python機器學習之神經網絡
手寫數字識別算法
import pandas as pd
import numpy as np
from sklearn.neural_network import MLPRegressor #從sklearn的神經網絡中引入多層感知器
data_tr = pd.read_csv('BPdata_tr.txt') # 訓練集樣本
data_te = pd.read_csv('BPdata_te.txt') # 測試集樣本
X=np.array([[0.568928884039633],[0.379569493792951]]).reshape(1, -1)#預測單個樣本
#參數:hidden_layer_sizes中間層的個數 activation激活函數默認relu f(x)= max(0,x)負值全部舍去,信號相應正向傳播效果好
#random_state隨機種子,max_iter最大迭代次數,即結束,learning_rate_init學習率,學習速度,步長
model = MLPRegressor(hidden_layer_sizes=(10,), activation='relu',random_state=10, max_iter=8000, learning_rate_init=0.3) # 構建模型,調用sklearn實現神經網絡算法
model.fit(data_tr.iloc[:, :2], data_tr.iloc[:, 2]) # 模型訓練(將輸入數據x,結果y放入多層感知器擬合建立模型) .iloc是按位置取數據
pre = model.predict(data_te.iloc[:, :2]) # 模型預測(測試集數據預測,將實際結果與預測結果對比)
pre1 = model.predict(X)#預測單個樣本,實際值0.467753075712819
err = np.abs(pre - data_te.iloc[:, 2]).mean()# 模型預測誤差(|預測值-實際值|再求平均)
print("模型預測值:",pre,end='\n______________________________\n')
print('模型預測誤差:',err,end='\n++++++++++++++++++++++++++++++++\n')
print("單個樣本預測值:",pre1,end='\n++++++++++++++++++++++++++++++++\n')
#查看相關參數。
print('權重矩陣:','\n',model.coefs_) #list,length n_layers - 1,列表中的第i個元素表示對應於層i的權重矩陣。
print('偏置矩陣:','\n',model.intercepts_) #list,length n_layers - 1,列表中的第i個元素表示對應於層i + 1的偏置矢量。

數字手寫識別系統
#數字手寫識別系統,DBRHD和MNIST是數字手寫識別的數據集
import numpy as np # 導入numpy工具包
from os import listdir # 使用listdir模塊,用於訪問本地文件
from sklearn.neural_network import MLPClassifier #從sklearn的神經網絡中引入多層感知器
#自定義函數,將圖片轉換成向量
def img2vector(fileName):
retMat = np.zeros([1024], int) # 定義返回的矩陣,大小為1*1024
fr = open(fileName) # 打開包含32*32大小的數字文件
lines = fr.readlines() # 讀取文件的所有行
for i in range(32): # 遍歷文件所有行
for j in range(32): # 並將01數字存放在retMat中
retMat[i * 32 + j] = lines[i][j]
return retMat
#自定義函數,獲取數據集
def readDataSet(path):
fileList = listdir(path) # 獲取文件夾下的所有文件
numFiles = len(fileList) # 統計需要讀取的文件的數目
dataSet = np.zeros([numFiles, 1024], int) # 用於存放所有的數字文件juzheng
hwLabels = np.zeros([numFiles, 10]) # 用於存放對應的one-hot標簽(每個文件都對應一個10列的矩陣)
for i in range(numFiles): # 遍歷所有的文件
filePath = fileList[i] # 獲取文件名稱/路徑
digit = int(filePath.split('_')[0]) # 通過文件名獲取標簽,split返回分割後的字符串列表
hwLabels[i][digit] = 1.0 # 將對應的one-hot標簽置1 .one-hot編碼,又稱獨熱編碼、一位有效編碼.one-hot向量將類別變量轉換為機器學習算法易於利用的一種形式的過程,這個向量的表示為一項屬性的特征向量,也就是同一時間隻有一個激活點(不為0),這個向量隻有一個特征是不為0的,其他都是0,特別稀疏。
dataSet[i] = img2vector(path + '/' + filePath) # 讀取文件內容
return dataSet, hwLabels
#讀取訓練數據,並訓練模型
train_dataSet, train_hwLabels = readDataSet('trainingDigits')
#參數:hidden_layer_sizes中間層的個數,activation激活函數 logistic:f(x)=1/(1+exp(-x))將值映射在一個0~1的范圍內。
#solver權重優化的求解器adam默認,用於較大的數據集,lbfgs用於小型的數據集收斂的更快效果更好。max_iter迭代次數越多越準確
clf = MLPClassifier(hidden_layer_sizes=(50,),activation='logistic', solver='adam',learning_rate_init=0.001, max_iter=700)
clf.fit(train_dataSet, train_hwLabels)#數據集,標簽,擬合
# 讀取測試數據對測試集進行預測
dataSet, hwLabels = readDataSet('testDigits')
res = clf.predict(dataSet) #預測結果是標簽([numFiles, 10]的矩陣)
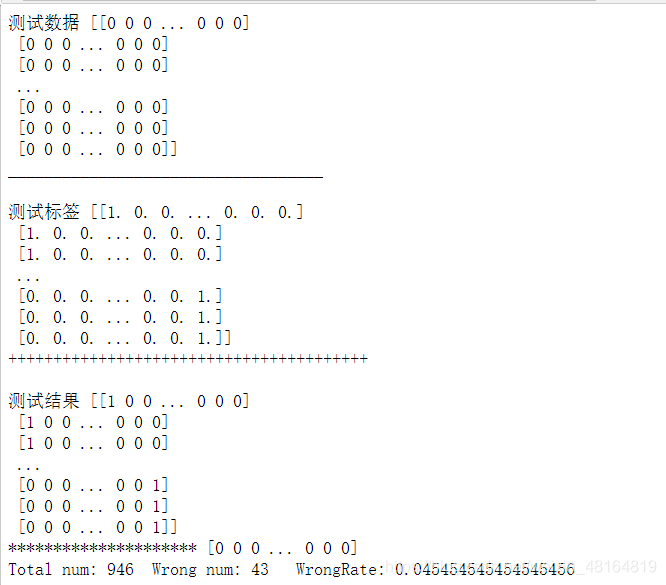
print("測試數據",dataSet,'\n___________________________________\n')
print("測試標簽",hwLabels,'\n++++++++++++++++++++++++++++++++++++++++\n')
print("測試結果",res)
error_num = 0 # 統計預測錯誤的數目
num = len(dataSet) # 測試集的數目
for i in range(num): # 遍歷預測結果
# 比較長度為10的數組,返回包含01的數組,0為不同,1為相同
# 若預測結果與真實結果相同,則10個數字全為1,否則不全為1
if np.sum(res[i] == hwLabels[i]) < 10:
error_num += 1
print("Total num:", num, " Wrong num:",error_num, " WrongRate:", error_num / float(num))
可視化MNIST是數字手寫識別的數據集
from keras.datasets import mnist#導入數字手寫識別系統的數據集
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = mnist.load_data()
#以2*2(2行2列)圖的方式展現
plt.subplot(221)
plt.imshow(X_train[1], cmap=plt.get_cmap('gray_r'))#白底黑字
plt.subplot(222)
plt.imshow(X_train[2], cmap=plt.get_cmap('gray'))#黑底白字
plt.subplot(223)
plt.imshow(X_train[3], cmap=plt.get_cmap('gray'))
plt.subplot(224)
plt.imshow(X_train[4], cmap=plt.get_cmap('gray'))
# show the plot
plt.show()

到此這篇關於python機器學習之神經網絡的文章就介紹到這瞭,更多相關python神經網絡內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found