通過底層源碼理解YOLOv5的Backbone
YOLOv5的Backbone設計
在上一篇文章《YOLOV5的anchor設定》中我們討論瞭anchor的產生原理和檢測過程,對YOLOv5的網絡結構有瞭大致的瞭解。接下來,我們將聚焦於YOLOv5的Backbone,深入到底層源碼中體會v5的Backbone設計。
1 Backbone概覽及參數
# Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]
yolov5s的backbone部分如上,其網絡結構使用yaml文件配置,通過./models/yolo.py解析文件加瞭一個輸入構成的網絡模塊。與v3和v4所使用的config設置的網絡不同,yaml文件中的網絡組件不需要進行疊加,隻需要在配置文件中設置number即可。
1.1 Param
# Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple
nc: 8
代表數據集中的類別數目,例如MNIST中含有0-9共10個類.
depth_multiple: 0.33
用來控制模型的深度,僅在number≠1時啟用。 如第一個C3層(c3具體是什麼後續介紹)的參數設置為[-1, 3, C3, [128]],其中number=3,表示在v5s中含有1個C3(3*0.33);同理,v5l中的C3個數就是3(v5l的depth_multiple參數為1)。
width_multiple: 0.50
用來控制模型的寬度,主要作用於args中的ch_out。如第一個Conv層,ch_out=64,那麼在v5s實際運算過程中,會將卷積過程中的卷積核設為64×0.5,所以會輸出32通道的特征圖。
1.2 backbone
# YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]
- from:-n代表是從前n層獲得的輸入,如-1表示從前一層獲得輸入
- number:表示網絡模塊的數目,如[-1, 3, C3, [128]]表示含有3個C3模塊
- model:表示網絡模塊的名稱,具體細節可以在./models/common.py查看,如Conv、C3、SPPF都是已經在common中定義好的模塊
- args:表示向不同模塊內傳遞的參數,即[ch_out, kernel, stride, padding, groups],這裡連ch_in都省去瞭,因為輸入都是上層的輸出(初始ch_in為3)。為瞭修改過於麻煩,這裡輸入的獲取是從./models/yolo.py的def parse_model(md, ch)函數中解析得到的。
1.3 Exp
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
input:3x640x640
[ch_out, kernel, stride, padding]=[64, 6, 2, 2]
故新的通道數為64×0.5=32
根據特征圖計算公式:Feature_new=(Feature_old-kernel+2xpadding)/stride+1可得:
新的特征圖尺寸為:Feature_new=(640-6+2×2)/2+1=320
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
input:32x320x320
[ch_out, kernel, stride]=[128, 3, 2]
同理可得:新的通道數為64,新的特征圖尺寸為160
2 Backbone組成
v6.0版本的Backbone去除瞭Focus模塊(便於模型導出部署),Backbone主要由CBL、BottleneckCSP/C3以及SPP/SPPF等組成,具體如下圖所示:
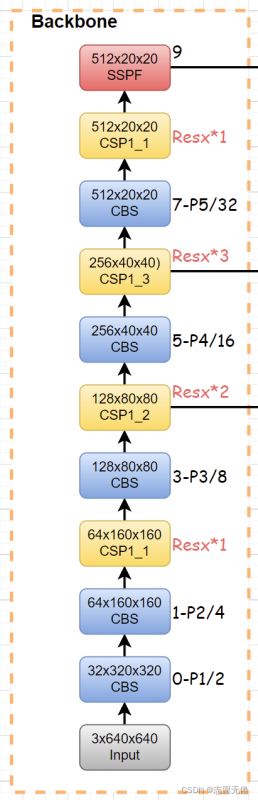
3.1 CBS

