VMware + Ubuntu18.04 搭建Hadoop集群環境的圖文教程
前言
本次教程是基於學校的大數據實驗而做的,博主在搭建的同時,記錄瞭自己的命令運行結果截圖,在圖書館搭建環境+寫博客,也花瞭將近3個小時。長時間眼睛對著電腦會很傷眼睛,所以童鞋們需要註意保護好眼睛,做做眼保健操。希望學到的童鞋可以點個贊!

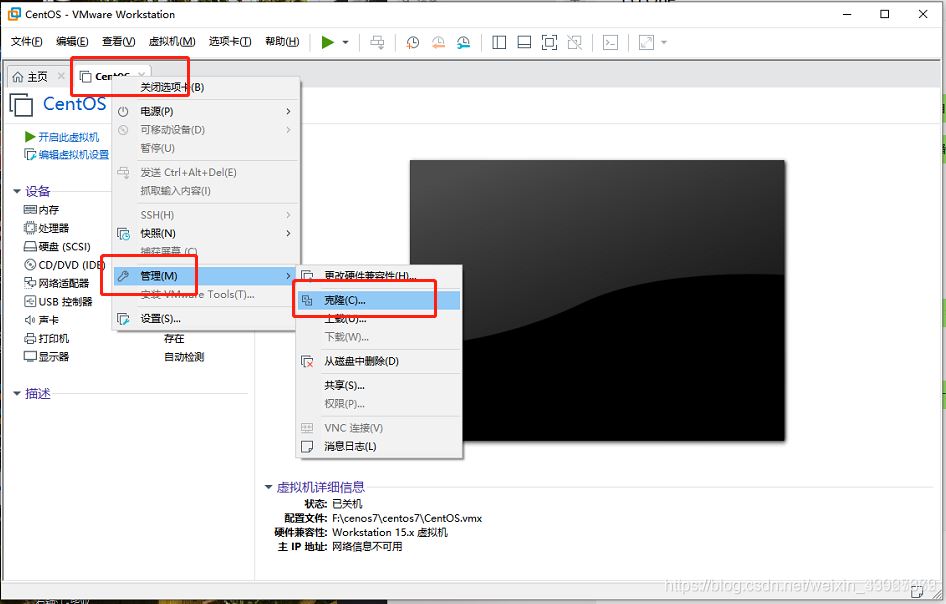
VMware克隆虛擬機(準備工作,克隆3臺虛擬機,一臺master,兩臺node)
- 先在虛擬機中關閉系統
- 右鍵虛擬機,點擊管理,選擇克隆
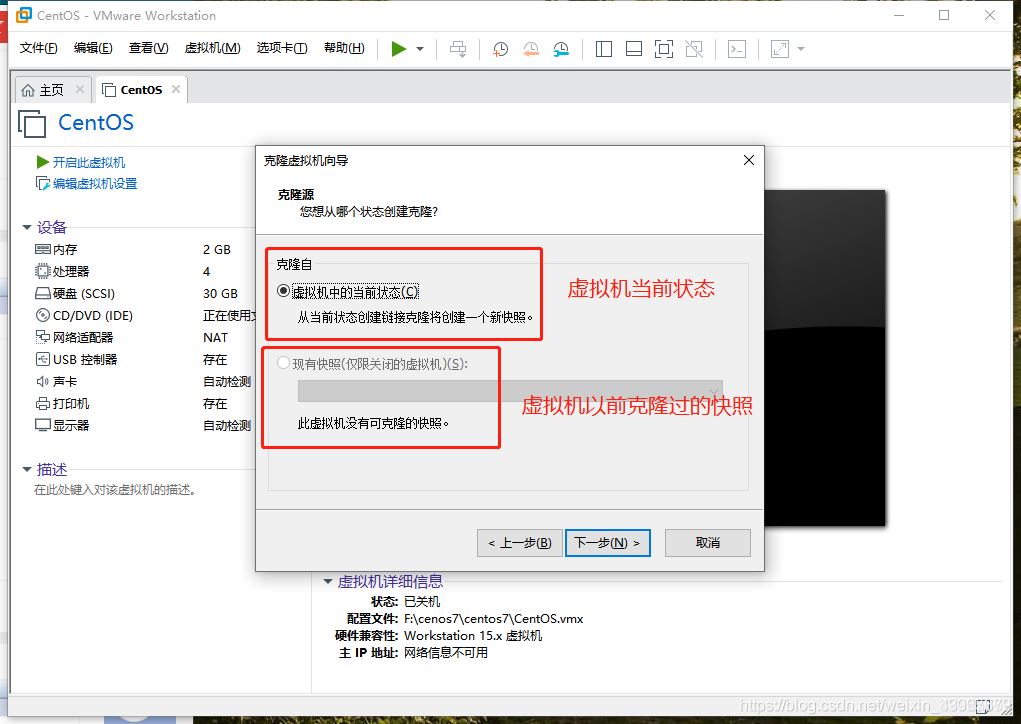
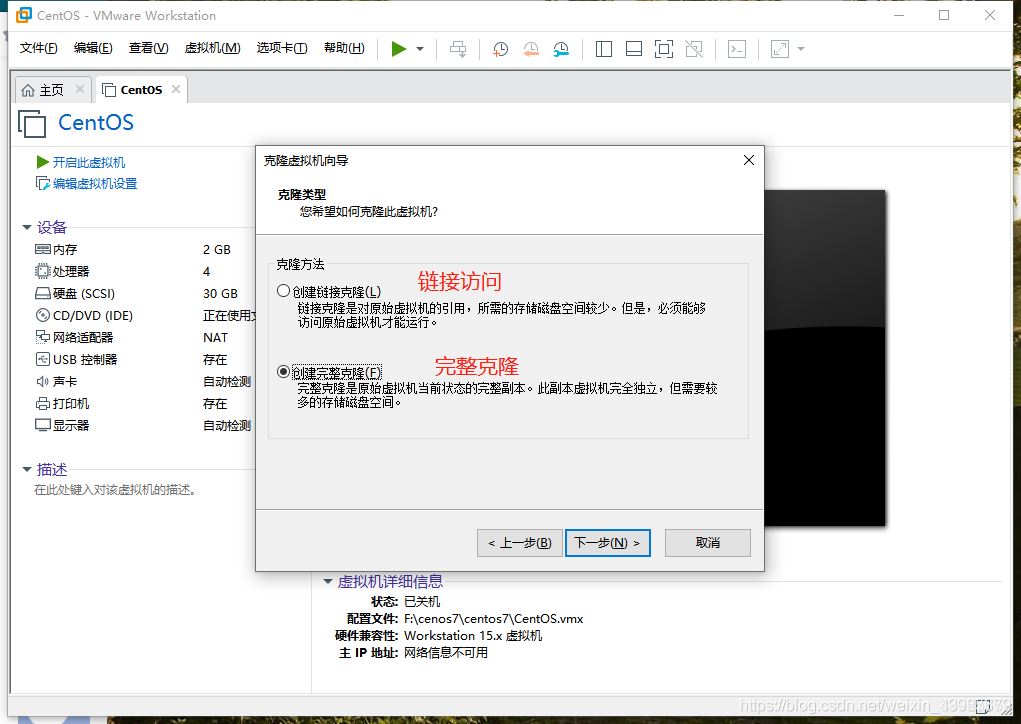
3.點擊下一步,選擇完整克隆,選擇路徑即可
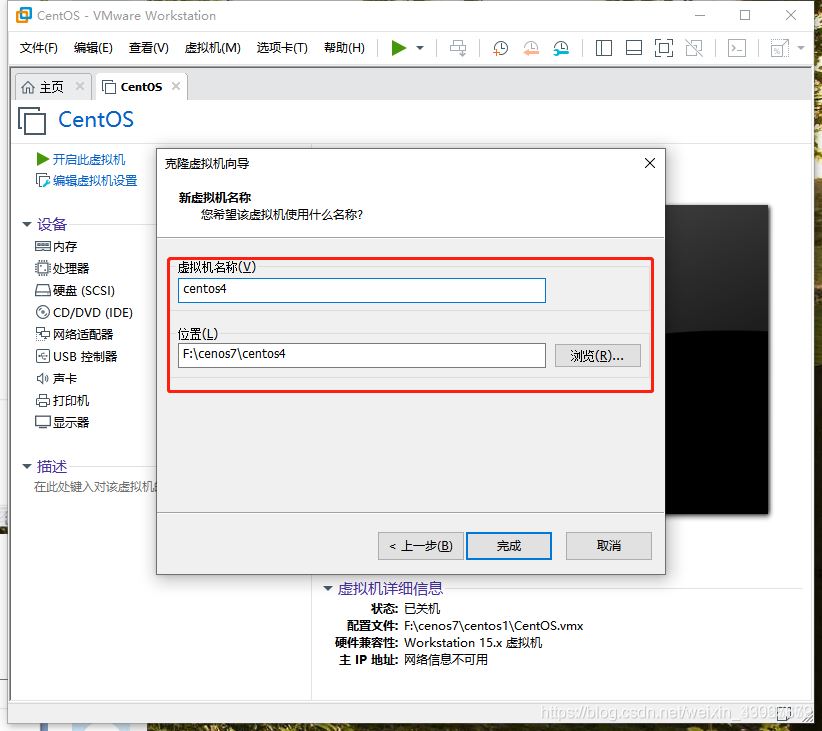
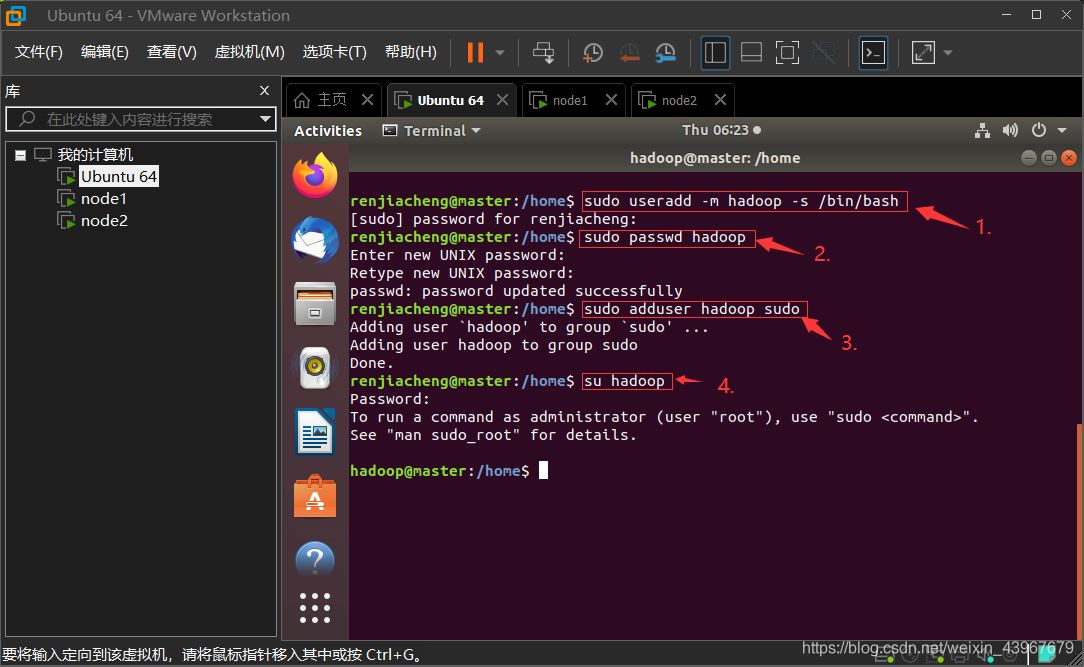
1.創建Hadoop用戶(在master,node1,node2執行)
順序執行以下命令即可
1.創建hadoop用戶
sudo useradd -m hadoop -s /bin/bash
設置用戶密碼(輸入兩次)
sudo passwd hadoop
添加權限
sudo adduser hadoop sudo
