分佈式架構Redis中有哪些數據結構及底層實現原理
引言
面完瞭負載均衡,正向代理,反向代理,終於松瞭一口氣,然後話題轉向瞭緩存Redis,為什麼是這個順序呢?
回想瞭一下系統架構,我大概知道原因瞭。

Redis 處於服務最上層。面試官是按照這個順序從上到下考察我對整個系統設計能力,圍著整個系統自頂向下的結構考察基礎。不糾結這麼多,反正先問後問,Redis一定是你必須掌握的。
1、面試官:我看你提到,項目中使用瞭Reids作為緩存,為什麼是Reids而不是其他,Redis有什麼優勢嗎?
問題分析: Redis的設計理念已經成瞭很多一線互聯網公司自主研發分佈式緩存框架的標桿,因為相比傳統的 Memcache ,Redis 豐富的數據結構實在太香。
答:
- 首先 Redis 支持豐富的數據結構,新版本數據結構從最初的5種變成9種。
- 其次 Redis 是讀寫單進程單線程,不用考慮並發讀寫的復雜場景,速度也快。
- Reids 功能完備,支持數據持久化,支持主從復制和集群。
- 還有Lua腳本,事務,發佈訂閱模型,Reids 都支持。
在高並發請求時,為何我們頻繁提到緩存技術?最直接的原因是,磁盤IO及網絡開銷是直接請求內存IO千百上千倍,做個簡單計算,如果我們需要某個數據,該數據從數據庫磁盤讀出來需要0.0045S,經過網絡請求傳輸需要0.0005S,那麼每個請求完成最少需要0.005S,該數據服務器每秒最多隻能響應200個請求,而如果該數據存於本機內存裡,讀出來隻需要100us,那麼每秒能夠響應10000個請求。通過將數據存儲到離CPU更近的未位置,減少數據傳輸時間,提高處理效率,這就是緩存的意義。
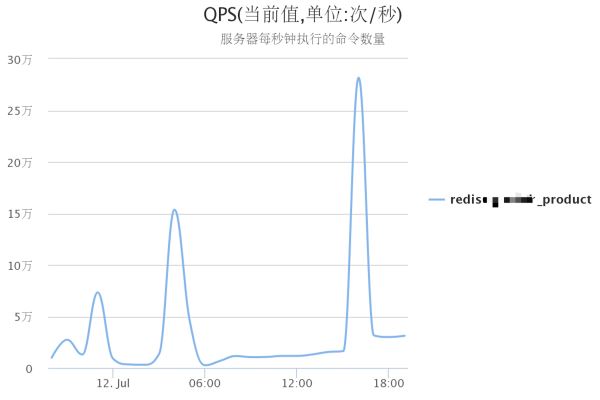
給您列舉一個我利用Reids把項目QPS提到幾十萬級別的案例:
一個風控系統在日常24H中 Redis集群 QPS 曲線圖,從業務低峰期幾千或晚高峰最高30W,一個 Redis 集群都可輕松應對,30WQPS 在大型系統中流量並不算高,且不是核心系統,如果在多幾倍幾十倍多流量,一個結構優良的Redis 集群都可輕松應對,這充分說明瞭我們為什麼要使用緩存,緩存可以把系統響應能力提高N個數量級,遠高於傳統基於硬盤的關系型數據庫
面試官心想:看來是做足瞭功課。
2、面試官:剛剛你提到Redis是單線程,為什麼單線程模型的 Redis 性能不減。
問題分析:成功挖坑,提到單線程肯定會問我為什麼要這樣設計。
答:
單線程不代表一定就慢,單線程有一個最大好處就是節省線程切換的開銷,更不用考慮並發讀寫帶來的復雜操作場景,這就大大節省瞭線程間切換的時間瞭。
單線程模型避免瞭多線程的頻繁上下文切換,這也避免瞭多線程可能產生的競爭問題。
Reids 是基於內存的讀寫操作,內存肯定比傳統磁盤IO數據庫快。
Reids 核心是基於非阻塞的IO多路復用機制。
3、面試官:那你剛剛說的Redis數據結構都有哪幾種,如何選擇使用哪種?
