為什麼Java單例模式一定要加 volatile
前言:
單例模式的實現方法有很多種,如餓漢模式、懶漢模式、靜態內部類和枚舉等,當面試官問到“為什麼單例模式一定要加 volatile?”時,那麼他指的是為什麼懶漢模式中的私有變量要加 volatile?
懶漢模式指的是對象的創建是懶加載的方式,並不是在程序啟動時就創建對象,而是第一次被真正使用時才創建對象。
要解釋為什麼要加 volatile?我們先來看懶漢模式的具體實現代碼:
public class Singleton {
// 1.防止外部直接 new 對象破壞單例模式
private Singleton() {}
// 2.通過私有變量保存單例對象【添加瞭 volatile 修飾】
private static volatile Singleton instance = null;
// 3.提供公共獲取單例對象的方法
public static Singleton getInstance() {
if (instance == null) { // 第 1 次效驗
synchronized (Singleton.class) {
if (instance == null) { // 第 2 次效驗
instance = new Singleton();
}
}
}
return instance;
}
}
從上述代碼可以看出,為瞭保證線程安全和高性能,代碼中使用瞭兩次 if 和 synchronized 來保證程序的執行。那既然已經有 synchronized 來保證線程安全瞭,為什麼還要給變量加 volatile 呢? 在解釋這個問題之前,我們先要搞懂一個前置知識:volatile 有什麼用呢?
1.volatile 作用
volatile 有兩個主要的作用,第一,解決內存可見性問題,第二,防止指令重排序。
1.1 內存可見性問題
所謂內存可見性問題,指的是多個線程同時操作一個變量,其中某個線程修改瞭變量的值之後,其他線程感知不到變量的修改,這就是內存可見性問題。 而使用 volatile 就可以解決內存可見性問題,比如以下代碼,當沒有添加 volatile 時,
它的實現如下:
private static boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
// 如果 flag 變量為 true 就終止執行
while (!flag) {
}
System.out.println("終止執行");
}
});
t1.start();
// 1s 之後將 flag 變量的值修改為 true
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("設置 flag 變量的值為 true!");
flag = true;
}
});
t2.start();
}
以上程序的執行結果如下:
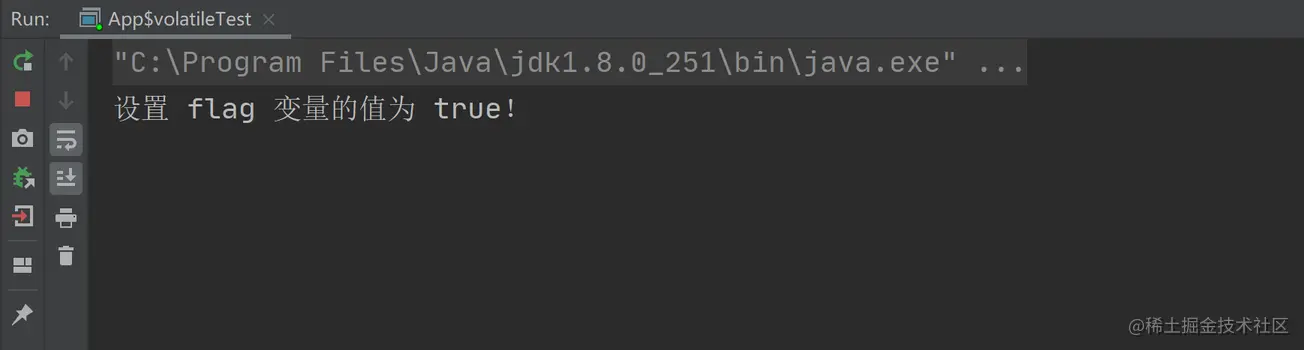
然而,以上程序執行瞭 N 久之後,依然沒有結束執行,這說明線程 2 在修改瞭 flag 變量之後,線程 1 根本沒有感知到變量的修改。
那麼接下來,我們嘗試給 flag 加上 volatile,實現代碼如下:
public class volatileTest {
private static volatile boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
// 如果 flag 變量為 true 就終止執行
while (!flag) {
}
System.out.println("終止執行");
}
});
t1.start();
// 1s 之後將 flag 變量的值修改為 true
