分佈式系統下調用鏈追蹤技術面試題
引言
一個復雜的分佈式系統,用戶發起一個請求,這個請求可能調用幾十到幾百個服務,經過很多業務層,而每個業務又是多個機器集群,一個請求具體被隨機到哪臺機器上又無法確定,如果最後用戶的請求失敗,隻返回一個錯誤提示,作為開發人員,該如何定位解決問題?你需要定位以下問題:
- 問題出在哪個服務,是你負責的服務還是調用別人服務的某一個環節。
- 同一個服務集群有多臺機器,到底要去哪個機房哪臺機器定位某條報錯信息。
- 同一個接口可能有多次請求,到底是哪一次報錯瞭。
- 多個服務之間調用順序是怎樣的。
- 如果需要響應速度優化,到底是哪個環節哪個服務耗時瞭,如何定位。
1、面試官:
分佈式微服務環境下那麼多機器,調用鏈又很長,你們是如何定位問題的?
問題分析:這個問題,如果你使用過微服務框架,對於服務治理你一定知道這種技術,如果作為微服務架構的小白,你隻是知道一些基礎知識,突然被問到這個問題,確實比較懵逼。這麼多機器集群,我怎麼知道每次服務打到哪個機器上瞭,我怎麼知道到底是哪個環節拋異常瞭?
我:分佈式系統中針對上述問題,我們急需一套鏈路追蹤(Trace)系統來解決這些痛點,這個系統主要的任務就是收集各服務的日志,上報日志,分析日志,保存展示。其關鍵核心在於調用鏈,為每個請求生成全局唯一的ID(Traceld),通過Traceld 將不同系統的“孤立地”調用信息關聯在一起,還原出更多有價值的數據。
(如果你還不明白到底怎麼搞直接看看成品圖)
