MySQL底層數據結構選用B+樹的原因
我們都知道MySQL底層數據結構是選用的B+樹,那為什麼不用紅黑樹,或者其他什麼數據結構呢?
紅黑樹是一種自平衡二叉查找樹,Java8中的hashmap就用到紅黑樹來優化它的查詢效率,可見,紅黑樹的查詢效率還是比較高的,但是為什麼MySQL的底層不用紅黑樹而用B+數呢?
下圖是紅黑樹依次插入1,2,3,4,5,6之後的情況:
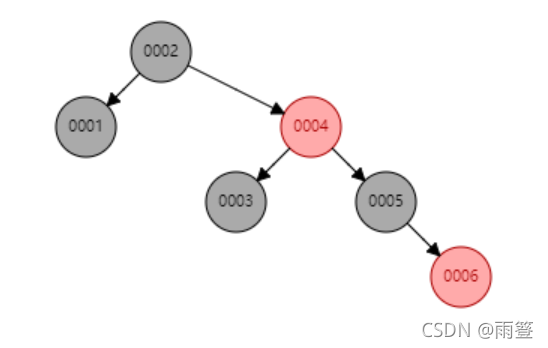
然後再在上面的紅黑樹中插入7:

可以看到,盡管紅黑樹經過瞭自平衡,數據整體仍然偏向樹的右側,如果繼續添加更多數據,添加的數據上百萬、千萬之後,樹的層級將會非常高,查詢時每多經過一層,就會多進行一次io,樹的層級多瞭之後查找效率就會很慢。這個時候可能就會有人問瞭,那為什麼不用平衡性更好的AVL樹呢?
AVL樹在一次插入1,2,3,4,5,6,7之後是這樣的:
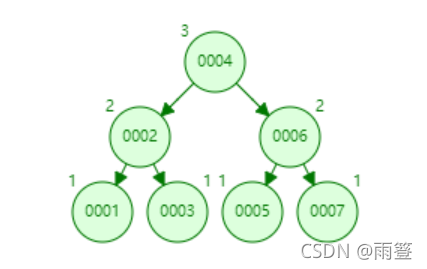
的確變順眼瞭很多,樹的層數也變少瞭,可AVL仍然沒有解決根本問題,當數據量達到百萬、千萬之後,樹的層數仍然會比較大,先不說AVL樹維護平衡所需的代價,單論AVL樹的層數就無法達到我們的要求。
那麼什麼樣的數據結構可以讓數據量達到百萬,千萬,甚至更大的體量時,層數仍然很小呢?很顯然,想要減少層數,就必須要讓每層儲存的數據數更多,二叉樹不管平衡性再好也隻能做到每個節點有兩個分叉,每層的數據量從數據結構被限制住瞭,那麼,我們就不能從二叉樹中選。所以這個時候B樹的優勢就體現出來瞭,B樹每個節點可以存儲多個元素,每個元素之間可以都可以擁有一個分叉,下圖是B樹每個節點最多可以存儲3個元素的情況:

可以看到樹的層級減小到兩層,如果說每次每個節點最多可以存儲的元素個數足夠大,那麼就算數據量達到上千萬的量級,也可以將樹的層級控制在一個可以接受的范圍內。
但B樹還有一個問題,下圖展示的是B樹層級達到三層時的情況:
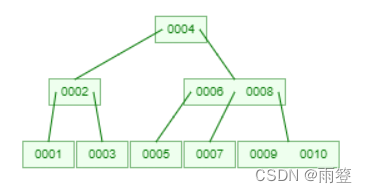
如果現在我需要取出5-10號元素,當我通過層層查詢,找到5號元素,然後發現其他元素不在這個節點,還需要通過局部中序遍歷查詢其他元素,找到7之後還需如此操作找到8,9,10,這又會增加io次數,所以也就有瞭B+樹。
B+樹是對B樹的優化,主要是從兩個地方進行優化的:
第一個優化是在每個葉子節點之間加上瞭一個雙向指針,指向相鄰節點,這樣就解決瞭剛才的范圍查詢問題,范圍查詢如果跨瞭多個節點,就可以通過這個雙向指針快速找到相鄰節點,而不需要通過局部的中序遍歷,從而減少瞭io次數。下圖演示的是B+樹:

但如果要找的元素不在葉子節點上呢?別擔心,B+樹的另一個優化就是的葉子節點包含瞭這顆樹的所有元素!B+樹的非葉子節點不再保存元素的data數據或者指針瞭,隻是作為冗餘的索引構成完整的B+樹來方便查詢。可以看到上圖的15號元素不僅僅存在於非葉子節點中,也存在於葉子節點中。這樣的設計雖然帶來瞭很多冗餘的索引,但是卻讓范圍查詢時不再需要向上查找非葉子節點瞭,而且每一層可以保存的索引數量變多瞭,讓數據庫每次io可以查詢到更多的索引元素,畢竟在正常情況下,數據占的空間比索引占的空間要大很多。(需要註意的是,InnoDB和MyISAM引擎雖然都是用的B+樹,但InnoDB的聚簇索引和數據是保存在一起的,而MyISAM是將聚簇索引和相應數據的指針保存在一起的,索引和數據是分開的。MyISAM引擎下的B+樹也隻有葉子節點才保存數據的指針)
由上面的分析我們可以知道,選用B+樹作為MySQL的底層是為瞭減少io次數,那我們為什麼不直接極端一點,使用hash來保存數據或者索引呢?其實MySQL確實支持hash類型的索引。

但是hash索引一般都不用,主要是因為hash索引的儲存的是hash碼,儲存的順序與索引列的值大小無關,所以隻有在進行精確查找時hash索引才能生效,范圍查詢時會進行全表掃描。同時,如果表中的數據量非常大的話,發生hash碰撞的次數會增多,單個查找的效率不一定比B+樹高。
簡單總結一下,B+樹相比其他樹來說,每個節點可以存儲更多元素,可以大大減少查詢時需要的io次數,非葉子節點不存儲數據或指針的設計可以提高每個節點存儲元素的數量,葉子節點具有的雙向指針可以提高范圍查詢的效率。
到此這篇關於MySQL底層數據結構選用B+樹的原因的文章就介紹到這瞭,更多相關MySQL B+樹內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!