問題分析: 常用的5種,重點學會這5種數據結構的使用足夠瞭。
答:比較常用的有5種
字符串 String: 字符串是 Redis 中最為基礎的數據存儲類型,數據結構簡單,可存儲文本,Json,圖片數據等任何二進制文件。如姓名,訂單號等,對於一些特殊的數據結構,比如List、Set等,建議采用相應的下面介紹的List和Set數據結構進行存儲,這樣不僅可以節省存儲空間還可以提高操作效率。
列表 List: 類似 Java 中的 List ,按照插入順序排序的字符串鏈表,在插入時,如果該鍵並不存在,Redis將為該鍵創建一個新的鏈表。與此相反,如果鏈表中所有的元素均被移除,那麼該鍵也將會被從數據庫中刪除。
集合 Set: 類似 Java 中的set,但它是一個無序集合,用於存儲無序(存入和取出的順序不一定相同)元素,值不能重復。可以使用Redis的Set數據類型跟蹤一些唯一性數據,比如訪問系統的唯一IP地址,唯一用戶ID等信息,再比如在微博應用中,每個人的好友存在一個集合(set)中,這樣求兩個人的共同好友的操作,可能就隻需要用求交集命令即可。
有序集合 Sorted Set: 類似 Java 中的 TreeSet,支持從小到大排序的 set,適用於排行榜結構的數據存儲。
Hash: 類型相當於Java中的HashMap,所以該類型非常適合於存儲值對象的信息,比如用戶基本信息對象含有昵稱、性別和Age等屬性,可以使用Hash來存儲User對象,Key可以為用戶的唯一ID屬性。
除此之外,新版本的Redis還提供瞭位圖,地理坐標,流幾種結構。
深入分析
曾經有面試官問我,你看過Reids源碼嗎,我說沒有看過,他說有精力可以研究一下,Redis那幾種常用的數據結構底層實現原理還是值得學習的。
1、簡單動態字符串結構,Redis字符串的實現方式
簡單動態字符串(simple dynamic string)簡稱SDS。Redis使用C語言編寫,但是傳統的C字符串使用長度為 N+1 的字符串數組來表示長度為N的字符串,所以為瞭獲取一個長度為C字符串的長度,必須遍歷整個字符串。和C字符串不同,動態字符串的數據結構中,有專門用於保存字符串長度的變量,我們可以通過獲取len屬性的值,直接知道字符串長度,從一定程度上提高瞭讀取效率。

Redis源碼中,動態字符串的定義:
/*
* 保存字符串對象的結構
*/
struct sdshdr {
// buf 中已占用空間的長度
int len;
// buf 中剩餘可用空間的長度
int free;
// 數據空間
char buf[];
};
len 變量,用於記錄buf 中已經使用的空間長度。
free 變量,用於記錄buf 中還空餘的空間,初次分配空間,一般沒有空餘,在對字符串修改的時候,會有剩餘空間出現,這樣做是為瞭杜絕C語言中緩沖區溢出的可能性,當我們需要對一個SDS進行修改的時候,Redis 會在執行拼接操作之前,預先檢查給定SDS空間是否足夠,如果不夠,會先拓展SDS的空間,然後再執行拼接操作。
buf 字符數組,用於記錄我們的字符串(記錄Redis)。
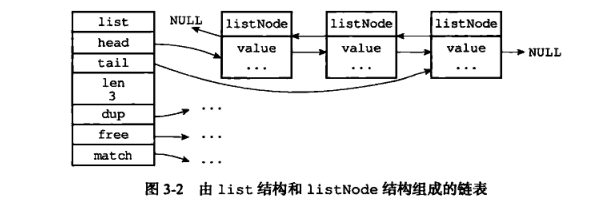
2、鏈表數據結構,List 底層結構
鏈表還是常規的普通雙端鏈表,可以支持反向查找和遍歷,更方便操作,通過增刪節點來靈活地調整鏈表的長度,雙端鏈表在Redis內部也是被多次使用:
- 事務模塊使用雙端鏈表依序保存輸入的命令。
- 服務器模塊使用雙端鏈表來保存多個客戶端。
- 訂閱/發送模塊使用雙端鏈表來保存訂閱模式的多個客戶端。
- 事件模塊使用雙端鏈表來保存時間事件(time event)。
3、跳躍表,sorted set底層結構
Redis sorted set的內部使用HashMap和跳躍表(SkipList)來保證數據的存儲和有序,(如果你還不瞭解紅黑樹,需要先額外補補功課),HashMap裡放的是成員到score的映射,而跳躍表裡存放的是所有的成員,排序依據是HashMap裡存的score,使用跳躍表的結構可以獲得比較高的查找效率,並且在實現上比較簡單。
那為什麼Redis的作者使用 SkipList 結構而不是紅黑樹?
紅黑樹:紅黑樹的查找效率很高,但是在進行重新平衡時,會涉及到大量節點的變化,因此實現和操作起來都比較復雜。
跳躍表:通過簡單的多層索引結構,實現簡單,且能達到近似於紅黑樹的查找效率,插入節點(多層插入)不需要像紅黑樹那樣有額外操作。而且跳躍表還能實現范圍查找及輸出,而紅黑樹隻支持單個元素查找,對於范圍查找效率低。
關於緩存的一些算法
(偷偷告訴你,這幾個關於Reids的算法很大概率也會被問到,需要多少知道幾種)
常用緩存數據淘汰策略
緩存是非常寶貴的資源,不能把所有數據都放入緩存,隻能把最重要的或者要求查詢速度最快的數據緩存起來,比如微博熱門話題排行榜功能,通常使用緩存查詢,而不是數據庫。
FIFO(First In First Out): 先進先出算法,即先放入緩存的先被移除。
LRU(Least Recently Used): 最近最少使用算法,使用時間距離現在最久的那個被移除。
LFU(Least Frequently Used): 最不常用算法,一定時間段內使用次數(頻率)最少的那個被移除。
緩存數據更新策略
- 定時任務從數據庫直接更新緩存:適用於對時間不敏感的數據。
- 查詢時寫緩存,即查詢優先查詢緩存,若緩存未命中,查詢數據庫,將返回結果寫入緩存,數據更新時先 delete緩存,再更新緩存。
- MQ 消息異步更新緩存,後文中會針對MQ的應用做單獨講解。
總結
這一節重點講解分佈式緩存 Redis ,本地緩存不一定每個項目都會使用,但是 Redis 數據設計合理,保證超高命中率,集群足夠穩定,那完全可以替代一級本地緩存。所以 Redis 非常值得你花更多時間學習。分佈式緩存是面試必問。
Redis 是建設高性能網站後臺不可缺少的工具,無論你是面試業務開發工程師還是架構師,都需要熟練掌握。
關於Redis,推薦閱讀黃建宏的《Redis 設計與實現》,能夠掌握Redis的5種數據結構,Redis 的持久化方式 RDB 和 AOF,兩者有什麼優點和缺點,如何選型,以及瞭解高可用 Redis 集群的建設方案。
以上就是分佈式架構Redis中有哪些數據結構及底層實現原理的詳細內容,更多關於分佈式架構Redis底層數據結構及原理的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Redis高效率原因及數據結構分析
- Java手寫Redis服務端的實現
- Redis之SDS數據結構的使用
- 面試分析分佈式架構Redis熱點key大Value解決方案
- redis的五大數據類型應用場景分析