stratum 8 #設置本地是時鐘源,註意修改網段 #設置時間層級為8(限制在15內) #重啟服務 service ntpd restart
從服務器設置
yum -y install ntp ntpdate #安裝服務,ntpdate用於同步時間 service ntpd start #開啟服務 /usr/sbin/ntpdate 192.168.126.11 #進行時間同步,指向Master服務器IP crontab -e #寫入計劃性任務,每半小時進行一次時間同步 */30 * * * * /usr/sbin/ntpdate 192.168.126.11
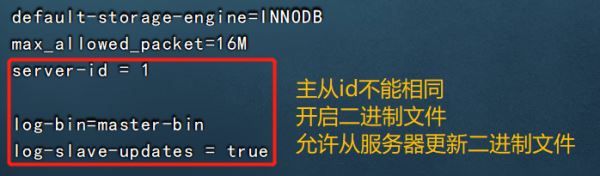
②配置MySQL Master主服務器
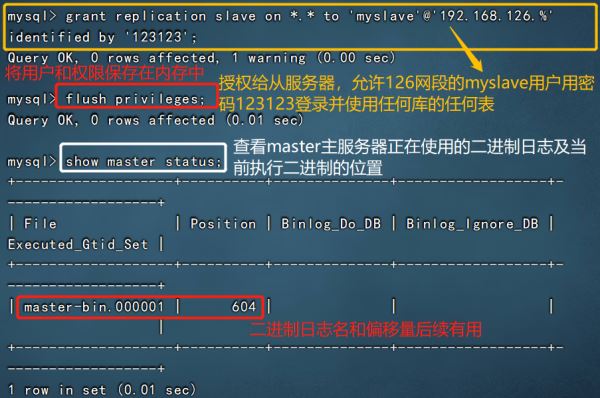
vim /etc/my.cnf #配置以下內容 server-id = 1 log-bin=master-bin #添加,主服務器開啟二進制日志 log-slave-updates=true #添加,允許從服務器更新二進制日志 systemctl restart mysqld #重啟服務使配置生效 mysql -uroot -p123123 #登錄數據庫程序,給從服務器授權 GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.126.%' IDENTIFIED BY '123123'; FLUSH PRIVILEGES; show master status; quit #File 列顯示日志名,Fosition 列顯示偏移量
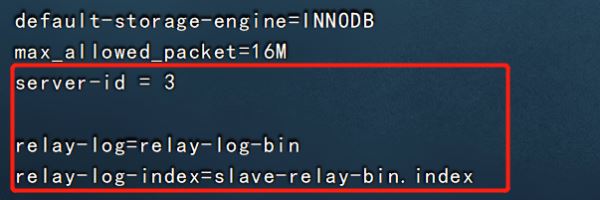
③配置從服務器
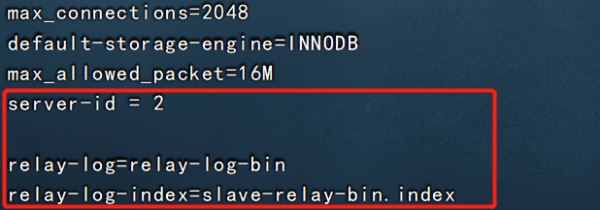
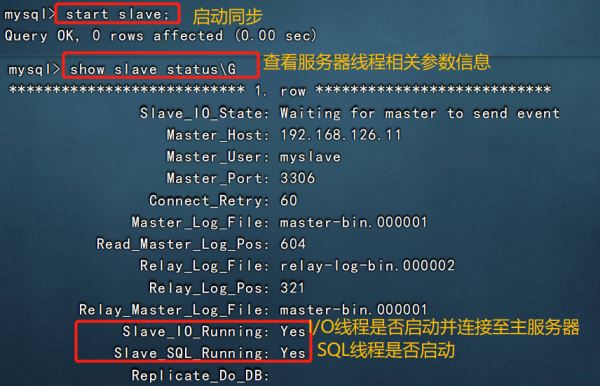
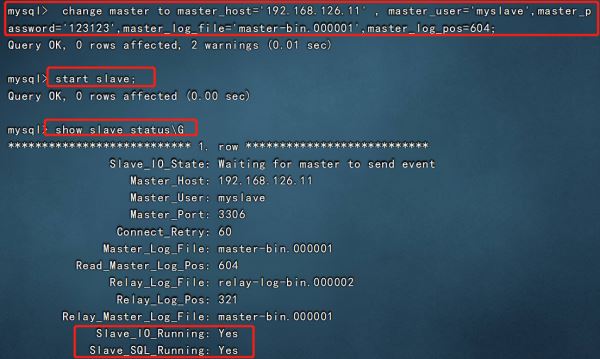
vim /etc/my.cnf server-id = 2 #修改,註意id與Master的不同,兩個Slave的id也要不同 relay-log=relay-log-bin #添加,開啟中繼日志,從主服務器上同步日志文件記錄到本地 relay-log-index=slave-relay-bin.index #添加,定義中繼日志文件的位置和名稱 systemctl restart mysqld mysql -uroot -p123123 change master to master_host='192.168.126.11' , master_user='myslave',master_password='123123',master_log_file='master-bin.000001',master_log_pos=604; #配置同步,註意 master_log_file 和 master_log_pos 的值要與Master的一致 start slave; #啟動同步,如有報錯執行 reset slave; show slave status\G #查看 Slave 狀態 //確保 IO 和 SQL 線程都是 Yes,代表同步正常 Slave_IO_Running: Yes #負責與主機的io通信 Slave_SQL_Running: Yes #負責自己的slave mysql進程
slave1:

slave2: 和slave1配置一樣,id不能相同
一般 Slave_IO_Running: No 有這幾種可能性:
- 網絡不通
- my.cnf 配置有問題
- 密碼、file 文件名、pos 偏移量不對
- 防火墻沒有關閉
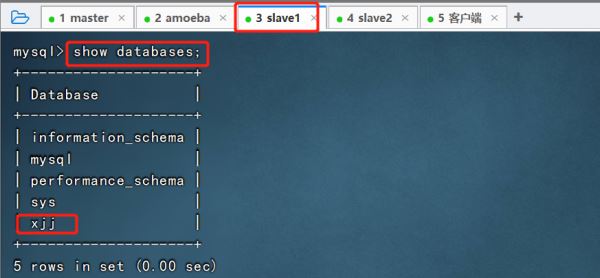
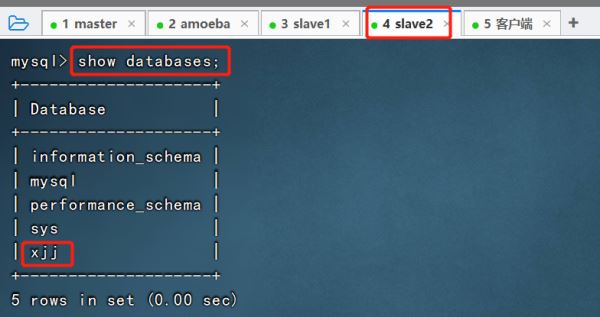
④驗證主從復制效果

5.搭建MySQL讀寫分離
- 這個軟件致力於 MySQL 的分佈式數據庫前端代理層,它主要為應用層訪問 MySQL 時充當 SQL 路由,並具有負載均衡、高可用性、SQL 過濾、讀寫分離、可路由相關到目標數據庫、可並發請求多臺數據庫
- 通過 Amoeba 能夠完成多數據源的高可用、負載均衡、數據切片的功能