切換到hadoop用戶(這裡要輸入剛剛設置的hadoop密碼)
su hadoop
運行截圖展示(以master虛擬機為例)
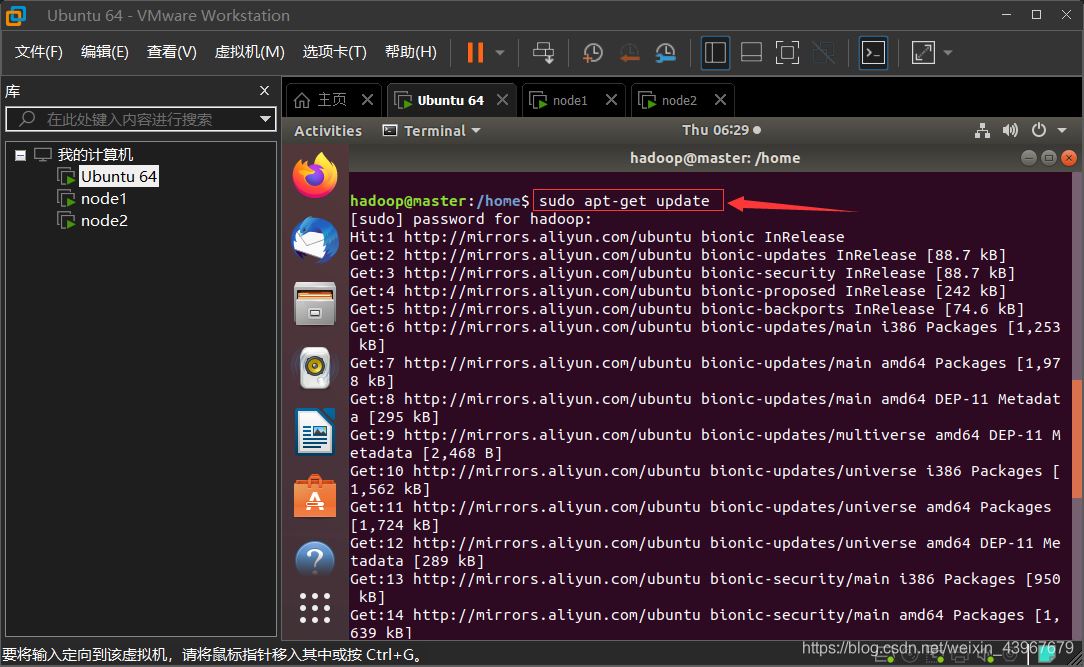
2.更新apt下載源(在master,node1,node2執行)
sudo apt-get update
截圖展示(以master為例)
3. 安裝SSH、配置SSH免密登錄 (在master,node1,node2執行)
1.安裝SSH
sudo apt-get install openssh-server
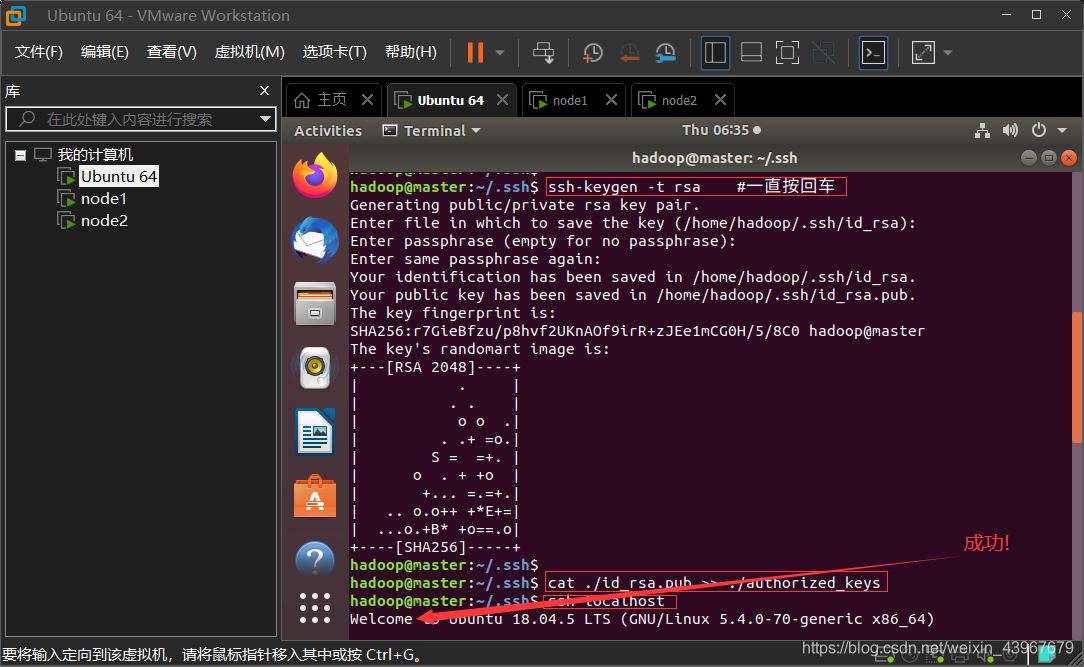
2.配置SSH免密登錄
ssh localhost exit cd ~/.ssh/ ssh-keygen -t rsa #一直按回車 cat ./id_rsa.pub >> ./authorized_keys
3.驗證免密
ssh localhost exit cd ~/.ssh/ ssh-keygen -t rsa #一直按回車 cat ./id_rsa.pub >> ./authorized_keys
截圖展示(以master為例)
4.安裝Java環境 (在master,node1,node2執行)
1.下載 JDK 環境包
sudo apt-get install default-jre default-jdk
2.配置環境變量文件
