詳解Java對象的內存佈局
前言
今天來講些抽象的東西 — 對象頭,因為我在學習的過程中發現很多地方都關聯到瞭對象頭的知識點,例如JDK中的 synchronized鎖優化 和 JVM 中對象年齡升級等等。要深入理解這些知識的原理,瞭解對象頭的概念很有必要,而且可以為後面分享 synchronized 原理和 JVM 知識的時候做準備。
對象內存構成
Java 中通過 new 關鍵字創建一個類的實例對象,對象存於內存的堆中並給其分配一個內存地址,那麼是否想過如下這些問題:
- 這個實例對象是以怎樣的形態存在內存中的?
- 一個Object對象在內存中占用多大?
- 對象中的屬性是如何在內存中分配的?
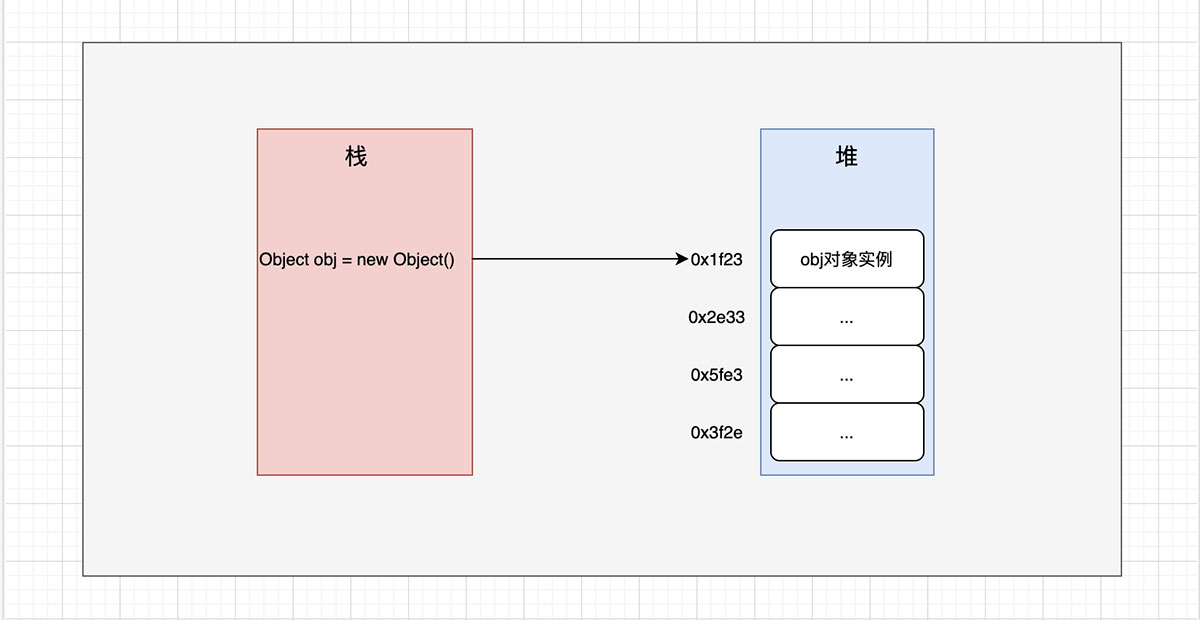
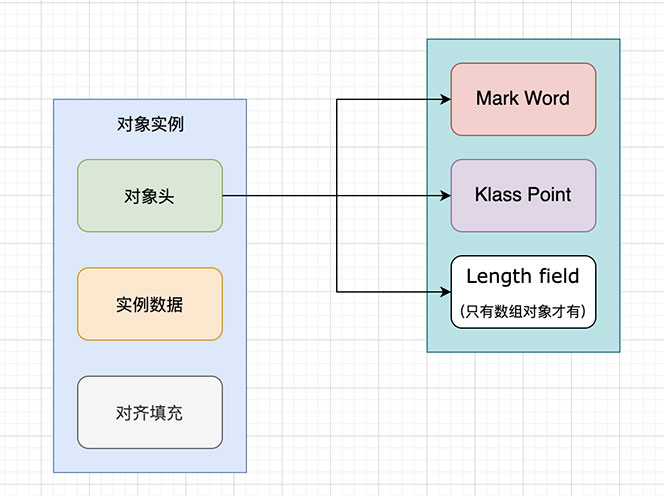
在 JVM 中,Java對象保存在堆中時,由以下三部分組成:
- 對象頭(object header):包括瞭關於堆對象的佈局、類型、GC狀態、同步狀態和標識哈希碼的基本信息。Java對象和vm內部對象都有一個共同的對象頭格式。
- 實例數據(Instance Data):主要是存放類的數據信息,父類的信息,對象字段屬性信息。
- 對齊填充(Padding):為瞭字節對齊,填充的數據,不是必須的。
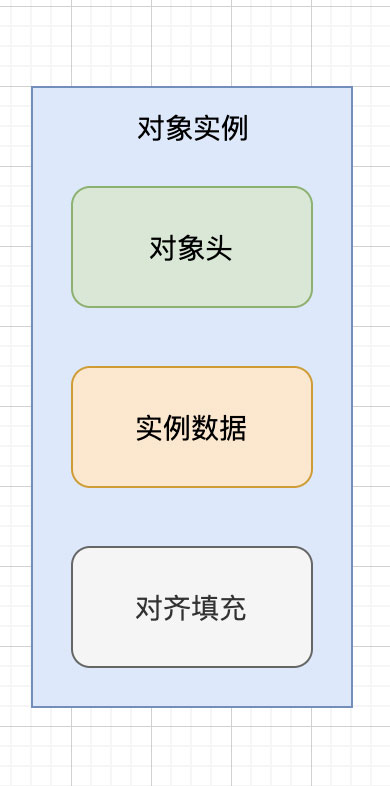
對象頭
我們可以在Hotspot官方文檔中找到它的描述(下圖)。從中可以發現,它是Java對象和虛擬機內部對象都有的共同格式,由兩個字(計算機術語)組成。另外,如果對象是一個Java數組,那在對象頭中還必須有一塊用於記錄數組長度的數據,因為虛擬機可以通過普通Java對象的元數據信息確定Java對象的大小,但是從數組的元數據中無法確定數組的大小。

它裡面提到瞭對象頭由兩個字組成,這兩個字是什麼呢?我們還是在上面的那個Hotspot官方文檔中往上看,可以發現還有另外兩個名詞的定義解釋,分別是 mark word 和 klass pointer。

從中可以發現對象頭中那兩個字:第一個字就是 mark word,第二個就是 klass pointer。
Mark Word
用於存儲對象自身的運行時數據,如哈希碼(HashCode)、GC分代年齡、鎖狀態標志、線程持有的鎖、偏向線程ID、偏向時間戳等等。
Mark Word在32位JVM中的長度是32bit,在64位JVM中長度是64bit。我們打開openjdk的源碼包,對應路徑/openjdk/hotspot/src/share/vm/oops,Mark Word對應到C++的代碼markOop.hpp,可以從註釋中看到它們的組成,本文所有代碼是基於Jdk1.8。
