python爬蟲爬取bilibili網頁基本內容
用爬蟲爬取bilibili網站排行榜遊戲類的所有名稱及鏈接:
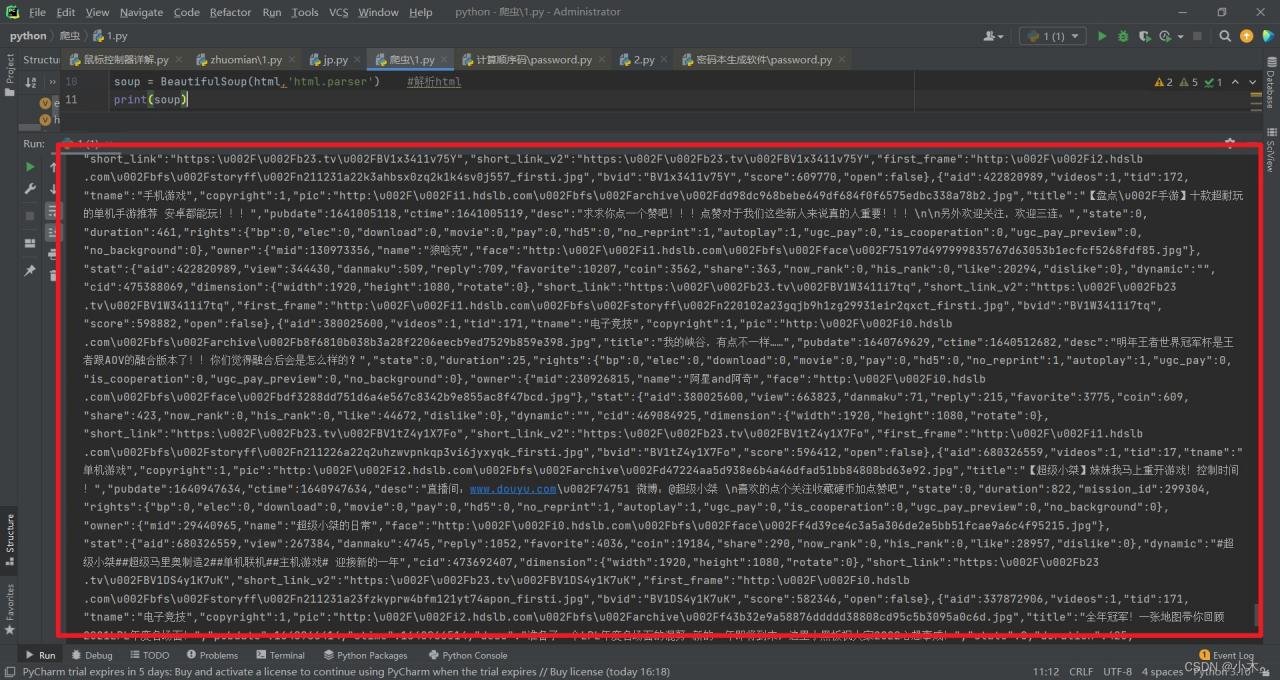
導入requests、BeautifulSoup
import requests from bs4 import BeautifulSoup
然後我們需要插入網站鏈接並且要解析網站並打印出來:
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #當前網站鏈接
html = e.content
soup = BeautifulSoup(html,'html.parser') #解析html
print(soup)
我們可以看到密密麻麻的代碼函數,但不太簡潔明瞭,我們去優化一下
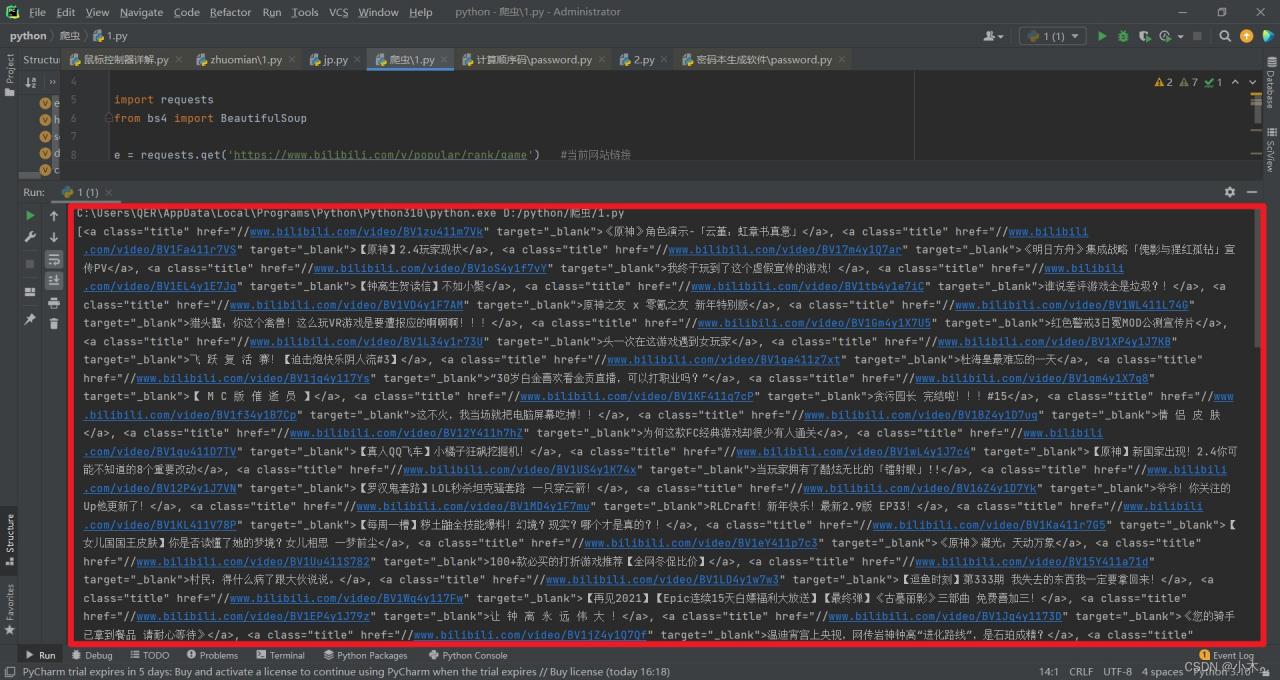
繼續插入如下代碼這個代碼是可以爬取我們想要的類,可以更簡介的簡化代碼
div_people_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul類class為rank-list下的數據
可以看到還是不夠簡介:

繼續插入如下代碼:
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a類class為title下的數據
可以看到鏈接及主題都提取出來瞭,但還是有瑕疵:
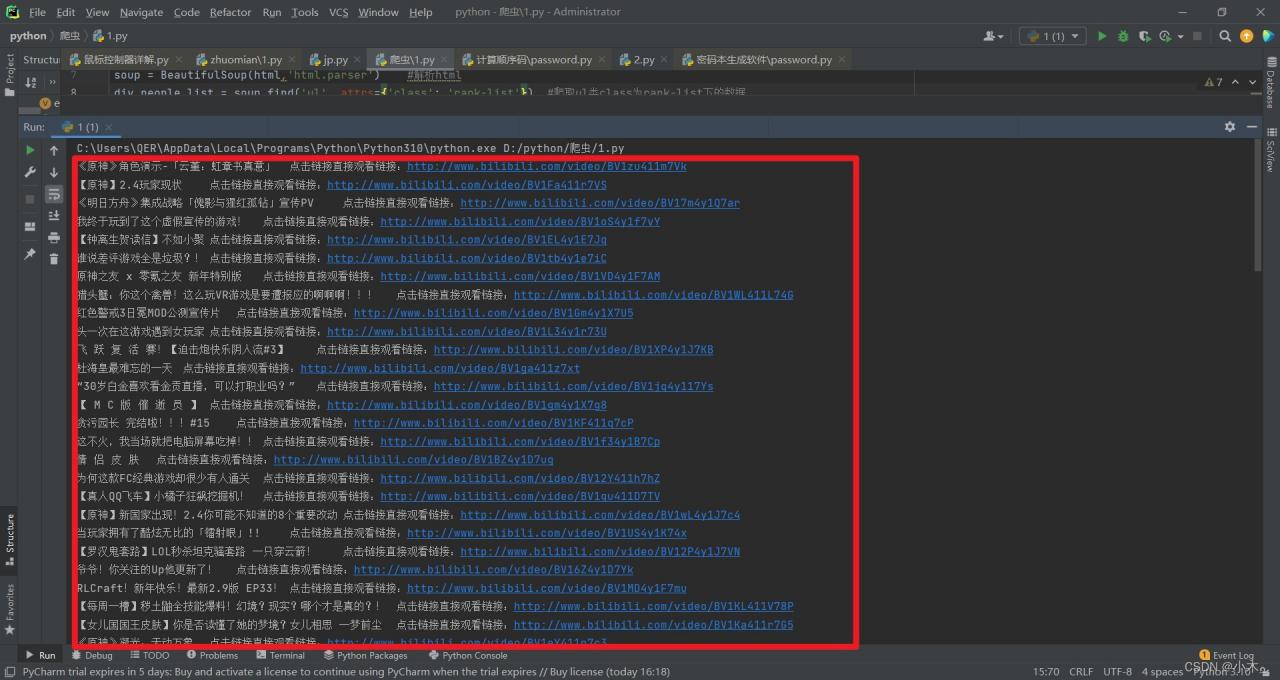
我們加入這行代碼挨個打印並提取標題及鏈接,由於鏈接提取出來的是//www.bilibili.com/video/BV1yZ4y1D7ef
前面沒有http:點擊進去會出現錯誤,所有我們需要在前面加入http:進行連接在一起打印
for t in ca_s:
url = t['href']
name = t.get_text()
print(name+'\t點擊鏈接直接觀看鏈接:'+f'http:{url}')
可以看到我們的標題及連接都爬取出來瞭
完整代碼:
import requests
from bs4 import BeautifulSoup
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #當前網站鏈接
html = e.content
soup = BeautifulSoup(html,'html.parser') #解析html
div_people_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul類class為rank-list下的數據
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a類class為title下的數據
#挨個傳輸到t,然後打印數據
for t in ca_s:
url = t['href']
name = t.get_text()
print(name+'\t點擊鏈接直接觀看鏈接:'+f'http:{url}')
到此這篇關於python爬蟲爬取bilibili網頁基本內容的文章就介紹到這瞭,更多相關python爬取bilibili網頁內容內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python beautifulsoup4 模塊詳情
- python爬蟲beautifulsoup庫使用操作教程全解(python爬蟲基礎入門)
- Python爬蟲網頁元素定位術
- Python使用Beautiful Soup實現解析網頁
- Python BautifulSoup 節點信息