①在主機Amoeba上安裝Java環境 因為 Amoeba 基於是 jdk1.5 開發的,所以官方推薦使用 jdk1.5 或 1.6 版本,高版本不建議使用
cd /opt/ #在FinalShell中,把軟件包拖進來 amoeba-mysql-binary-2.2.0.tar.gz jdk-6u14-linux-x64.bin cp jdk-6u14-linux-x64.bin /usr/local/ cd /usr/local/ chmod +x jdk-6u14-linux-x64.bin ./jdk-6u14-linux-x64.bin #按住Enter鍵不動一直到最下面,有提示輸入YES+回車即可 mv jdk1.6.0_14/ /usr/local/jdk1.6 #改名 vim /etc/profile #編輯全局配置文件,在最後一行添加以下配置 export JAVA_HOME=/usr/local/jdk1.6 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin export AMOEBA_HOME=/usr/local/amoeba export PATH=$PATH:$AMOEBA_HOME/bin #輸出定義Java的工作目錄 #輸出指定的java類型 #將java加入路徑環境變量 #輸出定義amoeba工作目錄 #加入路徑環境變量 source /etc/profile #執行修改後的全局配置文件 java -version #查看java版本信息以檢查是否安裝成功
②安裝並配置Amoeba
mkdir /usr/local/amoeba tar zxvf /opt/amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/ chmod -R 755 /usr/local/amoeba/ /usr/local/amoeba/bin/amoeba #如顯示 amoeba start|stop 說明安裝成功

③配置Amowba讀寫分離,兩個slave讀寫負載均衡 在master、slave1、slave2的mysql上開放權限給amoeba訪問



④在主機amoeba中編輯amoeba.xml配置文件
cd /usr/local/amoeba/conf/ cp amoeba.xml amoeba.xml.bak vim amoeba.xml #修改amoeba配置文件 #30行修改 <property name="user">amoeba</property> #32行修改 <property name="password">123123</property> #115行修改 <property name="defaultPool">master</property> #117去掉註釋 <property name="writePool">master</property> <property name="readPool">slaves</property>
⑤編輯dbServers.xml 配置文件
cp dbServers.xml dbServers.xml.bak vim dbServers.xml #修改數據庫配置文件 #23行註釋掉 作用:默認進入test庫 以防mysql中沒有test庫時,會報錯 <!-- <property name="schema">test</property> --> #26行修改 <property name="user">test</property> #28-30行去掉註釋 <property name="password">123.com</property> #45行修改,設置主服務器的名Master <dbServer name="master" parent="abstractServer"> #48行修改,設置主服務器的地址 <property name="ipAddress">192.168.126.11</property> #52行修改,設置從服務器的名slave1 <dbServer name="slave1" parent="abstractServer"> #55行修改,設置從服務器1的地址 <property name="ipAddress">192.168.126.13</property> #58行復制上面6行粘貼,設置從服務器2的名slave2和地址 <dbServer name="slave2" parent="abstractServer"> <property name="ipAddress">192.168.184.14</property> #65行修改 <dbServer name="slaves" virtual="true"> #71修改 <property name="poolNames">slave1,slave2</property>
