MySQL的索引你瞭解嗎
一、索引介紹
索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法,這種數據結構就是索引。
二、索引優缺點
優點:
提高數據檢索的效率,降低數據庫的io成本通過索引列對數據進行排序,降低數據排序的成本,降低CPU的消耗。
缺點:
索引列也是要占用空間的。索引大大提高瞭查詢效率,同時卻也降低更新表的速度,如對表進行INSERT、UPDATE、DELETE時,效率降低。
三、索引結構
通常我們所說的索引,沒有特別指明,都是指B+樹結構組織的索引
B+Tree索引:最常見的索引類型,大部分引擎都支持B+樹索引
Hash索引:底層數據結構是用哈希表實現的,隻有精確匹配索引列的查詢才有效,不支持范圍查詢
R-tree(空間索引):空間索引是MyISAM引擎的一一個特殊索引類型,主要用於地理空間數據類型,通常使用較少
Full-text(全文索引):是一種通過建立倒排索引,快速匹配文檔的方式。類似於Lucene,Solr,ES
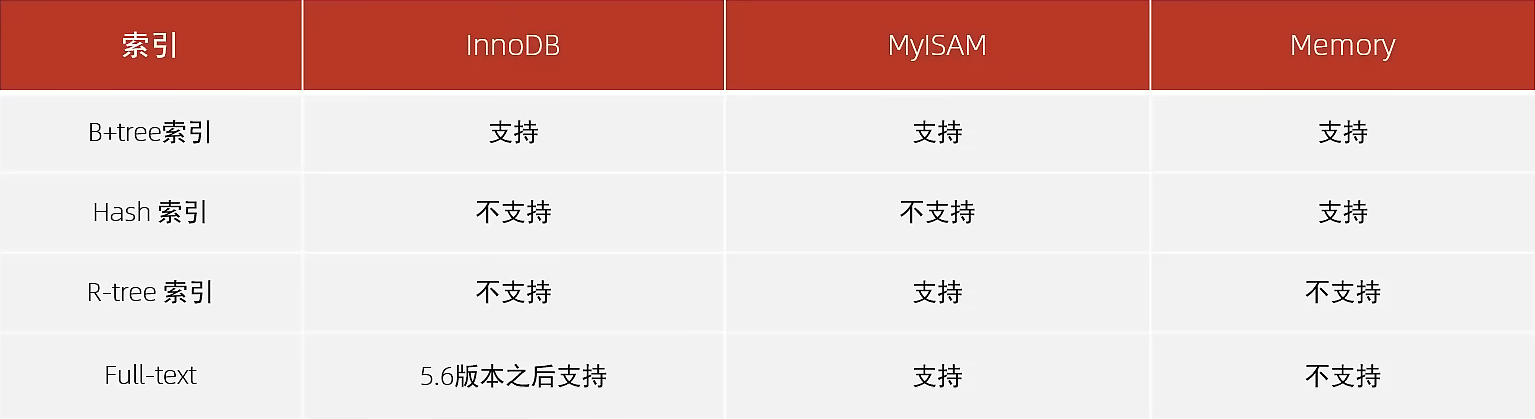
1. 經典B+樹
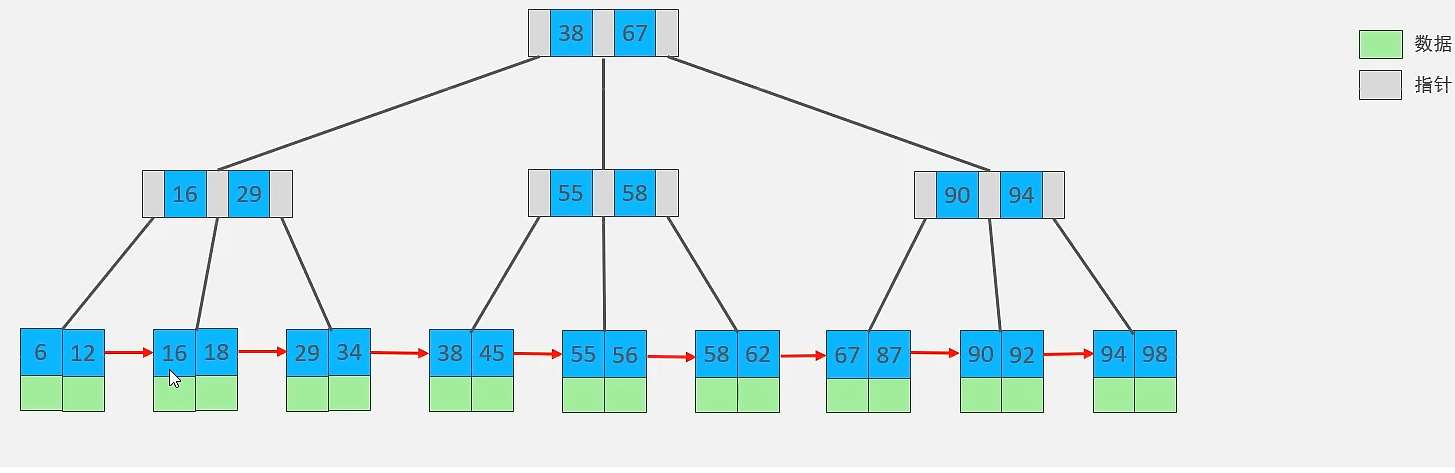
看結構和B樹比較像,B+樹與B樹的區別在於:
