python memory_profiler庫生成器和迭代器內存占用的時間分析
不進行計算時,生成器和list空間占用
import time
from memory_profiler import profile
@profile(precision=4)
def list_fun():
start = time.time()
total = ([i for i in range(5000000)])
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = (i for i in range(5000000))
print('gent_spend_time:',time.time()-gent_start)
iter_fun()
gent_func()

顯示結果的含義:第一列表示已分析代碼的行號,第二列(Mem 使用情況)表示執行該行後 Python 解釋器的內存使用情況。第三列(增量)表示當前行相對於最後一行的內存差異。最後一列(行內容)打印已分析的代碼。
分析:在不進行計算的情況下,列表list和迭代器會占用空間,但對於生成器不會占用空間
當需要計算時,list和生成器的花費時間和占用內存
使用sum內置函數,list和生成器求和10000000個數據,list內存占用較大,生成器花費時間大概是list的兩倍
import time
from memory_profiler import profile
@profile(precision=4)
def iter_fun():
start = time.time()
total = sum([i for i in range(10000000)])
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = sum(i for i in range(10000000))
print('gent_spend_time:',time.time()-gent_start)
iter_fun()
gent_func()
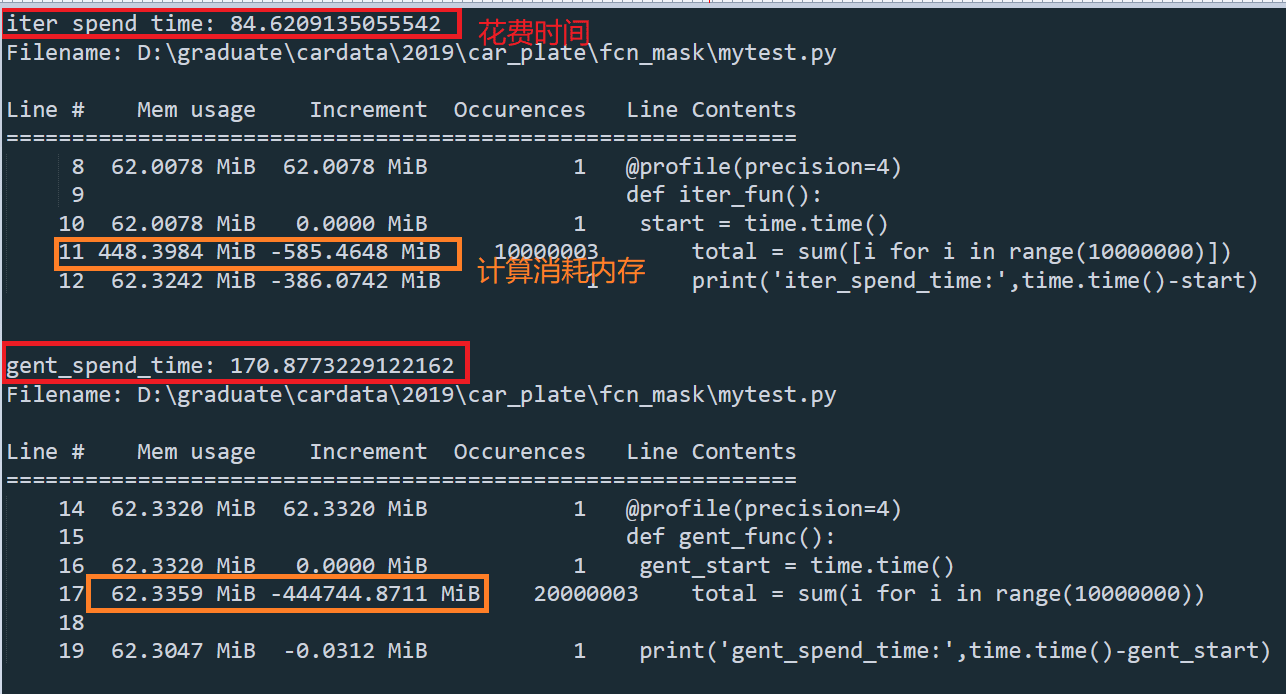
比較分析,如果需要對數據進行迭代使用時,生成器方法的耗時較長,但內存使用方面還是較少,因為使用生成器時,內存隻存儲每次迭代計算的數據。分析原因時個人認為,生成器的迭代計算過程中,在迭代數據和計算直接不斷轉換,相比與迭代器對象中先將數據全部保存在內存中(雖然占內存,但讀取比再次迭代要快),因此,生成器比較費時間,但占用內存小。
記錄數據循環求和500000個數據,迭代器和生成器循環得到時
總結:幾乎同時完成,迭代器的占用內存較大
import time
from memory_profiler import profile
itery = iter([i for i in range(5000000)])
gent = (i for i in range(5000000))
@profile(precision=4)
def iter_fun():
start = time.time()
total= 0
for item in itery:
total+=item
print('iter:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = 0
for item in gent:
total+=item
print('gent:',time.time()-gent_start)
iter_fun()
gent_func()

list,迭代器和生成器共同使用sum計算5000000個數據時間比較
總結:list+sum和迭代器+sum計算時長差不多,但生成器+sum計算的時長幾乎長一倍,
import time
from memory_profiler import profile
@profile(precision=4)
def list_fun():
start = time.time()
print('start!!!')
list_data = [i for i in range(5000000)]
total = sum(list_data)
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def iter_fun():
start = time.time()
total = 0
total = sum(iter([i for i in range(5000000)]))
print('total:',total)
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = sum(i for i in range(5000000))
print('total:',total)
print('gent_spend_time:',time.time()-gent_start)
list_fun()
iter_fun()
gent_func()

到此這篇關於python memory_profiler庫生成器和迭代器內存占用的時間分析的文章就介紹到這瞭,更多相關python的memory_profiler 內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python利用memory_profiler查看內存占用情況
- python函數運行內存時間等性能檢測工具
- Python中迭代器與生成器的用法
- Python 循環讀取數據內存不足的解決方案
- python 內置函數-range()+zip()+sorted()+map()+reduce()+filter()