Pytorch寫數字識別LeNet模型
LeNet網絡
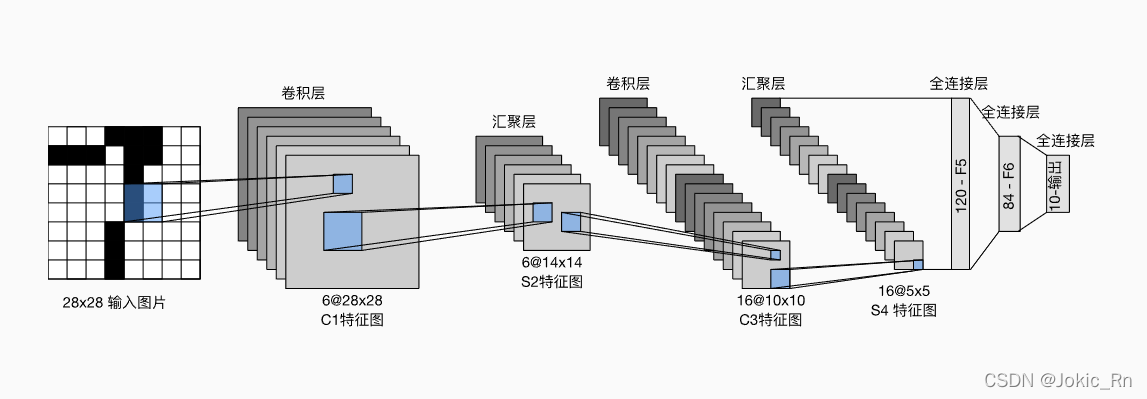
LeNet網絡過卷積層時候保持分辨率不變,過池化層時候分辨率變小。實現如下
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
import torch
from torch.utils.data import DataLoader
import torch.nn as nn
import numpy as np
import tqdm as tqdm
class LeNet(nn.Module):
def __init__(self) -> None:
super().__init__()
self.sequential = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16*25,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10))
def forward(self,x):
return self.sequential(x)
class MLP(nn.Module):
def __init__(self) -> None:
super().__init__()
self.sequential = nn.Sequential(nn.Flatten(),
nn.Linear(28*28,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10))
def forward(self,x):
return self.sequential(x)
epochs = 15
batch = 32
lr=0.9
loss = nn.CrossEntropyLoss()
model = LeNet()
optimizer = torch.optim.SGD(model.parameters(),lr)
device = torch.device('cuda')
root = r"./"
trans_compose = transforms.Compose([transforms.ToTensor(),
])
train_data = torchvision.datasets.MNIST(root,train=True,transform=trans_compose,download=True)
test_data = torchvision.datasets.MNIST(root,train=False,transform=trans_compose,download=True)
train_loader = DataLoader(train_data,batch_size=batch,shuffle=True)
test_loader = DataLoader(test_data,batch_size=batch,shuffle=False)
model.to(device)
loss.to(device)
# model.apply(init_weights)
for epoch in range(epochs):