1.所有的元素都會出現在葉子節點,非葉子節點主要起到索引的作用,而葉子節點是用來存放數據的
2.B+樹的數據結構中,葉子節點形成瞭一個單向鏈表,每一個節點都會通過指針指向下一個元素
2. MySQL中B+樹索引
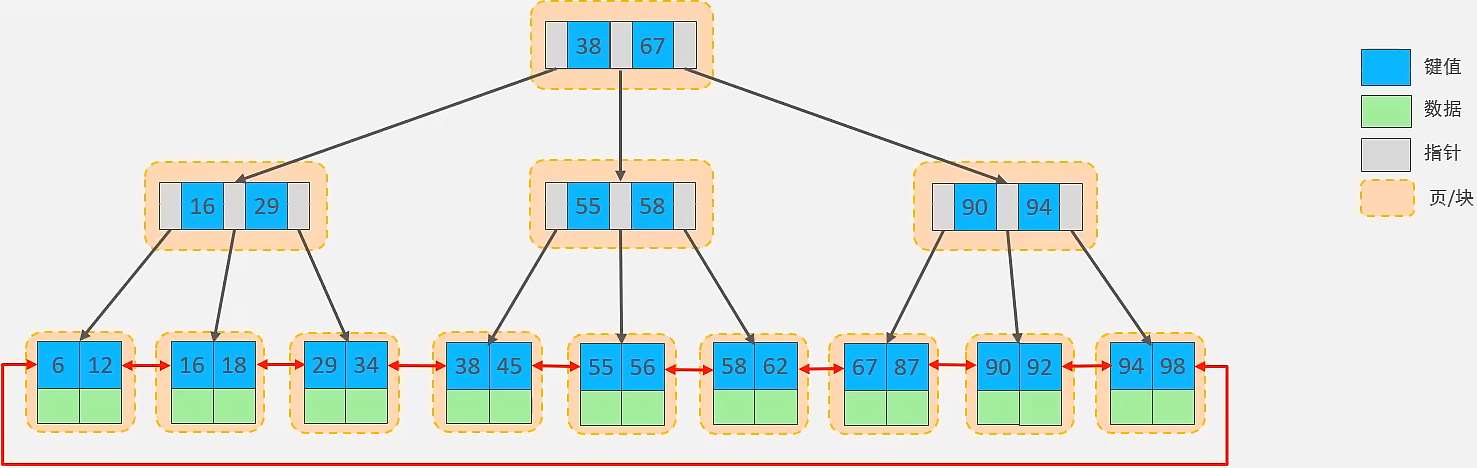
MySQL索引數據結構對經典的B+Tree進行瞭優化。在原B+Tree的基礎上,增加一個指向相鄰葉子節點的鏈表指針,就形成瞭帶有順序指針的B+Tree,提高區間訪問的性能,葉子節點雙向鏈表+首尾相連,便於范圍搜索和排序。
3. Hash索引
哈希索引就是采用一定的hash算法,將鍵值換算成新的hash值,映射到對應的槽位上,然後存儲在hash表中。
如果兩個(或多個)鍵值,映射到一個相同的槽位上,他們就產生瞭hash沖突(也稱為hash碰撞),可以通過鏈表來解決。
特點:
1. Hash索引隻能用於對等比較(=,in), 不支持范圍查詢(between, >,<, …)
2. 無法利用索引完成排序操作
3. 查詢效率高,通常隻需要一次檢索就可以瞭,效率通常要高於B+tree索引
存儲引擎支持:
在MySQL中,支持hash索引的是Memory引擎,而InnoDB中具有自適應hash功能,hash索引是存儲引擎根據B+Tree索引在指定條件下自動構建的。
4. 為什麼InnoDB選擇B+樹索引?