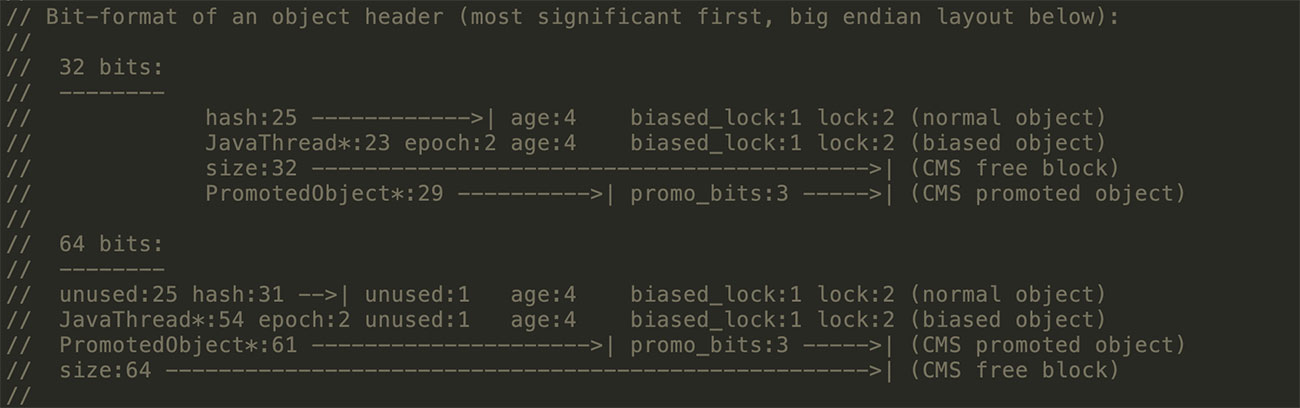
Mark Word在不同的鎖狀態下存儲的內容不同,在32位JVM中是這麼存的
在64位JVM中是這麼存的
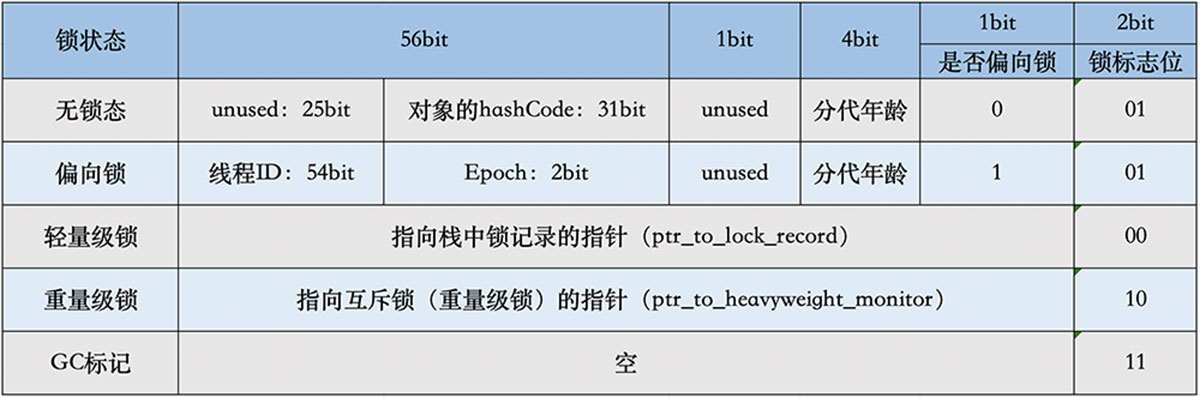
雖然它們在不同位數的JVM中長度不一樣,但是基本組成內容是一致的。
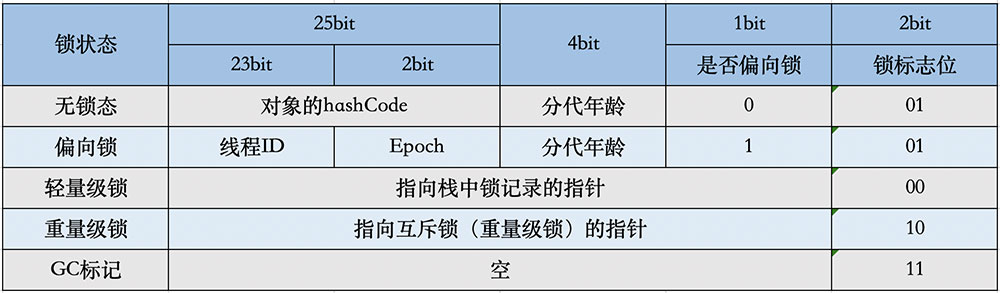
- 鎖標志位(lock):區分鎖狀態,11時表示對象待GC回收狀態, 隻有最後2位鎖標識(11)有效。
- biased_lock:是否偏向鎖,由於無鎖和偏向鎖的鎖標識都是 01,沒辦法區分,這裡引入一位的偏向鎖標識位。
- 分代年齡(age):表示對象被GC的次數,當該次數到達閾值的時候,對象就會轉移到老年代。
- 對象的hashcode(hash):運行期間調用System.identityHashCode()來計算,延遲計算,並把結果賦值到這裡。當對象加鎖後,計算的結果31位不夠表示,在偏向鎖,輕量鎖,重量鎖,hashcode會被轉移到Monitor中。
- 偏向鎖的線程ID(JavaThread):偏向模式的時候,當某個線程持有對象的時候,對象這裡就會被置為該線程的ID。 在後面的操作中,就無需再進行嘗試獲取鎖的動作。
- epoch:偏向鎖在CAS鎖操作過程中,偏向性標識,表示對象更偏向哪個鎖。
- ptr_to_lock_record:輕量級鎖狀態下,指向棧中鎖記錄的指針。當鎖獲取是無競爭的時,JVM使用原子操作而不是OS互斥。這種技術稱為輕量級鎖定。在輕量級鎖定的情況下,JVM通過CAS操作在對象的標題字中設置指向鎖記錄的指針。
- ptr_to_heavyweight_monitor:重量級鎖狀態下,指向對象監視器Monitor的指針。如果兩個不同的線程同時在同一個對象上競爭,則必須將輕量級鎖定升級到Monitor以管理等待的線程。在重量級鎖定的情況下,JVM在對象的ptr_to_heavyweight_monitor設置指向Monitor的指針。
Klass Pointer
即類型指針,是對象指向它的類元數據的指針,虛擬機通過這個指針來確定這個對象是哪個類的實例。
實例數據
如果對象有屬性字段,則這裡會有數據信息。如果對象無屬性字段,則這裡就不會有數據。根據字段類型的不同占不同的字節,例如boolean類型占1個字節,int類型占4個字節等等;
對齊數據
對象可以有對齊數據也可以沒有。默認情況下,Java虛擬機堆中對象的起始地址需要對齊至8的倍數。如果一個對象用不到8N個字節則需要對其填充,以此來補齊對象頭和實例數據占用內存之後剩餘的空間大小。如果對象頭和實例數據已經占滿瞭JVM所分配的內存空間,那麼就不用再進行對齊填充瞭。
