python自然語言處理之字典樹知識總結
一、什麼是字典樹
在自然語言處理中,字符串集合常用字典樹存儲,這是一種字符串上的樹形數據結構。字典樹中每條邊都對應一個字,從根節點往下的路徑構成一個個字符串。
字典樹並不直接在節點上存儲字符串,而是將詞語視作根節點到某節點之間的一條路徑,並在終點節點上做個標記(表明到該節點就結束瞭)。
要查詢一個單詞,指需要順著這條路徑從根節點往下走。如果能走到標記的節點,則說明該字符串在集合中,否則說明不在。下圖為字典樹結構示例:
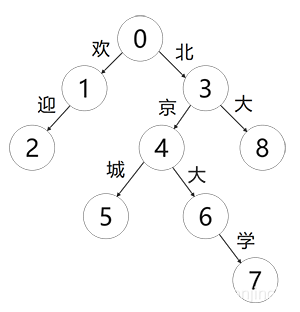
如上圖所示,每條路徑都是一個詞匯,且沒有子節點就可以判定該條路徑結尾瞭。具體可以映射為下標所示:
| 詞語 | 路徑 |
| 歡迎 | 0-1-2 |
| 北大 | 0-3-8 |
| 北京城 | 0-3-4-5 |
| 北京大學 | 0-3-4-6-7 |
至於字典樹的實現,相信隻要認真學過數據結構的讀者,都能手到擒來,這裡不在贅述。因為HanLP庫已經提供瞭多種字典樹。
二、DoubleArrayTrieSegment
認識DoubleArrayTrieSegment類之前,我們需要瞭解雙數組字典書的概念。
我們都知道,在樹中遍歷查找之時,我們一般用二分查找,假如某一個樹的節點有N個節點,那麼其復雜度就為O(logN),這樣查找起來一條一條樹的遍歷會非常的慢,所以就誕生瞭雙數組字典樹的概念。
雙數組字典樹(DAT)是一種狀態轉移復雜度為常數的數據結構。那麼什麼是狀態呢?從確定有限狀態自動機(DFA)的角度來講,每個節點都是一個狀態,狀態表示當前已查詢到的前綴。
從父節點到子節點的移動過程可以看作一次狀態轉移。在按照某個字符進行狀態轉移前,我們會向父節點詢問該字符與子節點的映射關系(也就是一條路徑一條邊)。如果父節點有滿足條件的邊,則狀態轉移到子節點;否則立即失敗,查詢不到。當成功完成瞭全部轉移時,我們就拿到瞭最後一個狀態,詢問該狀態是否時最終狀態。如果是,就查詢到該詞匯,否則該單詞不存在於字典中。
比如我們查詢首圖的“北京大學”,狀態開始為0,查詢到北時狀態為3,查詢到京時狀態為4,查詢到大時狀態為6,查詢到學時狀態為7,最後判斷7是否還有子節點,如果沒有匹配該詞匯,如果有該詞匯不在字典中。比如查詢“北京大”就不在詞匯中。
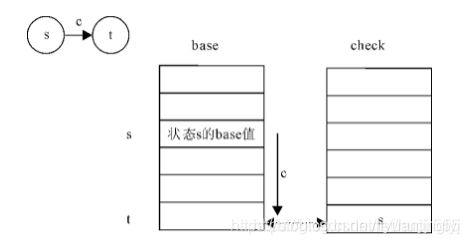
而雙數組字典由base與check兩個數組組成,其中base數組即節點,也是狀態,分為空閑狀態與占用狀態,check數組為每個元素表示某個狀態的前驅狀態。具體公式如下:
base[s] + c = t check[t] = s
base樹組中的s代表當前狀態的下標,t代表轉移狀態的下標,c代表輸入字符的數值
base[s] + c = t //表示一次狀態轉移
由於轉移後狀態下標為t,且父子關系是唯一的,所以可通過檢驗當前元素的前驅狀態確定轉移是否成功
check[t] = s //檢驗狀態轉移是否成功
這種算法相對於傳統的Trie樹二分查找的優點是,隻需要一個加法一次比較即可完成一次狀態轉移,隻花費瞭常數時間,下面給出瞭雙數組Tree樹的原理圖(註意觀察狀態轉移的過程)
瞭解瞭雙數組字典樹的原理,我們就可以來學習DoubleArrayTrieSegment,DoubleArrayTrieSegment分詞器是對DAT(雙數組字典樹)最長匹配的封裝,默認加載hanlp.properites中CoreDictionaryPath指定的詞典。
對應的python代碼如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=False#分詞結果不顯示詞性
segment=DoubleArrayTrieSegment()
print(segment.seg("在來到這個世界之前,一起都很Happy"))
運行之後,得到如下圖所示的結果:

當然,這是HanLP提供給我們的默認詞典,如果想加載自己的詞典,或者前文提到的其他開源的詞典庫,可以替換代碼如下所示:
DoubleArrayTrieSegment(["詞典1","詞典2"])
但是不知道讀者註意到瞭沒有,上面的英文happy,它給我們拆成瞭單個的字母,但其實這是一個整體,如果這裡替換成數字,也是一個一個數字,那麼如何不讓其拆開呢?
我們來看一段代碼:
if __name__ == "__main__":
HanLP.Config.ShowTermNature=True
segment=DoubleArrayTrieSegment()
segment.enablePartOfSpeechTagging(True)
print(segment.seg("在來到這個世界之前,一起都很Happy"))
enablePartOfSpeechTagging函數的意思是激活數字與英文識別,同時我們把ShowTermNature改為True,觀察其輸出的結果:

這裡與我們前面自己寫的算法輸出一模一樣,有分開的詞匯以及詞匯的標記屬性。
三、AhoCorasickDoubleArrayTrieSegment
雖然雙數組字典樹能遍歷大量的數據,但是如果數據比較長的,這些長的詞匯又比較多的話,比如“受命於天,既壽永昌”算一個詞匯,那麼其處理起來時間復雜度依舊非常耗時。所以,我們就需要使用ACDAT進行遍歷。
這裡博主不講解其原理,因為太長篇幅有限,感興趣的可以專門學習樹結構的處理。讀者隻需要知道其原理,什麼時候用雙數組遍歷,什麼時候用ACDAT遍歷就行。而HanLP封裝的ACDAT的實現類是AhoCorasickDoubleArrayTrieSegment。
下面,我們來實現AhoCorasickDoubleArrayTrieSegment,代碼如下:
if __name__ == "__main__":
HanLP.Config.ShowTermNature = False
segment = JClass("com.hankcs.hanlp.seg.Other.AhoCorasickDoubleArrayTrieSegment")()
print(segment.seg("在來到這個世界之前,一起都很井然有序"))
運行之後,效果如下:

需要註意的是,python的HanLP雖然提供瞭AhoCorasickDoubleArrayTrieSegment類,但是讀者可以試試,替換後運行會報錯,控制臺會提示該類沒有seg函數。而HanLP庫又是基於Java開發的,所以在實際的項目中,盡量使用JClass加載Java類進行實戰,因為python的HanLP庫運行速度比Java慢一倍,但python的好處是相對簡單,可以調用其他程序的類,所以速度這方面隻要python引用Java類進行調用,其實速度一樣。
到此這篇關於python自然語言處理之字典樹知識總結的文章就介紹到這瞭,更多相關python字典樹內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!