train_loss = 0
test_loss = 0
correct_train = 0
correct_test = 0
for index,(x,y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
predict = model(x)
L = loss(predict,y)
optimizer.zero_grad()
L.backward()
optimizer.step()
train_loss = train_loss + L
correct_train += (predict.argmax(dim=1)==y).sum()
acc_train = correct_train/(batch*len(train_loader))
with torch.no_grad():
for index,(x,y) in enumerate(test_loader):
[x,y] = [x.to(device),y.to(device)]
predict = model(x)
L1 = loss(predict,y)
test_loss = test_loss + L1
correct_test += (predict.argmax(dim=1)==y).sum()
acc_test = correct_test/(batch*len(test_loader))
print(f'epoch:{epoch},train_loss:{train_loss/batch},test_loss:{test_loss/batch},acc_train:{acc_train},acc_test:{acc_test}')
訓練結果
epoch:12,train_loss:2.235553741455078,test_loss:0.3947642743587494,acc_train:0.9879833459854126,acc_test:0.9851238131523132
epoch:13,train_loss:2.028963804244995,test_loss:0.3220392167568207,acc_train:0.9891499876976013,acc_test:0.9875199794769287
epoch:14,train_loss:1.8020273447036743,test_loss:0.34837451577186584,acc_train:0.9901833534240723,acc_test:0.98702073097229
泛化能力測試
找瞭一張圖片,將其分割成隻含一個數字的圖片進行測試

images_np = cv2.imread("/content/R-C.png",cv2.IMREAD_GRAYSCALE)
h,w = images_np.shape
images_np = np.array(255*torch.ones(h,w))-images_np#圖片反色
images = Image.fromarray(images_np)
plt.figure(1)
