python爬蟲之利用Selenium+Requests爬取拉勾網
一、前言
利用selenium+requests訪問頁面爬取拉勾網招聘信息
二、分析url
觀察頁面可知,頁面數據屬於動態加載 所以現在我們通過抓包工具,獲取數據包
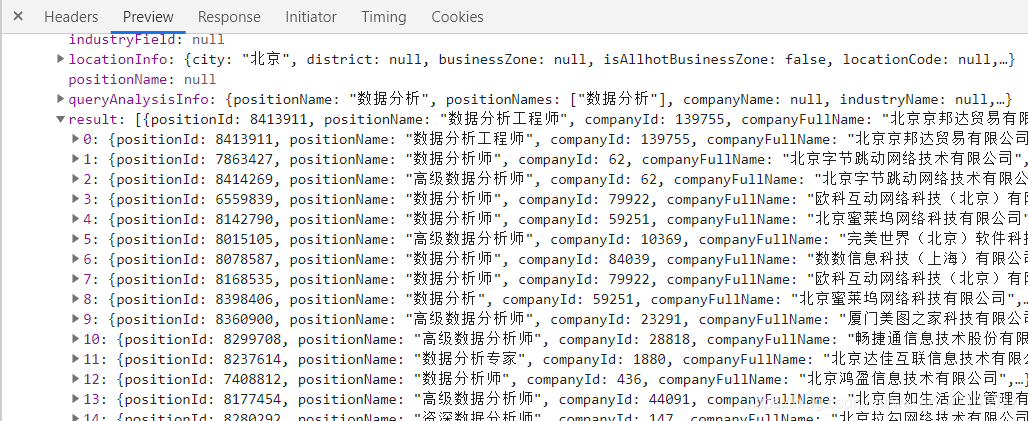
觀察其url和參數
url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 參數: city=%E5%8C%97%E4%BA%AC ==》城市 first=true ==》無用 pn=1 ==》頁數 kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90 ==》商品關鍵詞
所以我們要想實現全站爬取,需要有city和頁數
三、獲取所有城市和頁數
我們打開拉勾網,觀察後發現,他的數據並不是完全展示的,比如說 在城市篩選選擇全國 僅僅隻顯示30頁 但總頁數是遠遠大於30頁的;我又選擇北京發現是30頁又選擇北京下的海淀區又是30頁,可能我們無法把數據全部的爬取,但我們可以盡可能的將數據多的爬取
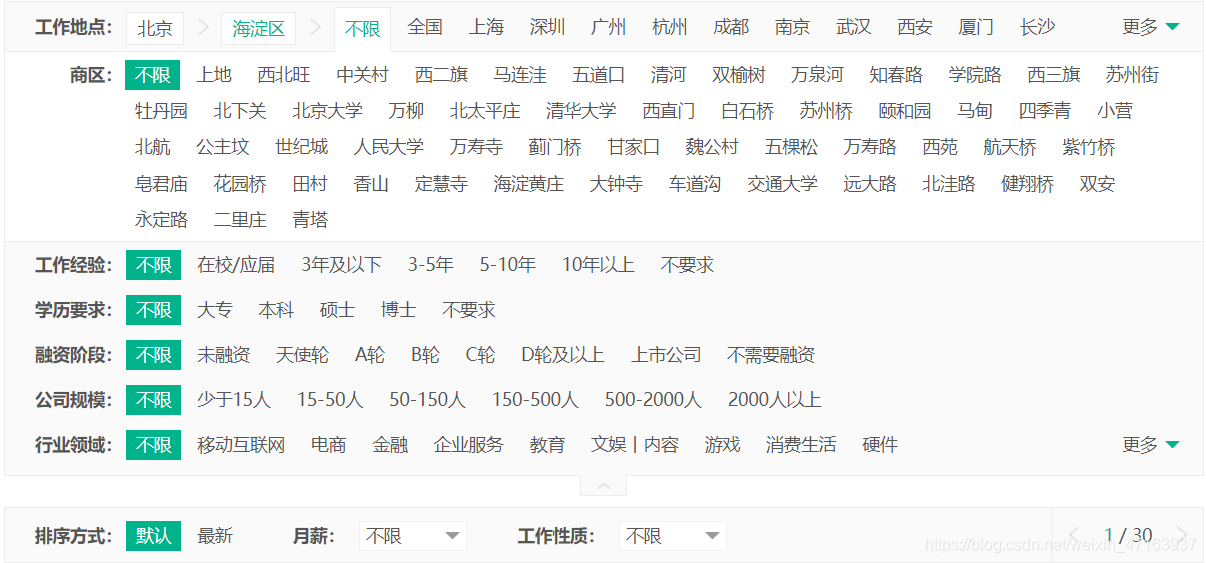
我們為瞭獲取全站數據,必然離不開的有兩個參數 一個是城市一個是頁數,所以我們利用selenium自動化去獲取所有城市和對應頁數
def City_Page(self):
City_Page={}
url="https://www.lagou.com/jobs/allCity.html?keyword=%s&px=default&companyNum=0&isCompanySelected=false&labelWords="%(self.keyword)
self.bro.get(url=url)
sleep(30)
print("開始獲取城市及其最大頁數")
if "驗證系統" in self.bro.page_source:
sleep(40)
html = etree.HTML(self.bro.page_source)
city_urls = html.xpath('//table[@class="word_list"]//li/input/@value')
for city_url in city_urls:
try:
self.bro.get(city_url)
if "驗證系統" in self.bro.page_source:
sleep(40)
city=self.bro.find_element_by_xpath('//a[@class="current_city current"]').text
page=self.bro.find_element_by_xpath('//span[@class="span totalNum"]').text
City_Page[city]=page
sleep(0.5)
except:
pass
self.bro.quit()
data = json.dumps(City_Page)
with open("city_page.json", 'w', encoding="utf-8")as f:
f.write(data)
return City_Page
四、生成params參數
我們有瞭每個城市對應的最大頁數,就可以生成訪問頁面所需的參數
def Params_List(self):
with open("city_page.json", "r")as f:
data = json.loads(f.read())
Params_List = []
for a, b in zip(data.keys(), data.values()):
for i in range(1, int(b) + 1):
params = {
'city': a,
'pn': i,
'kd': self.keyword
}
Params_List.append(params)
return Params_List
五、獲取數據
最後我們可以通過添加請求頭和使用params url來訪問頁面獲取數據
def Parse_Data(self,params):
url = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
header={
'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie':''
}
try:
text = requests.get(url=url, headers=header, params=params).text
if "頻繁" in text:
print("操作頻繁,已被發現 當前為第%d個params"%(i))
data=json.loads(text)
result=data["content"]["positionResult"]["result"]
for res in result:
with open(".//lagou1.csv", "a",encoding="utf-8") as f:
writer = csv.DictWriter(f, res.keys())
writer.writerow(res)
sleep(1)
except Exception as e:
print(e)
pass
六、總結
盡管數據隻顯示前30頁,但數據還是未完全獲取
在利用selenium獲取城市最大頁數時 應手動登錄拉勾網,並且其在訪問過程中可能會出現驗證系統需要驗證
利用requests訪問頁面獲取數據時 盡量sleep時間長一點,操作頻繁會封IP
到此這篇關於python爬蟲之利用Selenium+Requests爬取拉勾網的文章就介紹到這瞭,更多相關Selenium+Requests爬取拉勾網內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found