ConcurrentHashMap是如何保證線程安全
ConcurrentHashMap 是 HashMap 的多線程版本,HashMap 在並發操作時會有各種問題,比如死循環問題、數據覆蓋等問題。而這些問題,隻要使用 ConcurrentHashMap 就可以完美解決瞭,那問題來瞭,ConcurrentHashMap 是如何保證線程安全的?它的底層又是如何實現的?接下來我們一起來看。
JDK 1.7 底層實現
ConcurrentHashMap 在不同的 JDK 版本中實現是不同的,在 JDK 1.7 中它使用的是數組加鏈表的形式實現的,而數組又分為:大數組 Segment 和小數組 HashEntry。 大數組 Segment 可以理解為 MySQL 中的數據庫,而每個數據庫(Segment)中又有很多張表 HashEntry,每個 HashEntry 中又有多條數據,這些數據是用鏈表連接的,如下圖所示:
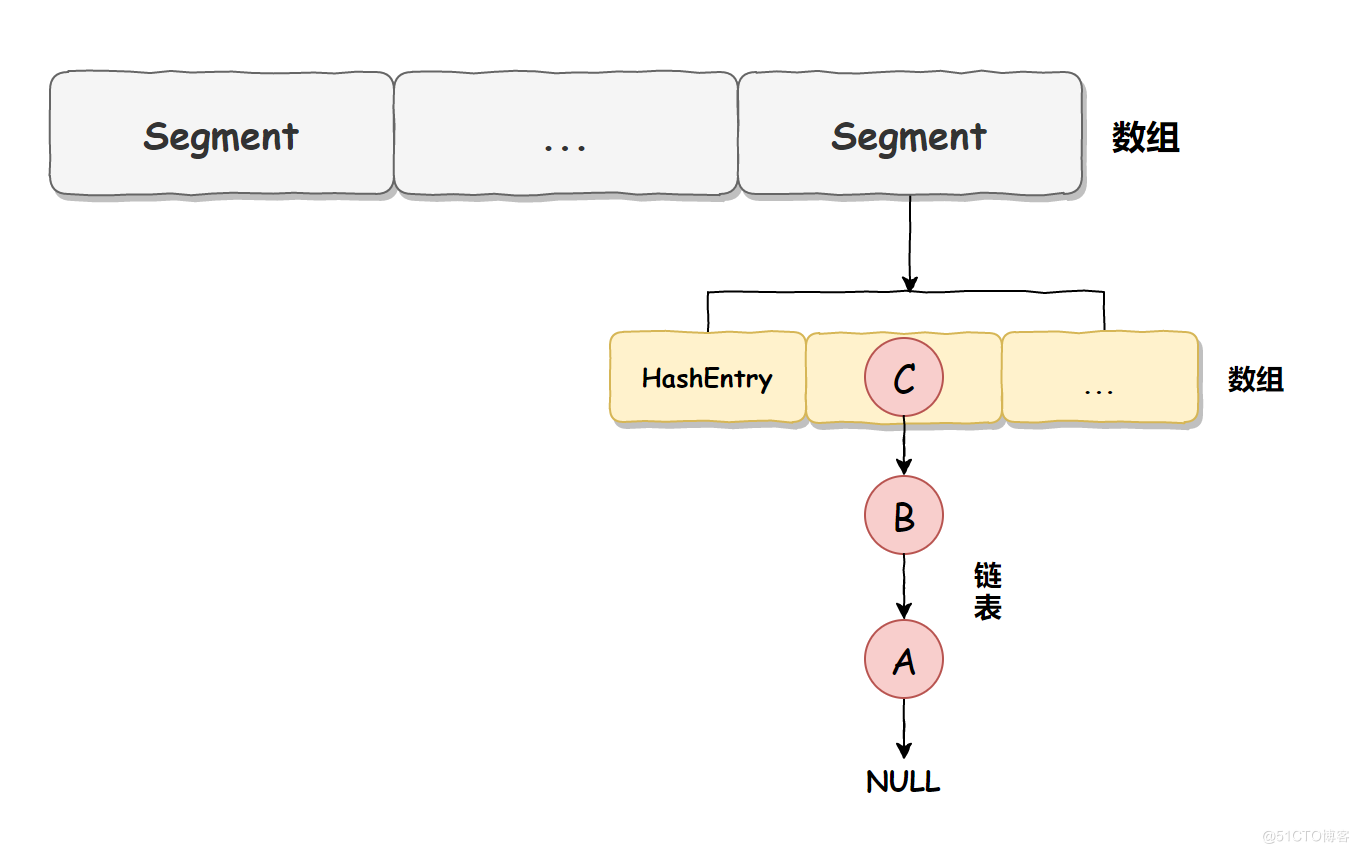
JDK 1.7 線程安全實現
瞭解瞭 ConcurrentHashMap 的底層實現,再看它的線程安全實現就比較簡單瞭。
接下來,我們通過添加元素 put 方法,來看 JDK 1.7 中 ConcurrentHashMap 是如何保證線程安全的,具體實現源碼如下:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往該 Segment 寫入前,先確保獲取到鎖
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// Segment 內部數組
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有值...