vim ~/.bashrc
3.在文件首行加入
export JAVA_HOME=/usr/lib/jvm/default-java
4,。讓環境變量生效
source ~/.bashrc
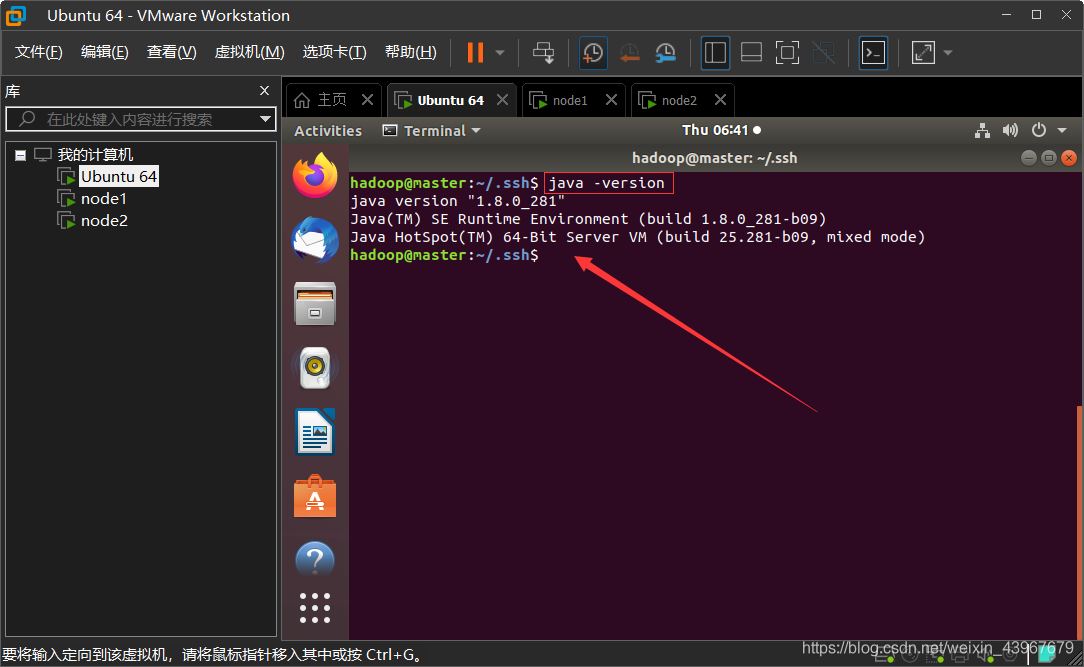
5.驗證
java -version
截圖展示(以master為例)
修改主機名(在master,node1,node2執行)
1.將文件中原有的主機名刪除,master中寫入master,node1中寫入node1,node2…(同理)
sudo vim /etc/hostname
重啟三個服務器
reboot
重啟成功後,再次連接會話,發現主機名改變瞭
截圖展示(以node1為例)
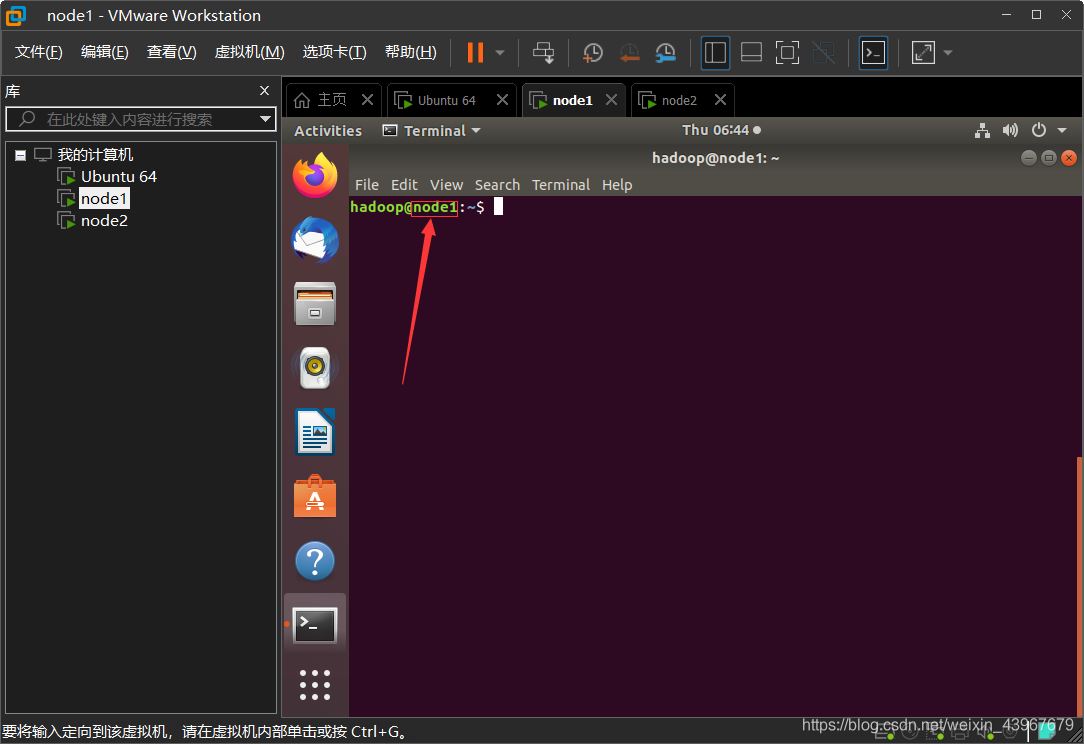
修改IP映射(在master,node1,node2執行)
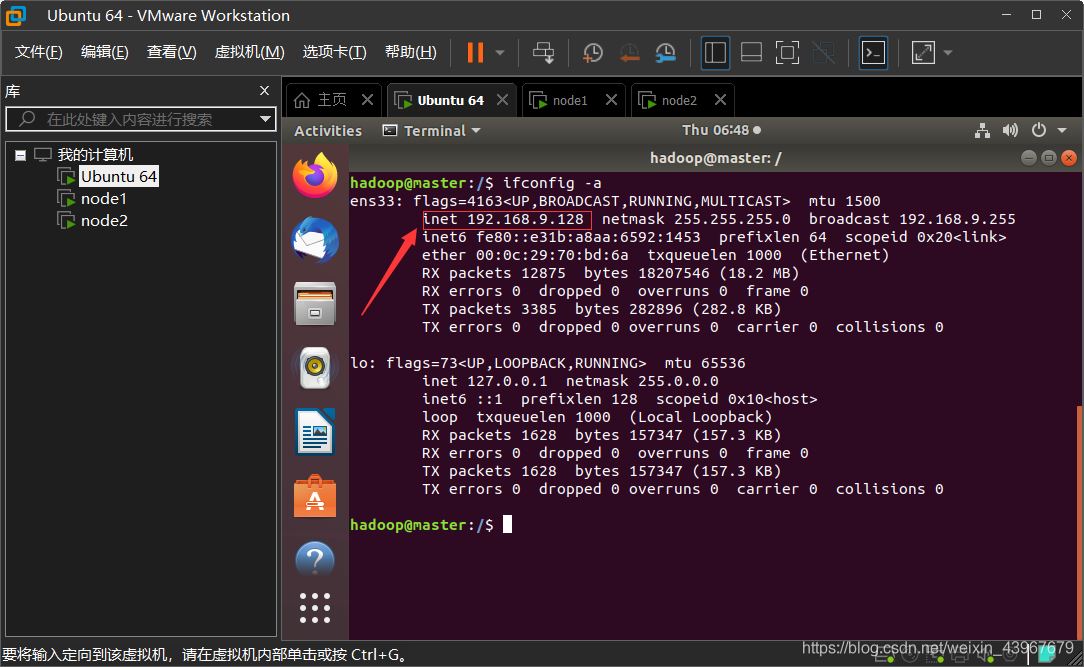
查看各個虛擬機的ip地址
ifconfig -a
如果有報錯,則下載 net-tools ,然後再運行即可看到
sudo apt install net-tools
如下圖,紅色方框內的就是 本臺虛擬機的 ip 地址
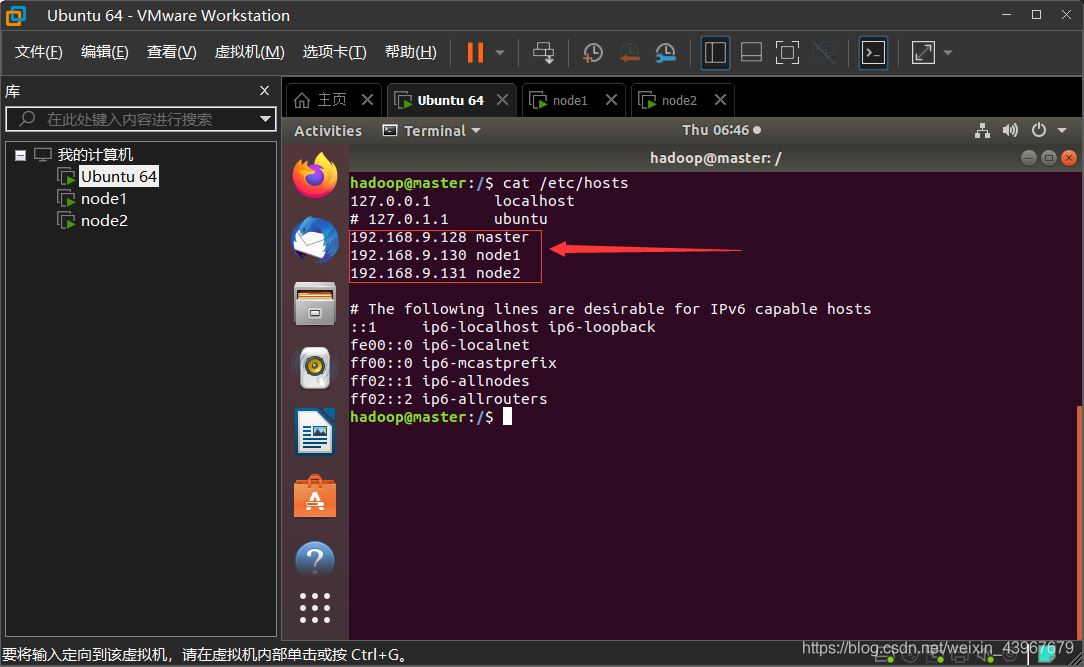
3臺虛擬機中都需要在 hosts 文件中加入對方的ip地址
