用Python爬取2022春節檔電影信息
前提條件
熟悉HTML基礎語句
熟悉Xpath基礎語句
相關介紹
Python是一種跨平臺的計算機程序設計語言。是一個高層次的結合瞭解釋性、編譯性、互動性和面向對象的腳本語言。最初被設計用於編寫自動化腳本(shell),隨著版本的不斷更新和語言新功能的添加,越多被用於獨立的、大型項目的開發。Requests是一個很實用的Python HTTP客戶端庫。Pandas是一個Python軟件包,提供快速,靈活和可表達的數據結構,旨在使結構化(表格,多維,潛在異構)和時間序列數據的處理既簡單又直觀。Time是python標準庫,無需額外下載,主要用於處理時間問題。Lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的數據;lxml和正則一樣,也是用C語言實現的,是一款高性能的python HTML、XML解析器,也可以利用XPath語法,來定位特定的元素及節點信息。
HTML是超文本標記語言,主要用於顯示數據,他的焦點是數據的外觀XML是可擴展標記語言,主要用於傳輸和存儲數據,他的焦點是數據的內容
實驗目標:Python爬取2022春節檔電影信息
實驗環境
Python 3.x (面向對象的高級語言)
Resquest 2.14.2 (python第三方庫)
Pandas 1.1.0(python第三方庫)
Time (python標準庫)
Lxml(python第三方庫)
具體步驟
目標網站
https://movie.douban.com/cinema/later/shenzhen/
分析網站
按F12打開瀏覽器操作臺
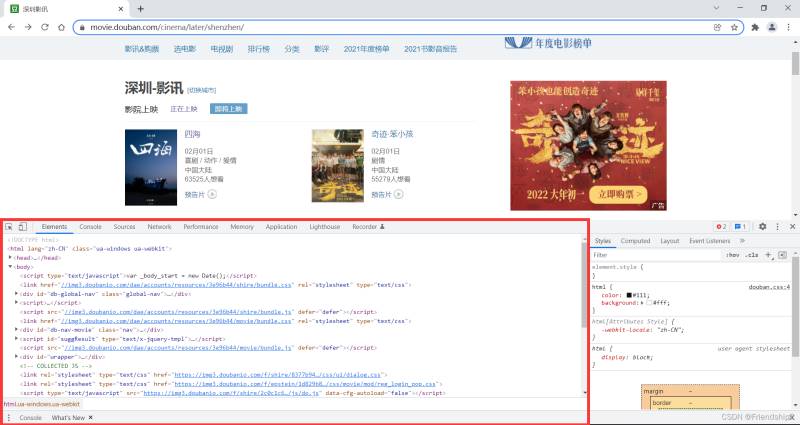