}
else {
// 放置 HashEntry 到特定位置,如果超過閾值則進行 rehash
// 忽略其他代碼...
}
}
} finally {
// 釋放鎖
unlock();
}
return oldValue;
}
從上述源碼我們可以看出,Segment 本身是基於 ReentrantLock 實現的加鎖和釋放鎖的操作,這樣就能保證多個線程同時訪問 ConcurrentHashMap 時,同一時間隻有一個線程能操作相應的節點,這樣就保證瞭 ConcurrentHashMap 的線程安全瞭。
也就是說 ConcurrentHashMap 的線程安全是建立在 Segment 加鎖的基礎上的,所以我們把它稱之為分段鎖或片段鎖,如下圖所示:
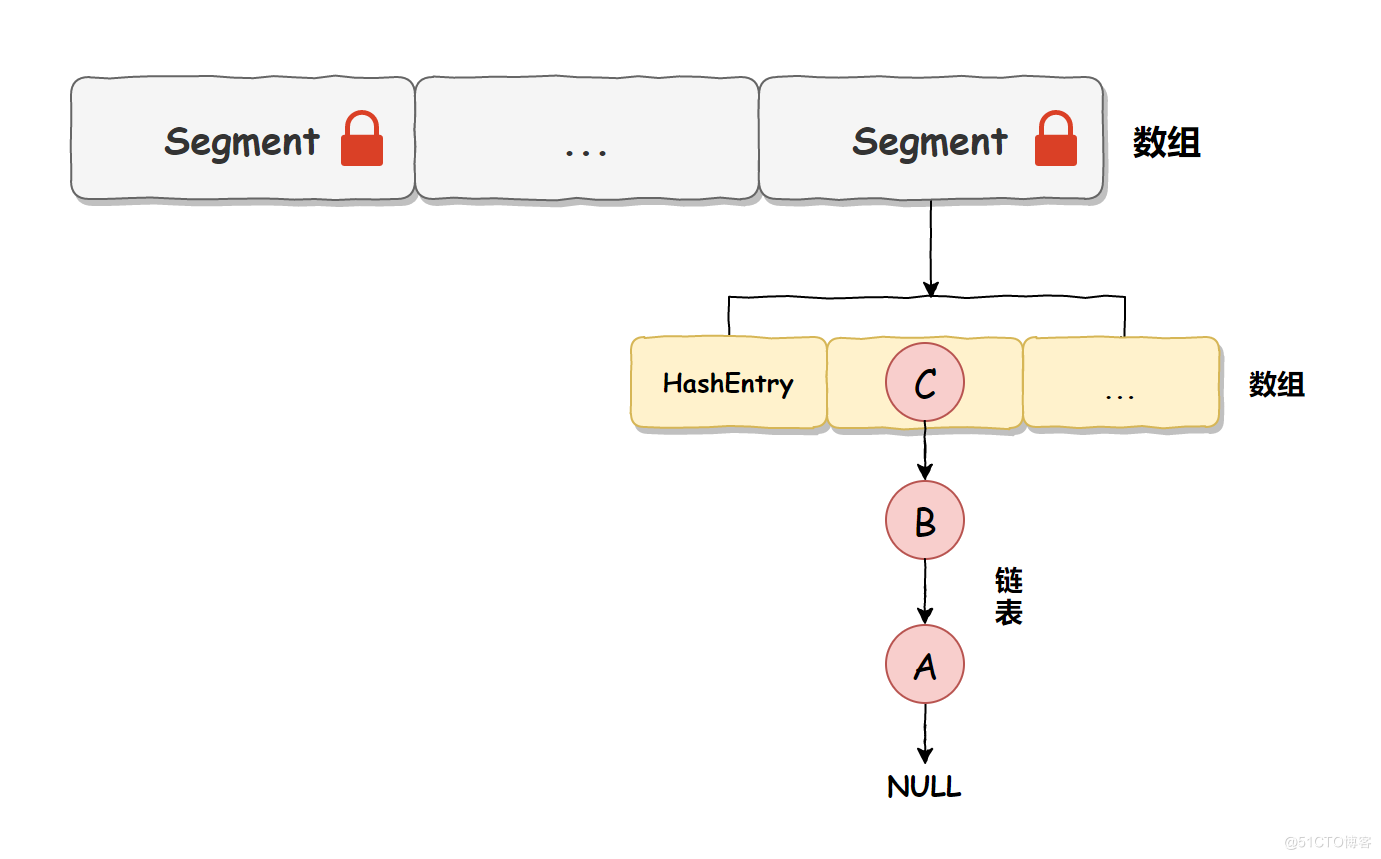
JDK 1.8 底層實現
在 JDK 1.7 中,ConcurrentHashMap 雖然是線程安全的,但因為它的底層實現是數組
DK 1.7 中,ConcurrentHashMap 雖然是線程安全的,但因為它的底層實現是數組 + 鏈表的形式,所以在數據比較多的情況下訪問是很慢的,因為要遍歷整個鏈表,而 JDK 1.8 則使用瞭數組 + 鏈表/紅黑樹的方式優化瞭 ConcurrentHashMap 的實現,具體實現結構如下:
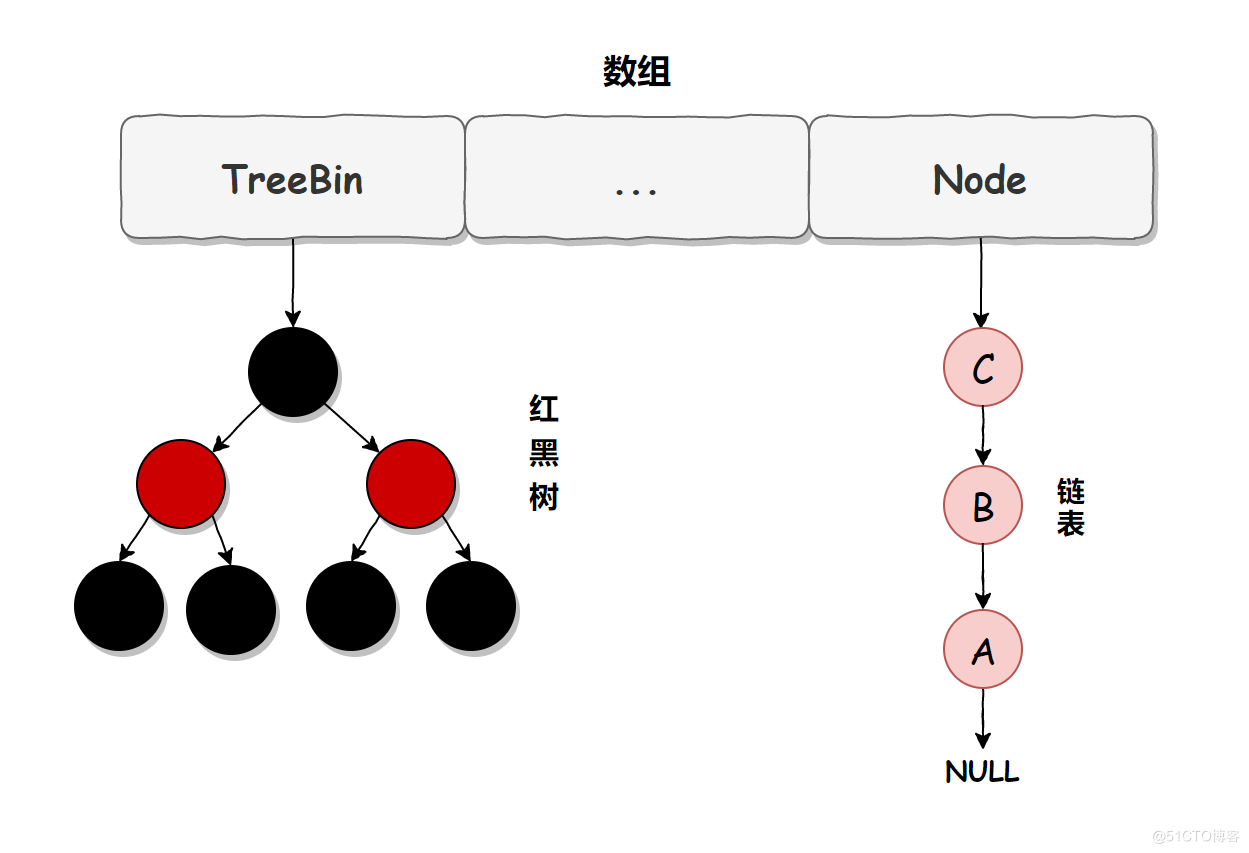
鏈表升級為紅黑樹的規則:當鏈表長度大於 8,並且數組的長度大於 64 時,鏈表就會升級為紅黑樹的結構。
PS:ConcurrentHashMap 在 JDK 1.8 雖然保留瞭 Segment 的定義,但這僅僅是為瞭保證序列化時的兼容性,不再有任何結構上的用處瞭。
JDK 1.8 線程安全實現
在 JDK 1.8 中 ConcurrentHashMap 使用的是 CAS
DK 1.8 中 ConcurrentHashMap 使用的是 CAS + volatile 或 synchronized 的方式來保證線程安全的,它的核心實現源碼如下:
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 節點為空
// 利用 CAS 去進行無鎖線程安全操作,如果 bin 是空的
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
