Python爬蟲部分開篇概念講解
在學習Python爬蟲部分,需要你已經學過Python基礎和前端的相關知識。
開發環境介紹:
- window10 操作系統
- Python解釋器3.8
- 集成開發環境pycharm
數據的來源及作用
數據的來源有哪些?
- 用戶產生的數據: 百度指數
- 政府統計的數據: 政府數據
- 數據管理公司: 聚合數據
- 自己爬取的數據: 爬取網站上的某些視頻
數據的作用
- 數據分析
- 智能產品的練習數據
- 其他(比如買賣)
爬蟲的相關概念
a) 爬蟲的概念
爬蟲就是應用程序,從網上下載各種各樣的資源。
換句話說就是使用編程語言編寫一個用於爬蟲web或者app的數據應用程序。
怎麼爬取數據呢?
- 找到要爬取的目標網站,發起請求
- 分析url是如何變化的和提取有用的url
- 提取有用的信息
爬蟲什麼數據都可以爬嗎?
當然不能,需要遵守一定的規則和協議
可以看一下京東的:
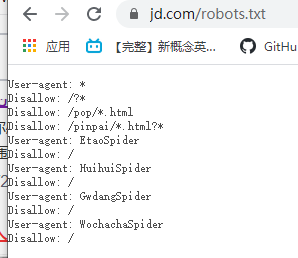
有些是允許的,有些是不允許的。
b) 爬蟲分類
- 通用爬蟲
百度等搜索引擎,從一些初始的URL擴展到整個網站,主要為門戶站點搜索引起和大型網站服務采集數據
- 聚焦網站爬蟲
主題網絡爬蟲,選擇性爬取根據需求相關的頁面的網絡爬蟲
- 增量式網絡爬蟲
對已經下載的頁面采取更新知識和隻爬新產生的。
c) 爬蟲的原理
- 通用的爬蟲原理
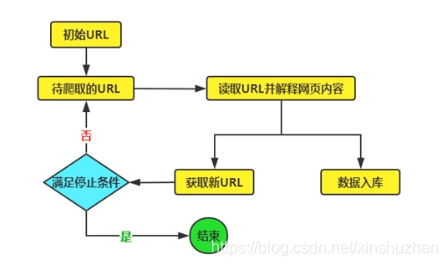
- 聚焦網絡爬蟲原理
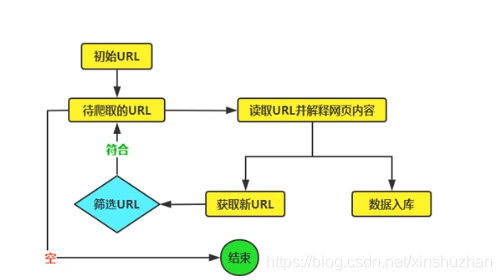
d) 各種語言寫爬蟲的對比
- php對多線程,異步支持不是很友好,並發能力弱。速度和效率低
- java: 代碼量大,而且重構成本比較高,任何改動都會導致大量的改動,而爬蟲需要經常修改采集代碼
- Python: 開發效率高,代碼簡潔,支持的模塊多,和HTTP請求和html解析模塊非常豐富,還有scrapy,scrapy-redis框架,讓開發爬蟲更簡單。
到此這篇關於Python爬蟲部分開篇示例講解的文章就介紹到這瞭,更多相關Python爬蟲部分開篇示例講解內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found