sudo vim /etc/hosts
以master為例截圖展示
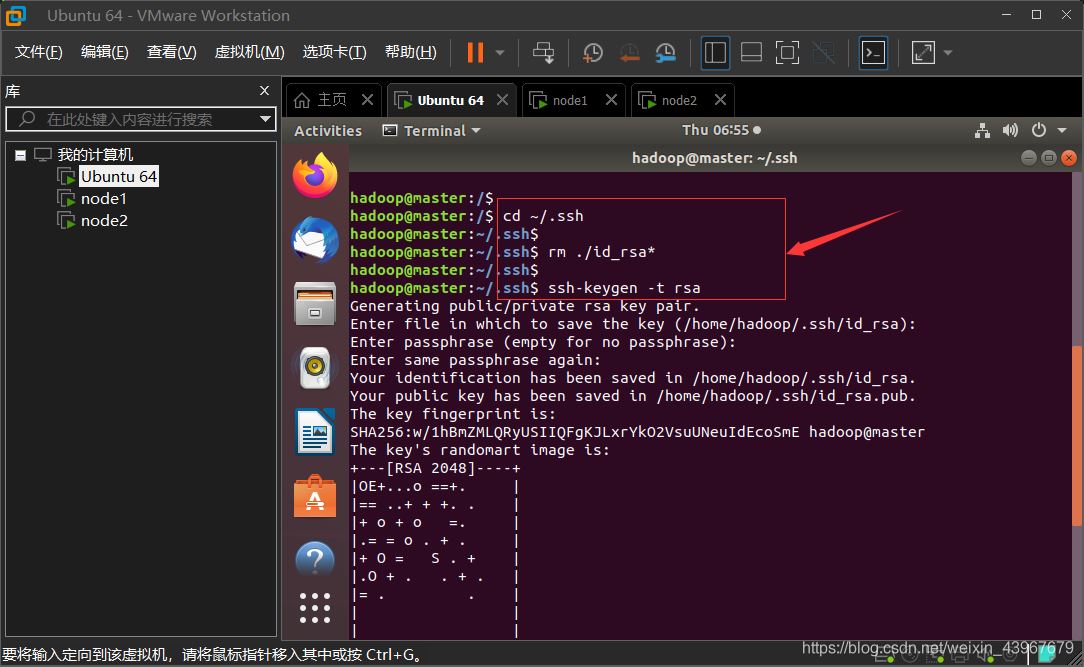
SSH免密登錄其他節點(在master上執行)
在Master上執行
cd ~/.ssh rm ./id_rsa* # 刪除之前生成的公匙(如果有) ssh-keygen -t rsa # 一直按回車就可以 cat ./id_rsa.pub >> ./authorized_keys scp ~/.ssh/id_rsa.pub hadoop@node1:/home/hadoop/ scp ~/.ssh/id_rsa.pub hadoop@node2:/home/hadoop/
在node1,node2都執行
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub # 用完就刪掉
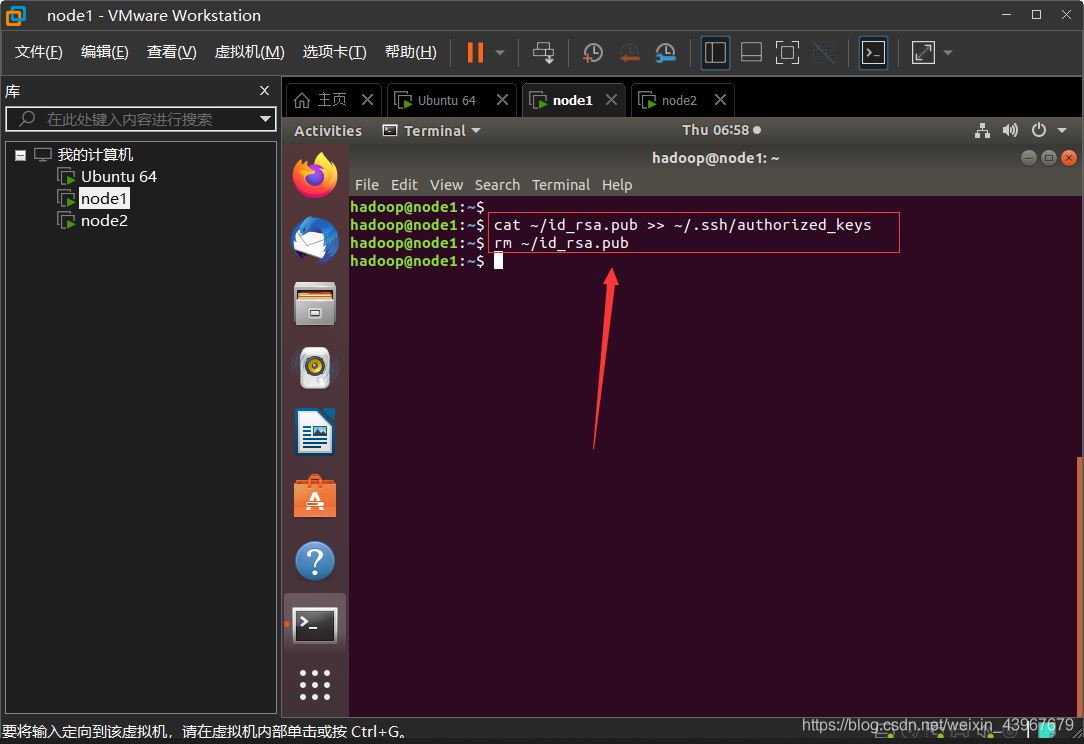
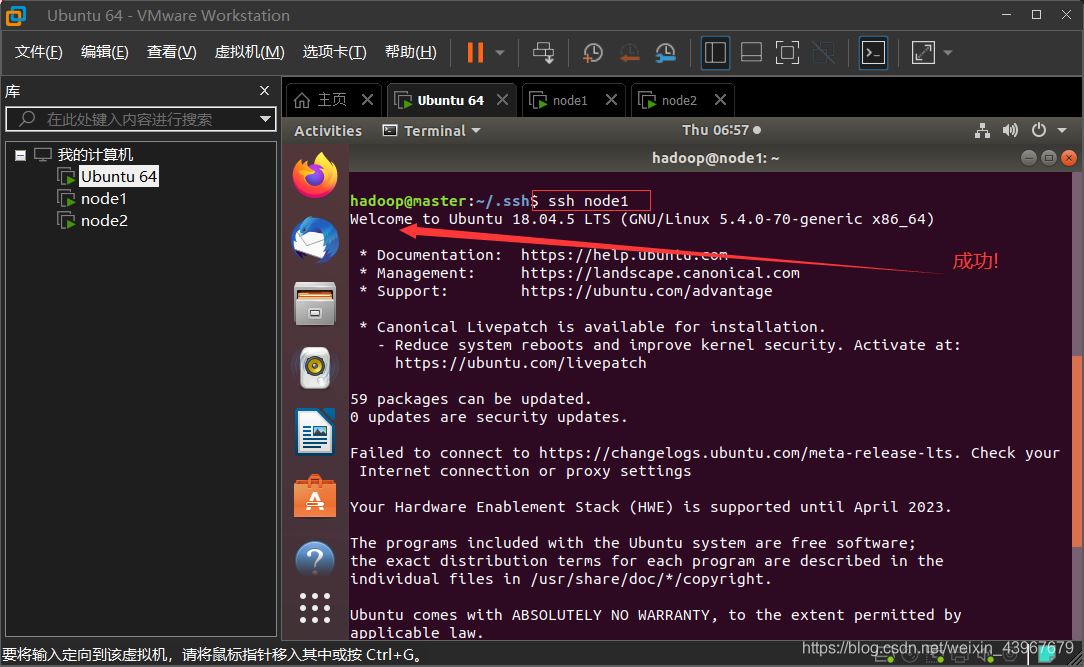
驗證免密登錄
ssh node1 exit ssh node2 exit
以master為例截圖展示
安裝hadoop3.2.1(在master中執行)
有些鏡像的下載網址失效瞭,這裡貼出官網的下載地址。
下載網址:hadoop3.2.1下載網址
下載好,之後通過VMware-Tools上傳到master的/home/hadoop中