相對於二叉樹,層級更少,搜索效率高;
對於B-tree,無論是葉子節點還是非葉子節點,都會保存數據,這樣導致一頁中存儲的鍵值減少,指針跟著減少,要同樣保存大量數據,隻能增加樹的高度,導致性能降低;
相對Hash索引,Hash索引隻支持等值匹配,B+tree支持范圍匹配及排序操作。
四、索引分類

在InnoDB存儲引擎中,根據索引的存儲形式,又可以分為以下兩種:
聚簇索引(Clustering Index):將數據存儲與索引放到瞭一塊,索引結構的葉子節點保存瞭行數據;必須有而且隻有一個。
二級索引(Secondary Index):將數據與索引分開存儲,索引結構的葉子節點關聯的是對應的主鍵;可以存在多個。
聚簇索引選取規則:
如果存在主鍵,主鍵索引就是聚簇索引。
如果不存在主鍵,將使用第一個唯一(UNIQUE) 索引作為聚簇索引。
如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚簇索引。
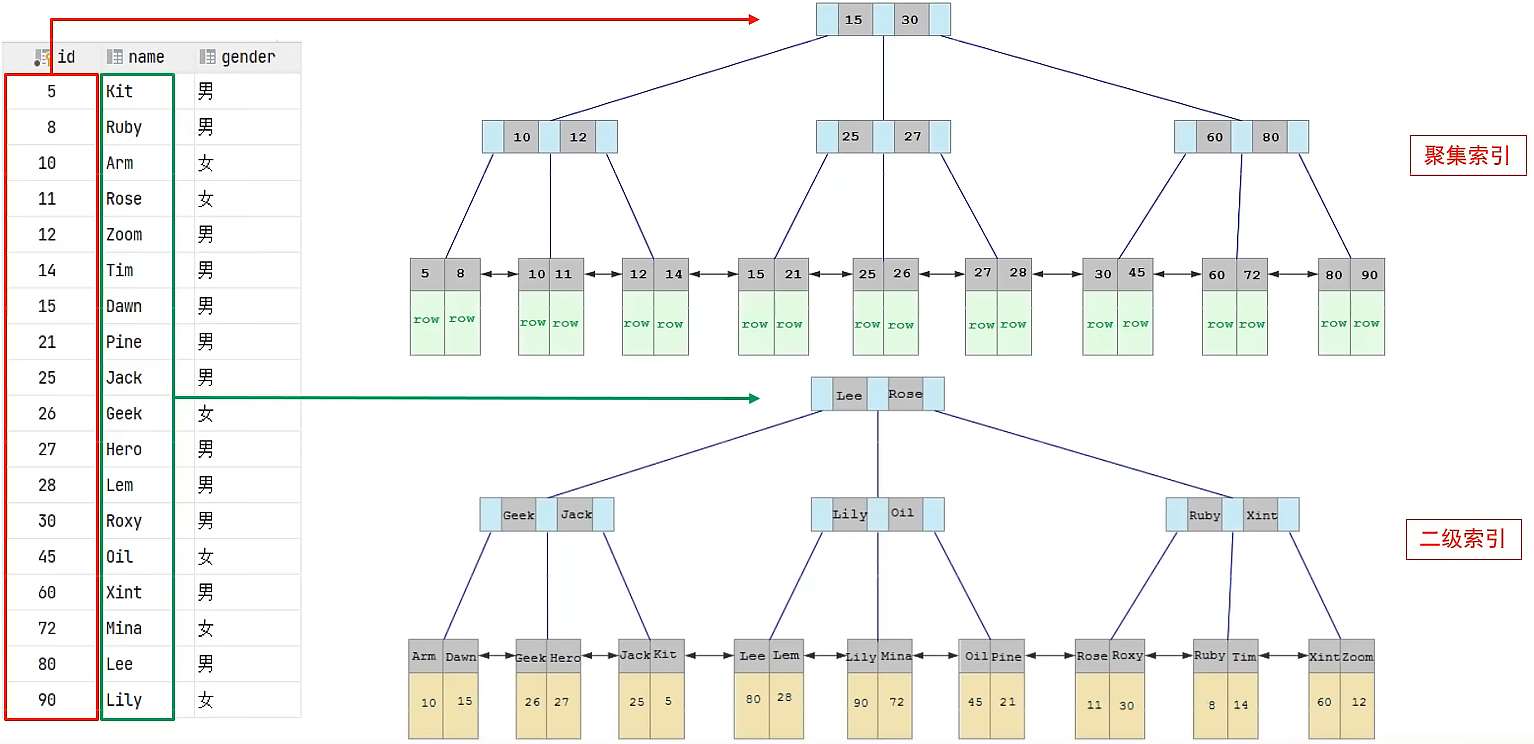
如果是(非主鍵)條件查詢,則采用回表查詢,即先通過二級索引查找主鍵(聚簇索引),得到主鍵再通過聚簇索引查找這一行數據。
InnoDB主鍵索引的B+tree高度為多高呢?
假設:
一行數據大小為1k,一頁中可以存儲16行這樣的數據。InnoDB的指針占用6個字節的空間,主鍵即使為bigint,占用字節數為8。
高度為2:
n*8+(n+ 1)*6= 16*1024 , 算出n約為1170
1171*16= 18736
高度為3:
1171 * 1171 * 16 = 21939856
五、索引語法
創建索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_ name ON table_ name ( index_ _col_ name,.. ) ;
查看索引
SHOW INDEX FROM table_ name ;
刪除索引
DROP INDEX index_ name ON table_ name ;
六、SQL性能分析
1. SQL執行頻率
MySQL客戶端連接成功後,通過show [session|global] status命令可以提供服務器狀態信息。通過如下指令,可以查看當前數據庫的INSERT、UPDATE、DELETE、 SELECT的訪問頻次:
show global status like 'Com_______';
2. 慢查詢日志
慢查詢日志記錄瞭所有執行時間超過指定參數(long_ query_ _time, 單位:秒,默認10秒)的所有SQL語句的日志。
