一文搞清楚MySQL count(*)、count(1)、count(col)區別
在工作中遇到count(*)、count(1)、count(col) ,可能會讓你分不清楚,都是計數,幹嘛這麼搞這麼多東西。
count 作用
COUNT(expression):返回查詢的記錄總數,expression 參數是一個字段或者 * 號。
測試
MySQL版本:5.7.29
創建一張用戶表,並插入一百萬條數據,其中gender字段有五十萬行是為null值的
CREATE TABLE `users` ( `Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(32) DEFAULT NULL COMMENT '名稱', `gender` varchar(20) DEFAULT NULL COMMENT '性別', `create_date` datetime DEFAULT NULL COMMENT '創建時間', PRIMARY KEY (`Id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用戶表';
count(*)
在 MySQL 5.7.18 之前,通過掃描聚集索引來InnoDB處理 語句。SELECT COUNT( *)從 MySQL 5.7.18 開始, 通過遍歷最小的可用二級索引來InnoDB處理SELECT COUNT( *)語句,除非索引或優化器提示指示優化器使用不同的索引。如果二級索引不存在,則掃描聚集索引。
大概意思就是有二級索引的情況下就使用二級索引,如果有多個二級索引優先選擇最小的那個二級索引來降低成本,沒有二級索引使用聚集索引。
下面通過測試來驗證這些觀點。
首先,在隻有Id這一個主鍵索引的情況下查詢執行計劃,

可以看到,type是index也就是使用瞭索引,key是PRIMARY就是使用瞭主鍵索引,key_len=8。
其次在name字段上加上索引,再次使用執行計劃查看

可以看到同樣使用瞭索引,隻不過索引用的是name字段的索引,key_len=99。
然後在保留name字段索引的情況下給create_date字段也加上索引,再次查看執行計劃

可以看到這次使用的是create_date字段的索引瞭,key_len=6。
不管上述是使用瞭哪個索引,其最後查詢到的總行數都是一百萬條,無論它們是否包含 NULL值。
count(1)
count(1) 和count(*) 執行查詢結果一樣,最終也是返回一百萬條數據,無論它們是否包含 NULL值。
count(col)
count(col) 統計某一列的值,又分為三種情況:
count(id): 統計id
和count(*) 執行查詢結果也是一樣,最終也是返回一百萬條數據.
count(index col):統計帶索引的字段
以count(name)進行查詢,執行計劃如下:

可以看到用的是索引字段進行統計,索引也命中瞭。
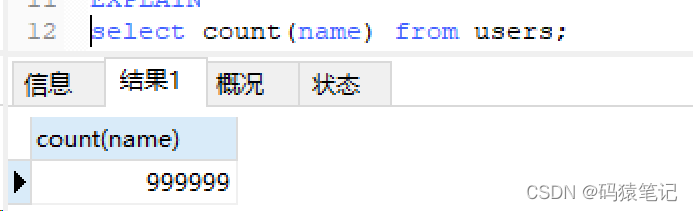
把一列中的name字段置為NULL,再進行count查詢,結果返回999999
再把這列的NULL值置為空字符串,再進行count查詢,結果返回1000000
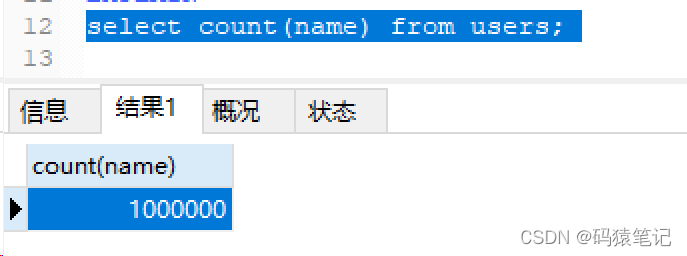
所以,綜上簡單的使用索引字段統計行數能夠命中索引,並且隻統計不為NULL值的行數。
count(normal col):統計不帶索引的字段
統計不帶索引的字段的話就不會使用索引,而且也是隻統計不為NULL值的行數。

count(1)和count(*)取舍
之前也不知道在哪看到的或聽說的,count(1) 比count(*) 效率高,這是錯誤的認知,官網上有這麼一句話,InnoDB handles SELECT COUNT( *) and SELECT COUNT(1) operations in the same way. There is no performance difference.
翻譯過來就是,InnoDB以同樣的方式處理SELECT COUNT( *)和SELECT COUNT(1) 操作,沒有性能差異。
對於MyISAM表, 如果從一個表中檢索,沒有檢索到其他列並且沒有 子句,COUNT(*)則優化為非常快速地返回 ,此優化僅適用於MyISAM 表,因為為此存儲引擎存儲瞭準確的行數,並且可以非常快速地訪問。 COUNT(1)僅當第一列定義為 時才進行相同的優化NOT NULL。—-來自MySQL官網
這些優化都是建立在沒有where 和 group by的前提下的。
阿裡開發規范中也提到

所以在開發中能用count(*) 就用count( *).
總結
count(*)、count(1)、count(id):返回查詢的記錄總數,無論字段是否包含空值,且count( )和count(1)效率是一樣的,沒差別,通過上面的執行計劃可以推斷count(id) 和count()、count(1) 效率應該也是一樣的或者說是很接近,有興趣的可以測試一下。
對統計帶非主鍵索引和不帶索引的字段進行統計的時候都是統計不為NULL的行數。
到此這篇關於一文搞清楚MySQL count(*)、count(1)、count(col)區別 的文章就介紹到這瞭,更多相關MySQL count(*),count(1),count(col)內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- MySQL COUNT(*)性能原理詳解
- Mysql數據庫group by原理詳解
- MySQL巧用sum、case和when優化統計查詢
- mysql查詢優化之100萬條數據的一張表優化方案
- mysql千萬級數據量根據索引優化查詢速度的實現