CBS模塊其實沒什麼好稀奇的,就是Conv+BatchNorm+SiLU,這裡著重講一下Conv的參數,就當復習pytorch的卷積操作瞭,先上CBL源碼:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
#其中nn.Identity()是網絡中的占位符,並沒有實際操作,在增減網絡過程中,可以使得整個網絡層數據不變,便於遷移權重數據;nn.SiLU()一種激活函數(S形加權線性單元)。
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):#正態分佈型的前向傳播
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):#普通前向傳播
return self.act(self.conv(x))
由源碼可知:Conv()包含7個參數,這些參數也是二維卷積Conv2d()中的重要參數。ch_in, ch_out, kernel, stride沒什麼好說的,展開說一下後三個參數:
padding
從我現在看到的主流卷積操作來看,大多數的研究者不會通過kernel來改變特征圖的尺寸,如googlenet中3×3的kernel設定瞭padding=1,所以當kernel≠1時需要對輸入特征圖進行填充。當指定p值時按照p值進行填充,當p值為默認時則通過autopad函數進行填充:
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
#如果k是整數,p為k與2整除後向下取整;如果k是列表等,p對應的是列表中每個元素整除2。
return p
這裡作者考慮到對不同的卷積操作使用不同大小的卷積核時padding也需要做出改變,所以這裡在為p賦值時會首先檢查k是否為int,如果k為列表則對列表中的每個元素整除。
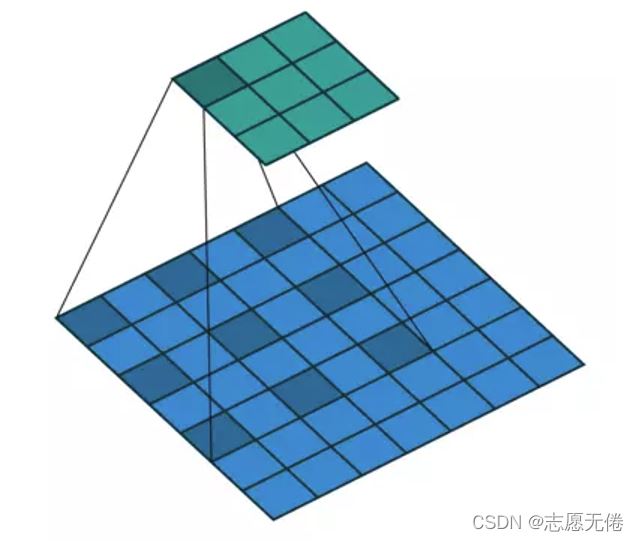
groups
代表分組卷積,如下圖所示

groups – Number of blocked connections from input channels to output
- At groups=1, all inputs are convolved to all outputs.
- At groups=2, the operation becomes equivalent to having two conv layers side by side, each seeing half the input channels, and producing half the output channels, and both subsequently concatenated.
- At groups= in_channels, each input channel is convolved with its own set of filters, of size: ⌊(out_channels)/(in_channels)⌋.
act
決定是否對特征圖進行激活操作,SiLU表示使用Sigmoid進行激活。
one more thing:dilation
Conv2d中還有一個重要的參數就是空洞卷積dilation,通俗解釋就是控制kernel點(卷積核點)間距的參數,通過改變卷積核間距實現特征圖及特征信息的保留,在語義分割任務中空洞卷積比較有效。
3.2 CSP/C3
CSP即backbone中的C3,因為在backbone中C3存在shortcut,而在neck中C3不使用shortcut,所以backbone中的C3層使用CSP1_x表示,neck中的C3使用CSP2_x表示。
3.2.1 CSP結構
接下來讓我們來好好梳理一下backbone中的C3層的模塊組成。先上源碼:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
從源碼中可以看出:輸入特征圖一條分支先經過.cv1,再經過.m,得到子特征圖1;另一分支經過.cv2後得到子特征圖2。最後將子特征圖1和子特征圖2拼接後輸入.cv3得到C3層的輸出,如下圖所示。 這裡的CV操作容易理解,就是前面的Conv2d+BN+SiLU,關鍵是.m操作。