MySQL的慢查詢日志默認沒有開啟,需要在MySQL的配置文件(/etc/my.cnf) 中配置如下信息:
#開啟MySQL慢日志查詢開關 slow_query_log=1 #設置慢日志的時間為2秒,SQL 語句執行時間超過2秒,就會視為慢查詢,記錄慢查詢日志 long query time=2
配置完畢之後,通過以下指令重新啟動MySQL服務器進行測試,查看慢日志文件中記錄的信息/var/lib/mysql/localhost-slow.log
當某一操作時間多於2s則會被記錄在慢查詢日志中。
3. profile詳情
show profiles能夠在做SQL優化時幫助我們瞭解時間都耗費到哪裡去瞭。通過have_ profiling參數, 能夠看到當前MySQL是否支持profile操作:
#查看當前數據庫是否支持profile操作 select @@have_profiling
默認profiling是關閉的,可以通過set語句在session/ global級別開啟profiling:
#開啟profiling set profiling = 1; #查看每一條SQL 的耗時基本情況 show profiles; #查看指定query_ id的SQL語句各個階段的耗時情況 show profile for query query_ id; #查看指定query_ id的SQL語句CPU的使用情況 show profile cpu for query query_id;
4. explain執行計劃
EXPLAIN或者DESC命令獲取MySQL如何執行SELECT語句的信息,包括在SELECT語句執行過程中表如何連接和連接的順序。語法:
#直接在select語句之前加,上關鍵字explain / desc EXPLAIN SELECT 字段列表FROM 表名WHERE 條件;

EXPLAIN執行計劃各字段含義:
Id:
select查詢的序列號,表示查詢中執行select子句或者是操作表的順序(id相同,執行順序從上到下; id不同,值越大,越先執行)。
select_ type:
表示SELECT的類型,常見的取值有SIMPLE (簡單表,即不使用表連接或者子查詢)、PRIMARY (主查詢,即外層的查詢)、UNION (UNION 中的第二個或者後面的查詢語句)、SUBQUERY (SELECT/WHERE之後包含瞭子查詢)等
type:
表示連接類型,性能由好到差的連接類型為NULL、system、 const、 eq_ref、ref、range、index、all 。
possible_ key:
顯示可能應用在這張表上的索引,一個或多個。
Key:
實際使用的索引,如果為NULL,則沒有使用索引。
Key_ len:
表示索引中使用的字節數,該值為索引字段最大可能長度,並非實際使用長度,在不損失精確性的前提下,長度越短越好。
rows:
MySQL認為必須要執行查詢的行數,在innodb引擎的表中,是-一個估計值,可能並不總是準確的。
filtered:
表示返回結果的行數占需讀取行數的百分比,filtered 的值越大越好。
七、索引使用
1. 索引效率
當數據量特別大時,在未建立索引之前,執行SQL,查詢無索引字段SQL的耗時非常大。
針對字段創建索引後。
再次執行相同的SQL語句,SQL的耗時將大大減小。
2. 聯合索引
最左前綴法則
如果索引瞭多列(聯合索引) , 要遵守最左前綴法則。最左前綴法則指的是查詢從索引的最左列開始,查詢必須包含最左邊的列(否則全部失敗),並且不跳過索引中的列。
如果跳躍某一列,索引將部分失效(後面的字段索引失效)。
范圍查詢
聯合索引中,出現范圍查詢(>,<),范圍查詢右側的列索引失效,一般使用>=或者<=可以有效規避這種情況
3. 索引失效
索引列運算
不要在索引列上進行運算操作,索引將失效。
字符串不加引號
字符串類型字段使用時,不加引號,索引將失效。
模糊查詢
如果僅僅是尾部模糊匹配,索引不會失效。如果是頭部模糊匹配,索引失效。
or連接的條件
用or分割開的條件,如果or前的條件 中的列有索引,而後面的列中沒有索引,那麼涉及的索引都不會被用到。隻有兩側都使用索引時索引才會生效。
數據分佈影響
如果MySQL評估使用索引比全表掃描更慢,則不使用索引、索引失效。
4. SQL提示
SQL提示,是優化數據庫的一個重要手段,簡單來說,就是在SQL語句中加入一些人為的提示來達到優化操作的目的。
# use index: explain select * from tb_name use index(索引名) where profession= 'xxxx'; # ignore index: explain select * from tb_name ignore index(索引名) where profession='xxxx'; # force index: explain select * from tb_name force index(索引名) where profession='xxxx';
5. 覆蓋索引
盡量使用覆蓋索引(查詢使用瞭索引,並且需要返回的列,在該索引中已經全部能夠找到),減少 select * 。
在Extra字段中出現的數據分析:
using index condition:查找使用瞭索引,但是需要回表查詢數據