所有的對象分配的字節總SIZE需要是8的倍數,如果前面的對象頭和實例數據占用的總SIZE不滿足要求,則通過對齊數據來填滿。
為什麼要對齊數據?字段內存對齊的其中一個原因,是讓字段隻出現在同一CPU的緩存行中。如果字段不是對齊的,那麼就有可能出現跨緩存行的字段。也就是說,該字段的讀取可能需要替換兩個緩存行,而該字段的存儲也會同時污染兩個緩存行。這兩種情況對程序的執行效率而言都是不利的。其實對其填充的最終目的是為瞭計算機高效尋址。
至此,我們已經瞭解瞭對象在堆內存中的整體結構佈局,如下圖所示
Talk is cheap, show me code
概念的東西是抽象的,你說它是這樣組成的,就真的是嗎?學習是需要持懷疑的態度的,任何理論和概念隻有自己證實和實踐之後才能接受它。還好 openjdk 給我們提供瞭一個工具包,可以用來獲取對象的信息和虛擬機的信息,我們隻需引入 jol-core 依賴,如下
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.8</version> </dependency>
jol-core 常用的三個方法
ClassLayout.parseInstance(object).toPrintable():查看對象內部信息.GraphLayout.parseInstance(object).toPrintable():查看對象外部信息,包括引用的對象.GraphLayout.parseInstance(object).totalSize():查看對象總大小.
普通對象
為瞭簡單化,我們不用復雜的對象,自己創建一個類 D,先看無屬性字段的時候
public class D {
}
通過 jol-core 的 api,我們將對象的內部信息打印出來
public static void main(String[] args) {
D d = new D();
System.out.println(ClassLayout.parseInstance(d).toPrintable());
}
最後的打印結果為

可以看到有 OFFSET、SIZE、TYPE DESCRIPTION、VALUE 這幾個名詞頭,它們的含義分別是
- OFFSET:偏移地址,單位字節;
- SIZE:占用的內存大小,單位為字節;
- TYPE DESCRIPTION:類型描述,其中object header為對象頭;
- VALUE:對應內存中當前存儲的值,二進制32位;