解壓
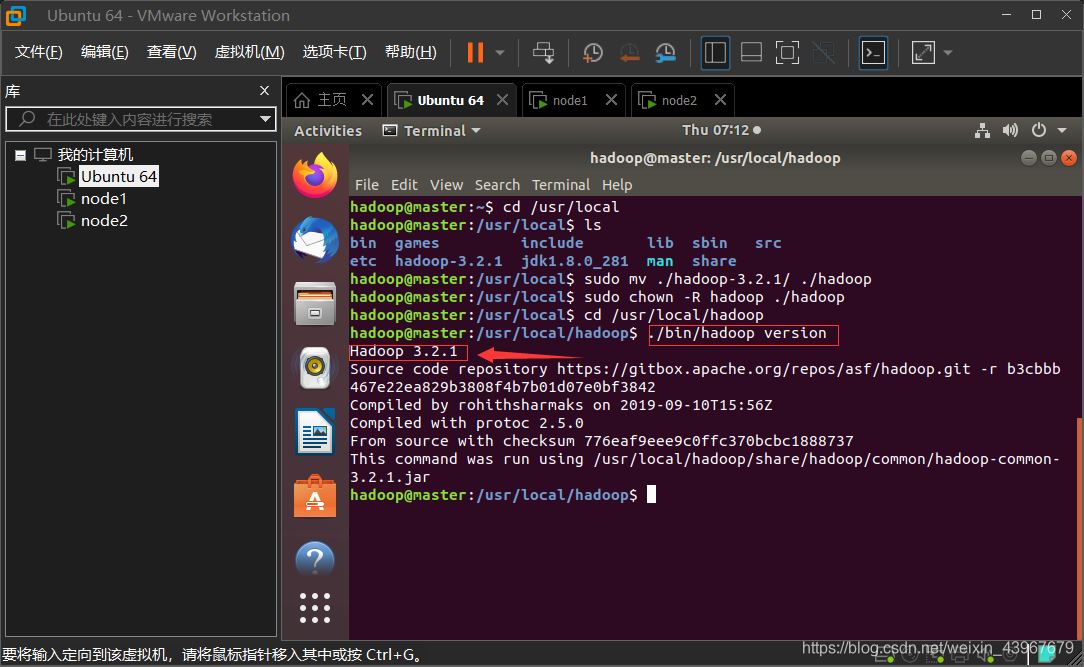
cd /home/hadoop sudo tar -zxf hadoop-3.2.1.tar.gz -C /usr/local #解壓 cd /usr/local/ sudo mv ./hadoop-3.2.1/ ./hadoop # 將文件夾名改為hadoop sudo chown -R hadoop ./hadoop # 修改文件權限
驗證
cd /usr/local/hadoop ./bin/hadoop version
配置hadoop環境(這一步需要很仔細)
配置環境變量
vim ~/.bashrc
在首行中寫入
export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使得配置生效
source ~/.bashrc
創建文件目錄(為後面的xml做準備)
cd /usr/local/hadoop mkdir dfs cd dfs mkdir name data tmp cd /usr/local/hadoop mkdir tmp
配置hadoop的java環境變量
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
兩個的首行都寫入
export JAVA_HOME=/usr/lib/jvm/default-java