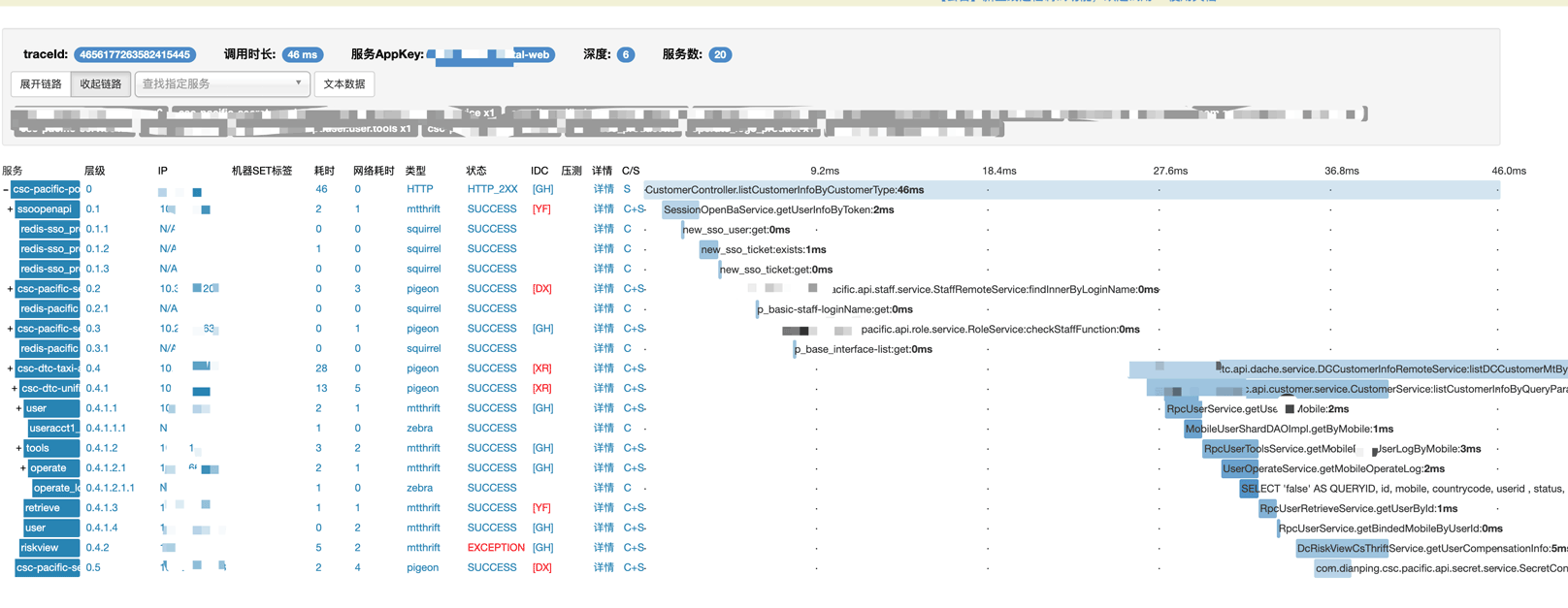
通過一個Trace查詢某一次請求,這個Trace是全劇唯一,通過這個鏈路追蹤系統,你可以清楚的知道服務調用深度,涉及服務個數,每個服務調用的時間及狀態,到底是哪個服務出現異常,具體到方法名,查找耗時長的鏈路時,可以通過在查詢結果頁面點擊“耗時”二字,讓數據以耗時升序或降序排列,都一目瞭然,上面的問題都得到解決瞭。
2、面試官:
你知道哪些成熟的調用鏈開源工具?
Google Dapper
Dapper一開始是一個自包含的跟蹤工具,但後來發展成為一個監控平臺,具有高性能,代碼侵入性低,支持集群擴展特性。
dapper 處理日志分為3個階段:
- 各個服務將span數據寫到本機日志上;
- dapper守護進程進行拉取日志文件,將文件讀到dapper收集器裡;
- dapper收集器將結果寫到bigtable中,一次跟蹤被記錄為一行。
阿裡巴巴的分佈式調用跟蹤系統 – 鷹眼(EagleEye)
EagleEye 是一個以調用鏈追蹤技術為核心的監控系統,通過收集,存儲,分析分佈式系統中的調用事件參數,協同開發人員進行故障定位,容量預估,性能瓶頸定位,系統請求鏈路梳理等,EagleEye 的開發也是基於Google Dapper 的設計思想。
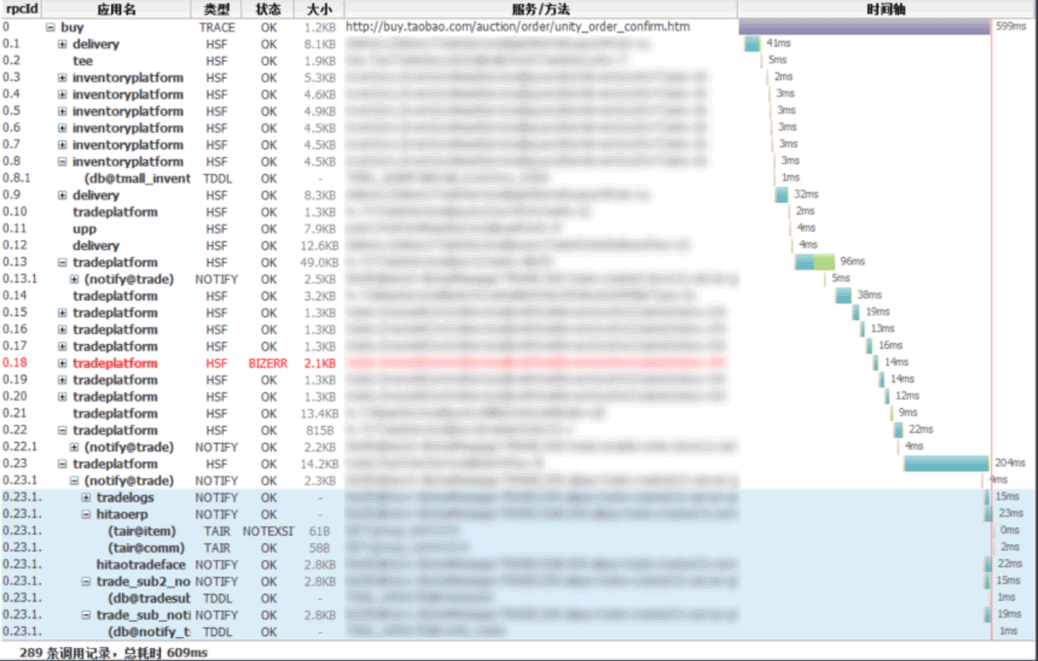
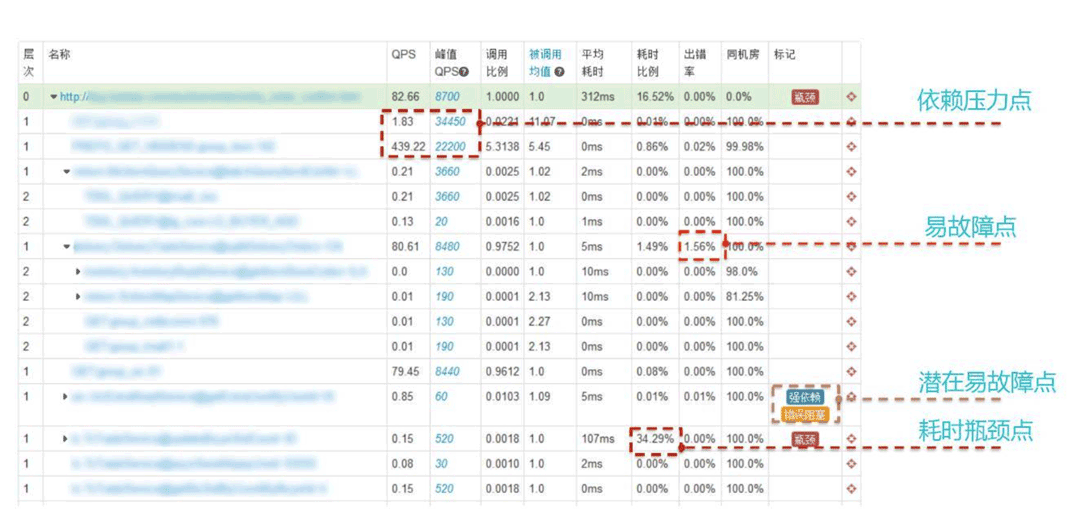