按Ctrl+Shift+C快捷鍵
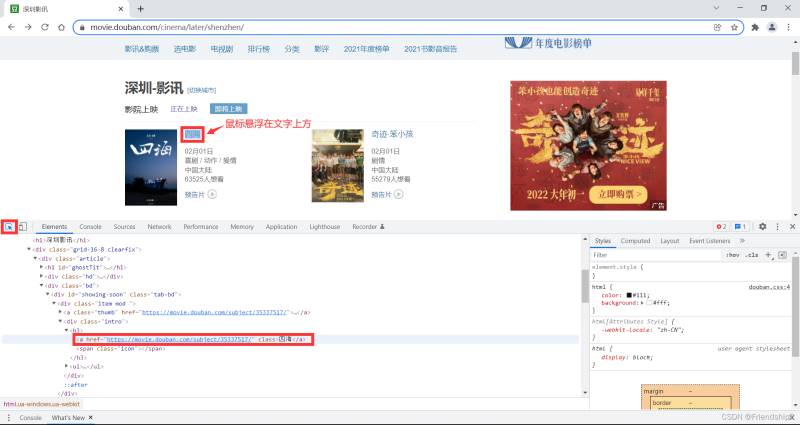
按Ctrl+F快捷鍵,控制臺出現搜索框
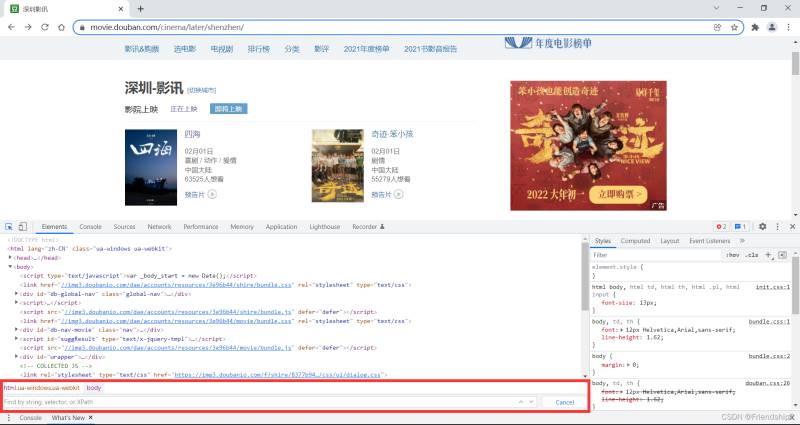
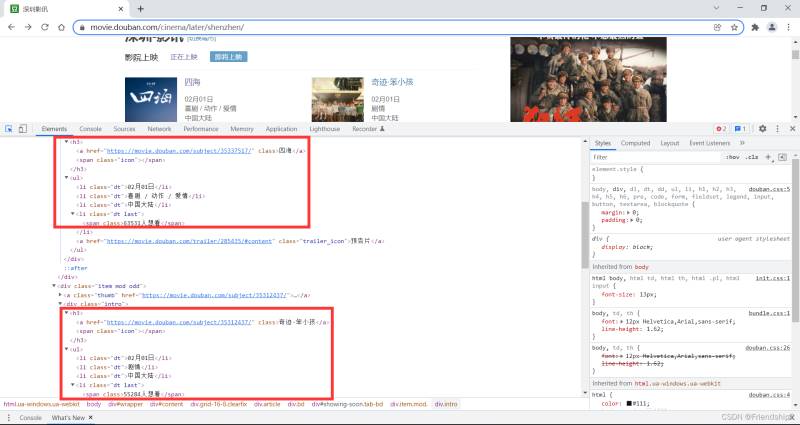
復制Xpath
Xpath為//*[@id=“showing-soon”]/div[1]/div/h3/a
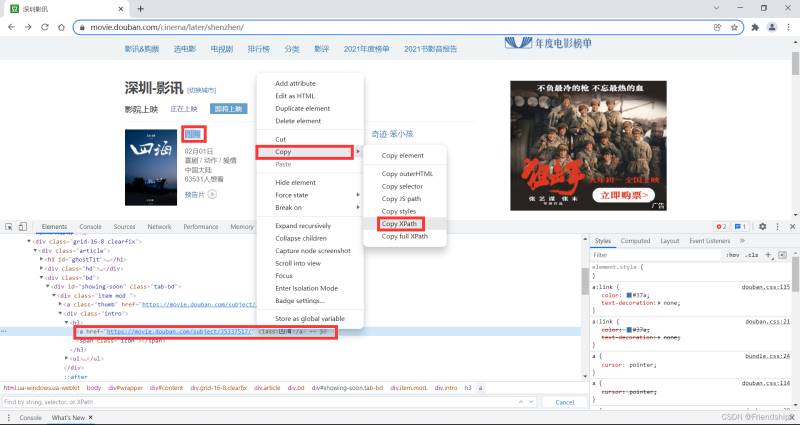
粘貼到搜索框,驗證Xpath
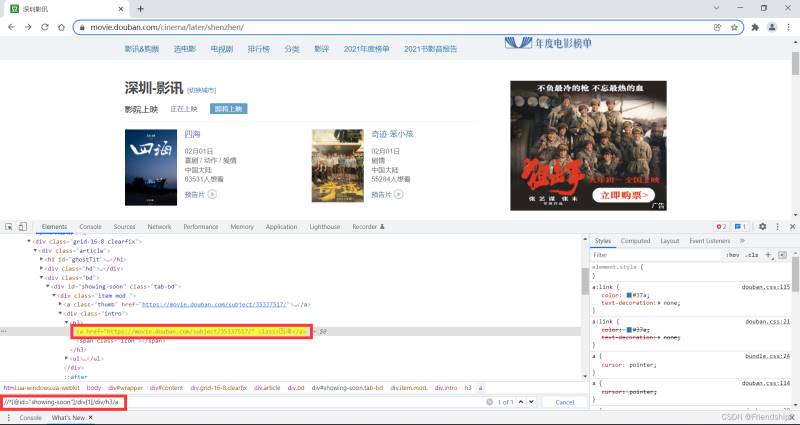
查看HTML,尋找共性
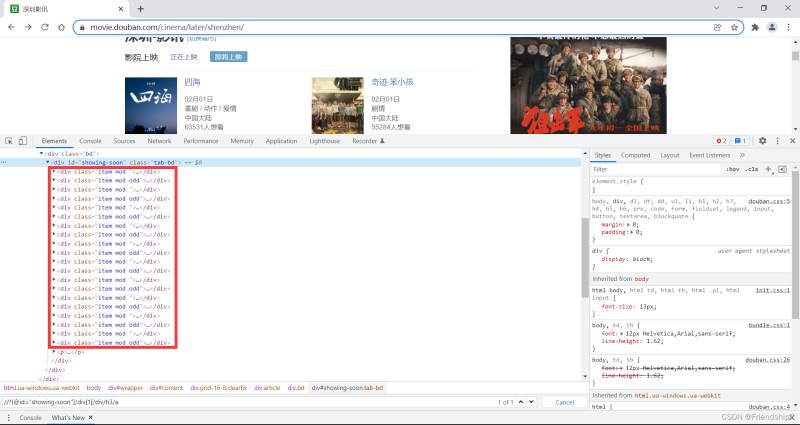
發現目標元素都在一個div框裡,修改Xpath
Xpath修改為//*[@id=“showing-soon”]/div/div/h3/a
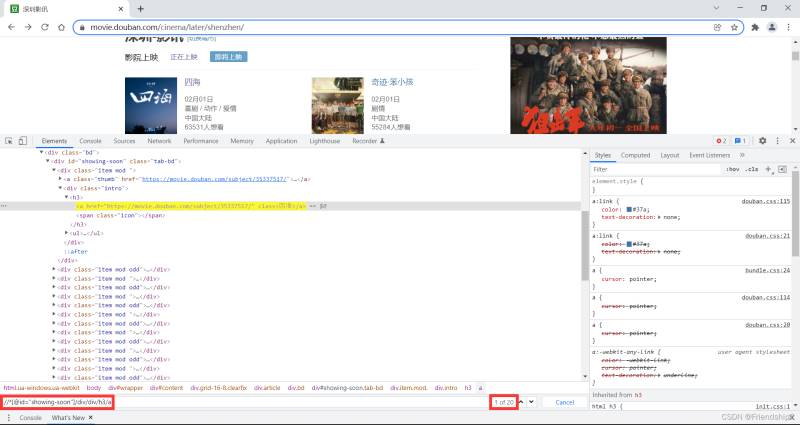
其餘目標元素,以此類推
最後,用Pandas保存為CSV文件
# 利用pandas保存文件 df = pd.DataFrame() df['上映日期'] = Ondate df['片名'] = name df['類型'] = movie_class df['制片國傢/地區'] = area df['想看人數'] = num df['超鏈接'] = href
代碼實現
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 25 10:07:11 2022