(master中)配置nodes
cd /usr/local/hadoop/etc/hadoop
刪除掉原有的localhost,因為我們有2個node,就把這2個的名字寫入
vim workers
node1 node2
配置 core-site.xml
vim core-site.xml
因為我們隻有一個namenode,所以用fs.default.name,不采用fs.defalutFs
其次確保/usr/local/hadoop/tmp這個目錄存在
<configuration> <property> <name>fs.default.name</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>
配置 hdfs-site.xml
vim hdfs-site.xml
dfs.namenode.secondary.http-address確保端口不要和core-site.xml中端口一致導致占用
確保/usr/local/hadoop/dfs/name :/usr/local/hadoop/dfs/data 存在
因為我們隻有2個node,所以dfs.replication設置為2
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
配置mapred-site.xml
vim mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
配置 yarn-site.xml
vim yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
將hadoop壓縮
cd /usr/local tar -zcf ~/hadoop.master.tar.gz ./hadoop #壓縮 cd ~
復制到node1中
scp ./hadoop.master.tar.gz node1:/home/hadoop
復制到node2中
scp ./hadoop.master.tar.gz node2:/home/hadoop
在node1、node2上執行
解壓
sudo rm -r /usr/local/hadoop # 刪掉舊的(如果存在) sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local #解壓 sudo chown -R hadoop /usr/local/hadoop #修改權限
首次啟動需要先在 Master 節點執行 NameNode 的格式化,之後不需要
hdfs namenode -format
(註意:如果需要重新格式化 NameNode ,才需要先將原來 NameNode 和 DataNode 下的文件全部刪除!!!!!!!!!)