可以看到,d對象實例共占據16byte,對象頭(object header)占據12byte(96bit),其中 mark word占8byte(64bit),klass pointe 占4byte,另外剩餘4byte是填充對齊的。
這裡由於默認開啟瞭指針壓縮,所以對象頭占瞭12byte,具體的指針壓縮的概念這裡就不再闡述瞭,感興趣的讀者可以自己查閱下官方文檔。jdk8版本是默認開啟指針壓縮的,可以通過配置vm參數開啟關閉指針壓縮,-XX:-UseCompressedOops。
如果關閉指針壓縮重新打印對象的內存佈局,可以發現總SIZE變大瞭,從下圖中可以看到,對象頭所占用的內存大小變為16byte(128bit),其中 mark word占8byte,klass pointe 占8byte,無對齊填充。

開啟指針壓縮可以減少對象的內存使用。從兩次打印的D對象佈局信息來看,關閉指針壓縮時,對象頭的SIZE增加瞭4byte,這裡由於D對象是無屬性的,讀者可以試試增加幾個屬性字段來看下,這樣會明顯的發現SIZE增長。因此開啟指針壓縮,理論上來講,大約能節省百分之五十的內存。jdk8及以後版本已經默認開啟指針壓縮,無需配置。
數組對象
上面使用的是普通對象,我們來看下數組對象的內存佈局,比較下有什麼異同
public static void main(String[] args) {
int[] a = {1};
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
打印的內存佈局信息,如下

可以看到這時總SIZE為共24byte,對象頭占16byte,其中Mark Work占8byte,Klass Point 占4byte,array length 占4byte,因為裡面隻有一個int 類型的1,所以數組對象的實例數據占據4byte,剩餘對齊填充占據4byte。
結尾
經過以上的內容我們瞭解瞭對象在內存中的佈局,瞭解對象的內存佈局和對象頭的概念,特別是對象頭的Mark Word的內容,在我們後續分析 synchronize 鎖優化 和 JVM 垃圾回收年齡代的時候會有很大作用。
JVM中大傢是否還記得對象在Suvivor中每熬過一次MinorGC,年齡就增加1,當它的年齡增加到一定程度後就會被晉升到老年代中,這個次數默認是15歲,有想過為什麼是15嗎?在Mark Word中可以發現標記對象分代年齡的分配的空間是4bit,而4bit能表示的最大數就是2^4-1 = 15。
以上就是詳解Java對象的內存佈局的詳細內容,更多關於Java對象內存佈局的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- None Found