@author: TFX
"""
import time
import requests # 請求庫
import pandas as pd
from lxml import etree# 提取信息庫
# 日期
today = time.strftime('%Y{y}%m{m}%d{d}',time.localtime()).format(y='年',m='月',d='日')
# 網址
url = 'https://movie.douban.com/cinema/later/shenzhen/'
# 請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
# 發送請求
response = requests.get(url=url,headers=headers)
# 數據解析,xpath可以用瀏覽器檢查元素獲得
html = etree.HTML(response.text) #類型變換
# 電影詳細超鏈接
href = html.xpath('//*[@id="showing-soon"]/div/div/h3/a/@href')
# 上映日期
Ondate = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[1]/text()')
# 片名
name = html.xpath('//*[@id="showing-soon"]/div/div/h3/a/text()')
# 類型
movie_class = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[2]/text()')
# 制片國傢 / 地區
area = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[3]/text()')
# 想看人數
num = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[4]/span/text()')
# 利用pandas保存文件
df = pd.DataFrame()
df['上映日期'] = Ondate
df['片名'] = name
df['類型'] = movie_class
df['制片國傢/地區'] = area
df['想看人數'] = num
df['超鏈接'] = href
df.to_csv('2022春節檔電影_'+today+'.csv',mode='w',index=None,encoding='gbk')
print('保存完成!')
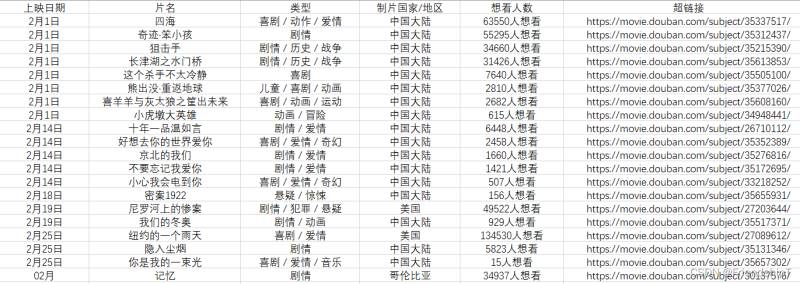
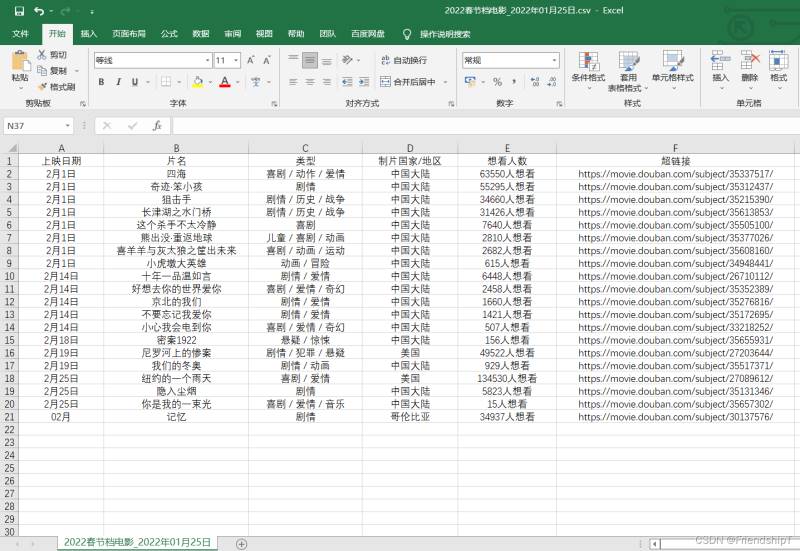
輸出結果

總結
到此這篇關於用Python爬取2022春節檔電影信息的文章就介紹到這瞭,更多相關Python春節檔電影信息內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python數據提取-lxml模塊
- python爬取一組小姐姐圖片實例
- 端午節將至,用Python爬取粽子數據並可視化,看看網友喜歡哪種粽子吧!
- python使用xpath獲取頁面元素的使用
- 教你如何利用python3爬蟲爬取漫畫島-非人哉漫畫