#看上面的文字,不要直接復制瞭 rm -rf $HADOOP_HOME/dfs/data/* rm -rf $HADOOP_HOME/dfs/name/*
啟動 (在master上執行)
start-all.sh mr-jobhistory-daemon.sh start historyserver
master中,出現Warning不影響
jps
運行截圖展示
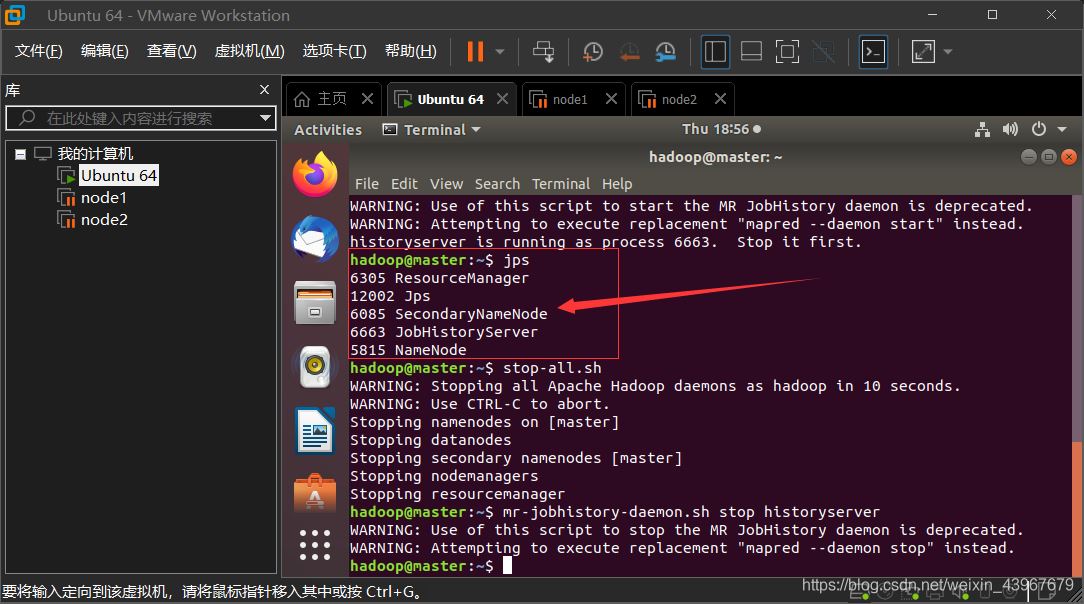
關閉hadoop集群(在master上執行)
stop-all.sh mr-jobhistory-daemon.sh stop historyserver
運行截圖展示
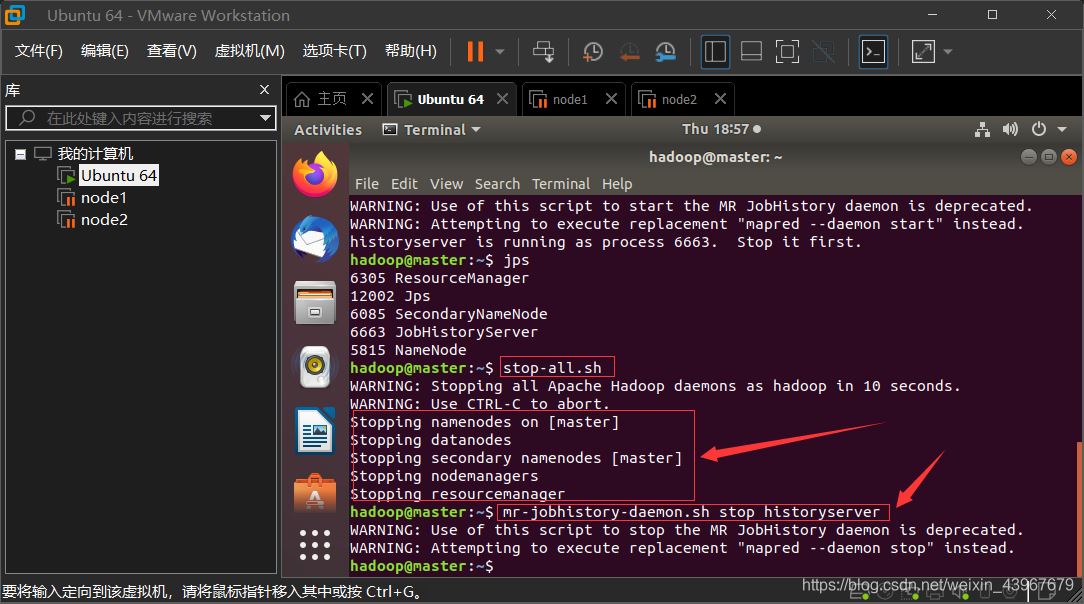
總結
搭建環境是一件比較耗時的操作,自己親手搭一遍,可能其中會遇到很多問題,比如說Linux的命令不熟悉,各種報錯,運行結果不對等,但是這些一般都可以在網上搜索到對應的解決方法。學習新技術就是要勇於試錯,然後歸納總結,這樣子會形成自己的一套解決問題的邏輯框架思維,也可以增強知識框架的形成,加油!
到此這篇關於VMware + Ubuntu18.04 搭建Hadoop集群環境的圖文教程的文章就介紹到這瞭,更多相關VMware Ubuntu搭建Hadoop集群內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found