using where; using index:查找使用瞭索引,但是需要的數據都在索引列中能找到,所以不需要回表查詢數據
6. 前綴索引
當字段類型為字符串(varchar, text等 ),時,有時候需要索引很長的字符串,這會讓索引變得很大,查詢時,浪費大量的磁盤IO,影響查詢效率。此時可以隻將字符串的一部分前綴建立索引,這樣可以大大節約索引空間,從而提高索引效率。
#語法 create index idx_xxx on table_ name(column(n)) ; #前綴長度 可以根據索引的選擇性來決定,而選擇性是指不重復的索引值(基數)和數據表的記錄總數的比值,索引選擇性越高則查詢效率越高, 唯一索引的選擇性是1,這是最好的索引選擇性,性能也是最好的。 # 求取選擇性 select count(distinct email)/ count(*) from tb_name ; select count(distinct substring(email,1 ,5)) / count(*) from tb_name ;
7. 單列索引與聯合索引
單列索引:即一個索引隻包含單個列。
聯合索引:即一個索引包含瞭多個列。
在業務場景中,如果存在多個查詢條件,考慮針對於查詢字段建立索引時,建議建立聯合索引(效率較高、有效規避一些回表查詢),而非單列索引。
多條件聯合查詢時,MySQL優化器會評估哪個字段的索引效率更高,會選擇該索引完成本次查詢。當創建瞭聯合索引時會有單列索引幹擾,我們可以指定聯合索引查詢。
聯合索引情況:
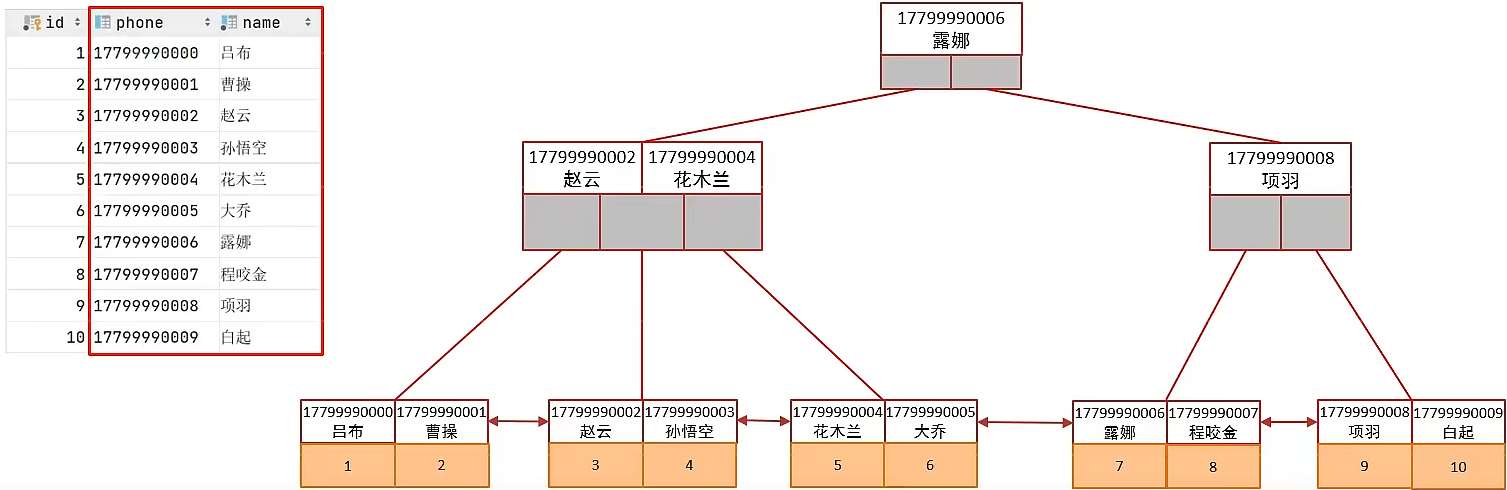
八、索引設計原則
1. 針對於數據量較大,且查詢比較頻繁的表建立索引。
2.針對於常作為查詢條件(where) 、排序(order by)、分組(group by)操作的字段建立索引。
3.盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高。
4.如果是字符串類型的字段, 字段的長度較長,可以針對於字段的特點,建立前綴索引。
5.盡量使用聯合索引, 減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲空間,避免回表,提高查詢效率。
6.要控制索引的數量, 索引並不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率。
7.如果索引列不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用於查詢。
總結
本篇文章就到這裡瞭,希望能夠給你帶來幫助,也希望您能夠多多關註WalkonNet的更多內容!