.m操作使用nn.Sequential將多個Bottleneck(圖示中我以Resx命名)串接到網絡中,for loop中的n即網絡配置文件args中的number,也就是將number×depth_multiple個Bottleneck串接到網絡中。那麼,Bottleneck又是個什麼玩意呢?
3.2.2 Bottleneck
要想瞭解Bottleneck,還要從Resnet說起。在Resnet出現之前,人們的普遍為網絡越深獲取信息也越多,模型泛化效果越好。然而隨後大量的研究表明,網絡深度到達一定的程度後,模型的準確率反而大大降低。這並不是過擬合造成的,而是由於反向傳播過程中的梯度爆炸和梯度消失。也就是說,網絡越深,模型越難優化,而不是學習不到更多的特征。
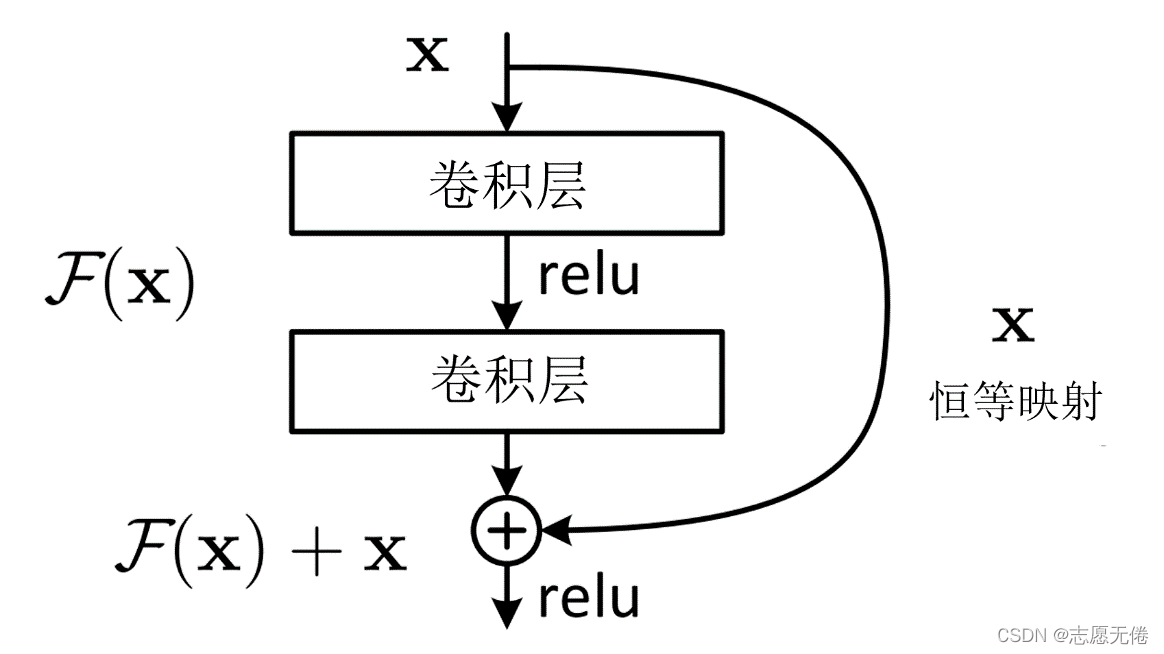
為瞭能讓深層次的網絡模型達到更好的訓練效果,殘差網絡中提出的殘差映射替換瞭以往的基礎映射。對於輸入x,期望輸出H(x),網絡利用恒等映射將x作為初始結果,將原來的映射關系變成F(x)+x。與其讓多層卷積去近似估計H(x) ,不如近似估計H(x)-x,即近似估計殘差F(x)。因此,ResNet相當於將學習目標改變為目標值H(x)和x的差值,後面的訓練目標就是要將殘差結果逼近於0。
殘差模塊有什麼好處呢?
1.梯度彌散方面。加入ResNet中的shortcut結構之後,在反傳時,每兩個block之間不僅傳遞瞭梯度,還加上瞭求導之前的梯度,這相當於把每一個block中向前傳遞的梯度人為加大瞭,也就會減小梯度彌散的可能性。
2.特征冗餘方面。正向卷積時,對每一層做卷積其實隻提取瞭圖像的一部分信息,這樣一來,越到深層,原始圖像信息的丟失越嚴重,而僅僅是對原始圖像中的一小部分特征做提取。這顯然會發生類似欠擬合的現象。加入shortcut結構,相當於在每個block中又加入瞭上一層圖像的全部信息,一定程度上保留瞭更多的原始信息。
在resnet中,人們可以使用帶有shortcut的殘差模塊搭建幾百層甚至上千層的網絡,而淺層的殘差模塊被命名為Basicblock(18、34),深層網絡所使用的的殘差模塊,就被命名為瞭Bottleneck(50+)。