圖片來源:github EagleEye 社區
美團分佈式會話追蹤系統 – MTrace
MTrace是美團點評內部的分佈式會話跟蹤系統,也借鑒瞭2010年Google的 dapper,通過一個全局的ID將分佈在各個服務節點上的同一次請求串聯起來,還原原有的調用關系、追蹤系統問題、分析調用數據、統計系統指標,MTrace支持美團內部RPC中間件,HTTP中間件,MySQL,Tair,MQ等中間件的數據埋點。
總結
無論哪個公司使用哪個框架,我們發現 trace 系統最終要解決的問題都是相同的,大致歸納如下:
- 復雜網絡環境中定位問題,通過異常log綁定記錄,輕松定位。
- 發現熱點,發現瓶頸問題。
- 預估系統容量,按照上下遊調用比例,粗略計算哪些機器需要提前擴容。
- 優化鏈路,通過鏈路分析,從更高的全局角度分析可以優化的點。
以上就是分佈式系統下調用鏈追蹤技術面試題的詳細內容,更多關於分佈式系統下調用鏈追蹤的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- 輕量級ORM框架Dapper用法之安裝Dapper
- Java的springcloud Sentinel是什麼你知道嗎
- SpringCloud分佈式鏈路追蹤組件Sleuth配置詳解
- ORM框架之Dapper簡介和性能測試
- Spring Cloud 專題之Sleuth 服務跟蹤實現方法