⑥確定配置無誤後,可以啟動 Amoeba 軟件,其默認端口為 tcp 8066
/usr/local/amoeba/bin/amoeba start& #啟動Amoeba軟件,按ctrl+c 返回 netstat -anpt | grep java #查看8066端口是否開啟,默認端口為TCP 8066
⑦測試
1.前往客戶端快速裝好 MySQL 虛擬客戶端,然後通過代理訪問 MySQL
yum -y install mysql #用YUM快速安裝MySQL虛擬客戶端 mysql -u amoeba -p123123 -h 192.168.126.12 -P8066 #通過代理訪問MySQL,IP地址指向amoba #在通過客戶端連接mysql後寫入的數據隻有主服務會記錄,然後同步給從服務器
2.在 Master 上創建一個表,同步到兩個從服務器上
use club; create table puxin (id int(10),name varchar(10),address varchar(20));
3.然後關閉從服務器的 Slave 功能,從主服務器上同步瞭表,手動插入數據內容
stop slave;
#關閉同步
use club;
insert into puxin values('1','wangyi','this_is_slave1');
#slave2
insert into puxin values('2','wanger','this_is_slave2');
4.再回到主服務器上插入其他內容
insert into pucin values('3','wangwu','this_is_master');
5.測試讀操作,前往客戶端主機查詢結果
use club; select * from puxin;
6.在客戶端上插入一條語句,但是在客戶端上查詢不到,最終隻有在 Master 上才上查看到這條語句內容,說明寫操作在 Master 服務器上
insert into puxin values('4','liuliu','this_is_client');
7.再在兩個從服務器上執行 start slave; 即可實現同步在主服務器上添加的數據
總結
由此驗證,已經實現瞭 MySQL 讀寫分離,目前所有的寫操作全部在 Master 主服務器上,用來避免數據的不同步
而所有的讀操作都分攤給瞭 Slave 從服務器,用來分擔數據庫的壓力
1.如何查看主從同步狀態是否成功
在從服務器內輸入命令 show slave status\G,查看主從信息進行查看,裡面有IO線程的狀態信息,還有master服務器的IP地址、端口、事務開始號
當 slave_io_running 和 slave_sql_running 都顯示為yes時,表示主從同步狀態成功
2.如果I/O和SQL不是yes呢,你是如何排查的
- 首先排除網絡問題,使用ping命令查看從服務是否能與主服務器通信
- 再者查看防火墻和核心防護是否關閉
- 接著查看從服務器內的slave是否開啟
- 兩個從服務器的 server-id 是否相同導致隻能連上一臺
- master_log_file 和 master_log_pos 的值要是否與Master查詢的一致
3.show slave status能看到哪些信息(比較重要的)
- IO線程的狀態信息
- master服務器的IP地址、端口、事務開始位置
- 最近一次的報錯信息和報錯位置等
4.主從復制慢(延遲)有哪些可能
- 主服務器的負載過大,被多個睡眠或者僵屍線程占用,導致系統負載過大
- 從庫硬件比主庫差,導致復制延遲
- 主從復制單線程,如果主庫寫並發太大,來不及傳送到從庫,就會導致延遲
- 慢SQL語句過多
- 網絡延遲
以上就是Mysql數據庫的主從復制與讀寫分離精講教程的詳細內容,更多關於Mysql數據庫主從復制與讀寫分離的資料請關註WalkonNet其它相關文章!