Bottleneck與Basicblock最大的區別是卷積核的組成。 Basicblock由兩個3×3的卷積層組成,Bottleneck由兩個1×1卷積層夾一個3×3卷積層組成:其中1×1卷積層降維後再恢復維數,讓3×3卷積在計算過程中的參數量更少、速度更快。
第一個1×1的卷積把256維channel降到64維,然後在最後通過1×1卷積恢復,整體上用的參數數目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的話就是兩個3x3x256的卷積,參數數目: 3x3x256x256x2 = 1179648,差瞭16.94倍。
Bottleneck減少瞭參數量,優化瞭計算,保持瞭原有的精度。
說瞭這麼多,都是為瞭給CSP中的Bottleneck做前情提要,我們再回頭看CSP中的Bottleneck其實就更清楚瞭:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
可以看到,CSP中的Bottleneck同resnet模塊中的類似,先是1×1的卷積層(CBS),然後再是3×3的卷積層,最後通過shortcut與初始輸入相加。但是這裡與resnet的不通點在於:CSP將輸入維度減半運算後並未再使用1×1卷積核進行升維,而是將原始輸入x也降瞭維,采取concat的方法進行張量的拼接,得到與原始輸入相同維度的輸出。其實這裡能區分一點就夠瞭:resnet中的shortcut通過add實現,是特征圖對應位置相加而通道數不變;而CSP中的shortcut通過concat實現,是通道數的增加。二者雖然都是信息融合的主要方式,但是對張量的具體操作又不相同.

其次,對於shortcut是可根據任務要求設置的,比如在backbone中shortcut=True,neck中shortcut=False。
當shortcut=True時,Resx如圖:

當shortcut=False時,Resx如圖:

這其實也是YOLOv5為人稱贊的地方,代碼更體系、代碼冗餘更少,僅需要指定一個參數便可以將Bottleneck和普通卷積聯合在一起使用,減少瞭代碼量的同時也使整體感觀得到提升。
3.3 SSPF
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
SSPF模塊將經過CBS的x、一次池化後的y1、兩次池化後的y2和3次池化後的self.m(y2)先進行拼接,然後再CBS提取特征。 仔細觀察不難發現,雖然SSPF對特征圖進行瞭多次池化,但是特征圖尺寸並未發生變化,通道數更不會變化,所以後續的4個輸出能夠在channel維度進行融合。這一模塊的主要作用是對高層特征進行提取並融合,在融合的過程中作者多次運用最大池化,盡可能多的去提取高層次的語義特征。

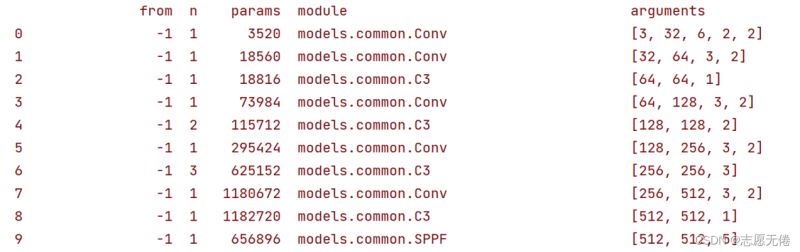
YOLOv5s的Backbone總覽
最後,結合上述的講解應該就不難理解v5s的backbone瞭
總結
到此這篇關於通過底層源碼理解YOLOv5中Backbone的文章就介紹到這瞭,更多相關YOLOv5 Backbone詳解內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- YOLOv5改進之添加SE註意力機制的詳細過程
- Pytorch實現ResNet網絡之Residual Block殘差塊
- 如何將yolov5中的PANet層改為BiFPN詳析
- yolov5中head修改為decouple head詳解
- Yolov5更換BiFPN的詳細步驟總結