plt.imshow(images)
test_images = []
for i in range(10):
for j in range(16):
test_images.append(images_np[h//10*i:h//10+h//10*i,w//16*j:w//16*j+w//16])
sample = test_images[77]
sample_tensor = torch.tensor(sample).unsqueeze(0).unsqueeze(0).type(torch.FloatTensor).to(device)
sample_tensor = torch.nn.functional.interpolate(sample_tensor,(28,28))
predict = model(sample_tensor)
output = predict.argmax()
print(output)
plt.figure(2)
plt.imshow(np.array(sample_tensor.squeeze().to('cpu')))
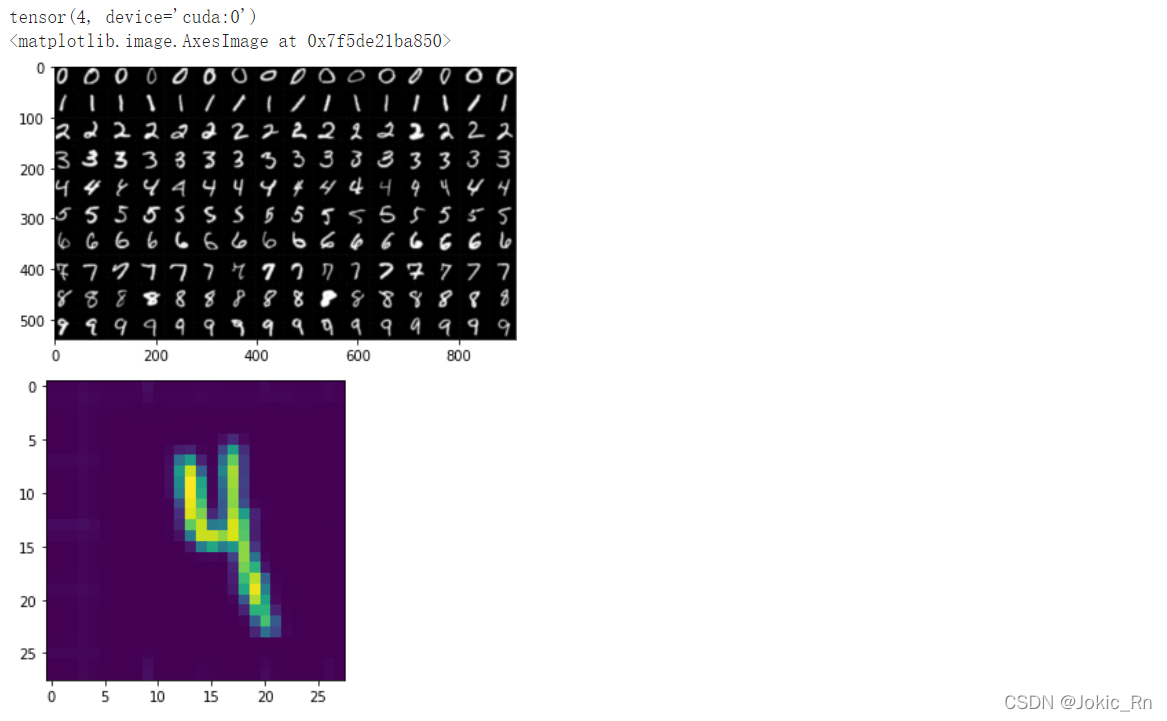
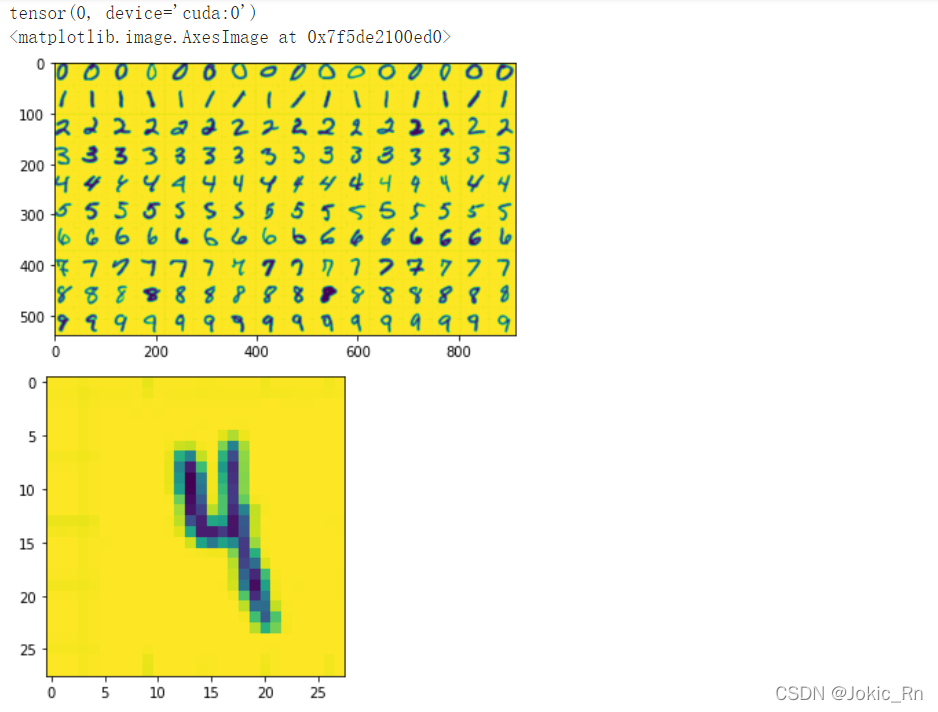
此時預測結果為4,預測正確。從這段代碼中可以看到有一個反色的步驟,若不反色,結果會受到影響,如下圖所示,預測為0,錯誤。
模型用於輸入的圖片是單通道的黑白圖片,這裡由於可視化出現瞭黃色,但實際上是黑白色,反色操作說明瞭數據的預處理十分的重要,很多數據如果是不清理過是無法直接用於推理的。
將所有用來泛化性測試的圖片進行準確率測試:
correct = 0
i = 0
cnt = 1
for sample in test_images:
sample_tensor = torch.tensor(sample).unsqueeze(0).unsqueeze(0).type(torch.FloatTensor).to(device)
sample_tensor = torch.nn.functional.interpolate(sample_tensor,(28,28))
predict = model(sample_tensor)
output = predict.argmax()
if(output==i):
correct+=1
if(cnt%16==0):
i+=1
cnt+=1
acc_g = correct/len(test_images)
print(f'acc_g:{acc_g}')
如果不反色,acc_g=0.15
acc_g:0.50625
到此這篇關於Pytorch寫數字識別LeNet模型的文章就介紹到這瞭,更多相關Pytorch寫數字識別LeNet模型內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Pytorch實現圖像識別之數字識別(附詳細註釋)
- Pytorch相關知識介紹與應用
- Python深度學習pytorch卷積神經網絡LeNet
- Pytorch中求模型準確率的兩種方法小結
- 關於Pytorch中模型的保存與遷移問題