Pytorch 使用tensor特定條件判斷索引
torch.where() 用於將兩個broadcastable的tensor組合成新的tensor,類似於c++中的三元操作符“?:”
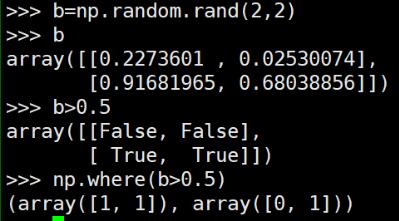
區別於python numpy中的where()直接可以找到特定條件元素的index
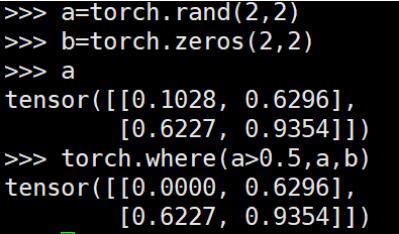
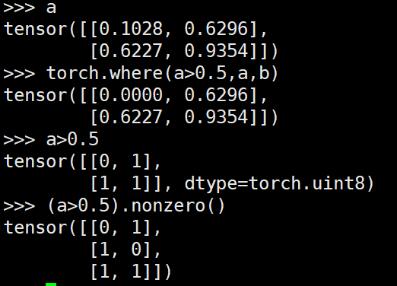
想要實現numpy中where()的功能,可以借助nonzero()
對應numpy中的where()操作效果:
補充:Pytorch torch.Tensor.detach()方法的用法及修改指定模塊權重的方法
detach
detach的中文意思是分離,官方解釋是返回一個新的Tensor,從當前的計算圖中分離出來

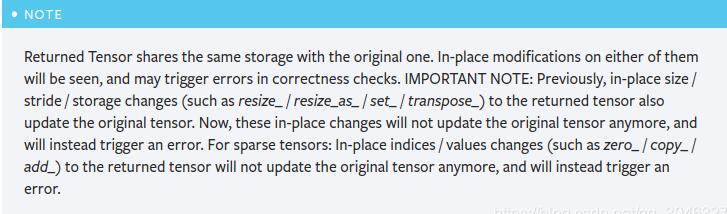
需要註意的是,返回的Tensor和原Tensor共享相同的存儲空間,但是返回的 Tensor 永遠不會需要梯度
import torch as t a = t.ones(10,) b = a.detach() print(b) tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
那麼這個函數有什麼作用?
–假如A網絡輸出瞭一個Tensor類型的變量a, a要作為輸入傳入到B網絡中,如果我想通過損失函數反向傳播修改B網絡的參數,但是不想修改A網絡的參數,這個時候就可以使用detcah()方法
a = A(input) a = detach() b = B(a) loss = criterion(b, target) loss.backward()
來看一個實際的例子:
import torch as t x = t.ones(1, requires_grad=True) x.requires_grad #True y = t.ones(1, requires_grad=True) y.requires_grad #True x = x.detach() #分離之後 x.requires_grad #False y = x+y #tensor([2.]) y.requires_grad #我還是True y.retain_grad() #y不是葉子張量,要加上這一行 z = t.pow(y, 2) z.backward() #反向傳播 y.grad #tensor([4.]) x.grad #None
以上代碼就說明瞭反向傳播到y就結束瞭,沒有到達x,所以x的grad屬性為None
既然談到瞭修改模型的權重問題,那麼還有一種情況是:
–假如A網絡輸出瞭一個Tensor類型的變量a, a要作為輸入傳入到B網絡中,如果我想通過損失函數反向傳播修改A網絡的參數,但是不想修改B網絡的參數,這個時候又應該怎麼辦瞭?
這時可以使用Tensor.requires_grad屬性,隻需要將requires_grad修改為False即可.
for param in B.parameters(): param.requires_grad = False a = A(input) b = B(a) loss = criterion(b, target) loss.backward()
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- None Found