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("設置 flag 變量的值為 true!");
flag = true;
}
});
t2.start();
}
}
以上程序的執行結果如下:
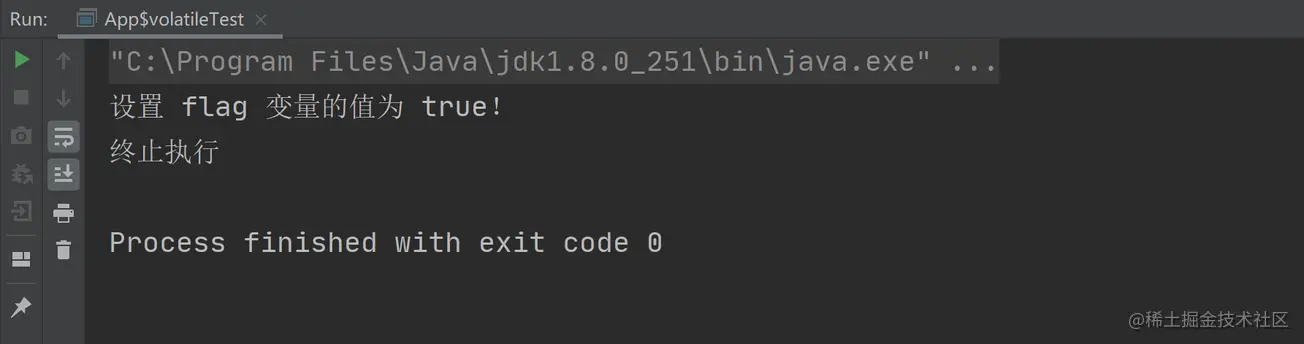
從上述執行結果我們可以看出,使用 volatile 之後就可以解決程序中的內存可見性問題瞭。
1.2 防止指令重排序
指令重排序是指在程序執行過程中,編譯器或 JVM 常常會對指令進行重新排序,已提高程序的執行性能。 指令重排序的設計初衷確實很好,在單線程中也能發揮很棒的作用,然而在多線程中,使用指令重排序就可能會導致線程安全問題瞭。
所謂線程安全問題是指程序的執行結果,和我們的預期不相符。比如我們預期的正確結果是 0,但程序的執行結果卻是 1,那麼這就是線程安全問題。
而使用 volatile 可以禁止指令重排序,從而保證程序在多線程運行時能夠正確執行。
2.為什麼要用 volatile?
回到主題,我們在單例模式中使用 volatile,主要是使用 volatile 可以禁止指令重排序,從而保證程序的正常運行。這裡可能會有讀者提出疑問,不是已經使用瞭 synchronized 來保證線程安全嗎?那為什麼還要再加 volatile 呢?
看下面的代碼:
public class Singleton {
private Singleton() {}
// 使用 volatile 禁止指令重排序
private static volatile Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) { // ①
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // ②
}
}
}
return instance;
}
}
註意觀察上述代碼,我標記瞭第 ① 處和第 ② 處的兩行代碼。給私有變量加 volatile 主要是為瞭防止第 ② 處執行時,也就是“instance = new Singleton()”執行時的指令重排序的,這行代碼看似隻是一個創建對象的過程,然而它的實際執行卻分為以下 3 步:
- 創建內存空間。
- 在內存空間中初始化對象 Singleton。
- 將內存地址賦值給 instance 對象(執行瞭此步驟,instance 就不等於 null 瞭)。
試想一下,如果不加 volatile,那麼線程 1 在執行到上述代碼的第 ② 處時就可能會執行指令重排序,將原本是 1、2、3 的執行順序,重排為 1、3、2。但是特殊情況下,線程 1 在執行完第 3 步之後,如果來瞭線程 2 執行到上述代碼的第 ① 處,判斷 instance 對象已經不為 null,但此時線程 1 還未將對象實例化完,那麼線程 2 將會得到一個被實例化“一半”的對象,從而導致程序執行出錯,這就是為什麼要給私有變量添加 volatile 的原因瞭。
總結
使用 volatile 可以解決內存可見性問題和防止指令重排序,我們在單例模式中使用 volatile 主要是使用 volatile 的後一個特性(防止指令重排序),從而避免多線程執行的情況下,因為指令重排序而導致某些線程得到一個未被完全實例化的對象,從而導致程序執行出錯的情況。
到此這篇關於為什麼Java單例一定要加 volatile的文章就介紹到這瞭,更多相關Java單例內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Java中Volatile關鍵字能保證原子性嗎
- Java多線程之搞定最後一公裡詳解
- Java 實例解析單例模式
- 基於Java利用static實現單例模式
- Java並發編程之Volatile變量詳解分析