// 細粒度的同步修改操作...
}
}
// 如果超過閾值,升級為紅黑樹
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
從上述源碼可以看出,在 JDK 1.8 中,添加元素時首先會判斷容器是否為空,如果為空則使用 volatile 加 CAS 來初始化。如果容器不為空則根據存儲的元素計算該位置是否為空,如果為空則利用 CAS 設置該節點;如果不為空則使用 synchronize 加鎖,遍歷桶中的數據,替換或新增節點到桶中,最後再判斷是否需要轉為紅黑樹,這樣就能保證並發訪問時的線程安全瞭。
我們把上述流程簡化一下,我們可以簡單的認為在 JDK 1.8 中,ConcurrentHashMap 是在頭節點加鎖來保證線程安全的,鎖的粒度相比 Segment 來說更小瞭,發生沖突和加鎖的頻率降低瞭,並發操作的性能就提高瞭。而且 JDK 1.8 使用的是紅黑樹優化瞭之前的固定鏈表,那麼當數據量比較大的時候,查詢性能也得到瞭很大的提升,從之前的 O(n) 優化到瞭 O(logn) 的時間復雜度,具體加鎖示意圖如下:
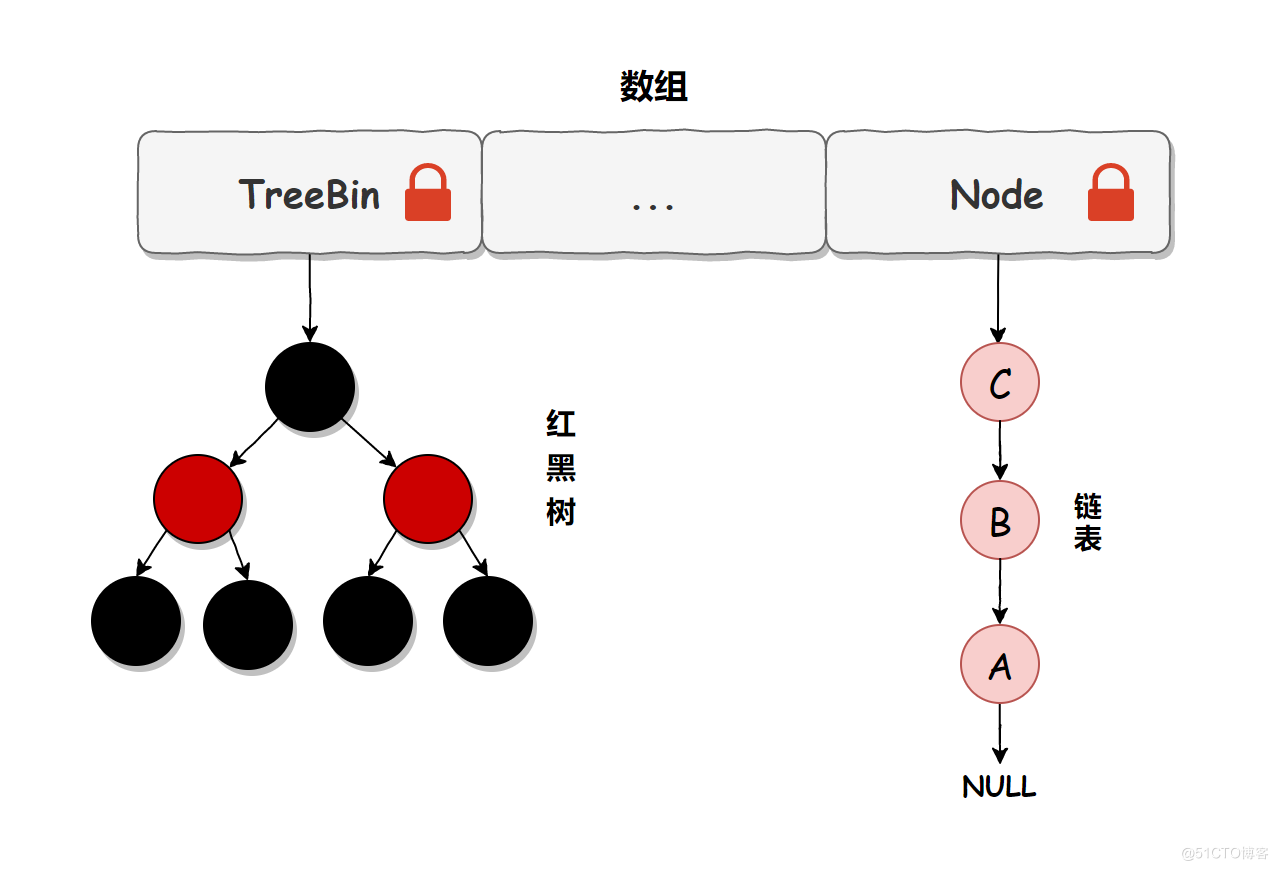
總結
ConcurrentHashMap 在 JDK 1.7 時使用的是數據加鏈表的形式實現的,其中數組分為兩類:大數組 Segment 和小數組 HashEntry,而加鎖是通過給 Segment 添加 ReentrantLock 鎖來實現線程安全的。而 JDK 1.8 中 ConcurrentHashMap 使用的是數組+鏈表/紅黑樹的方式實現的,它是通過 CAS 或 synchronized 來實現線程安全的,並且它的鎖粒度更小,查詢性能也更高。
到此這篇關於ConcurrentHashMap是如何保證線程安全的文章就介紹到這瞭,更多相關ConcurrentHashMap線程安全內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Java源碼解析之ConcurrentHashMap
- 淺談Java源碼ConcurrentHashMap
- Java ConcurrentHashMap用法案例詳解
- HashMap在JDK7與JDK8中的實現過程解析
- JDK1.8中的ConcurrentHashMap使用及場景分析