Pandas索引排序 df.sort_index()的實現
df.sort_index()實現按索引排序,默認以從小到大的升序方式排列,如希望按降序排列,傳入ascending = False
import pandas as pd
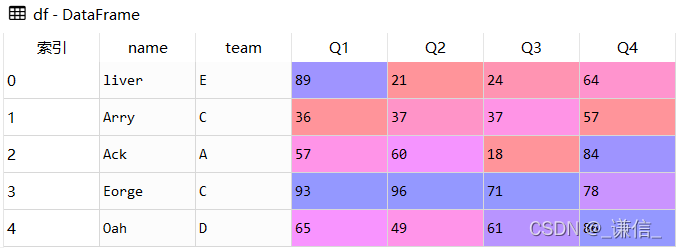
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 索引降序
res1 = df.sort_index(ascending=False)
# 按列索引名排序:
# 在索引方向上排序
res2 = df.sort_index(axis=1, ascending=False)
結果展示
df
res1

res2

擴展
# 更多方法如下: s.sort_index() # 升序排列 df.sort_index() # df也是按索引進行排序 df.team.sort_index() s.sort_index(ascending=False) # 降序排列 s.sort_index(inplace=True) # 排序後生效,改變原數據 # 索引重新0-(n-1)排,可以得到它的排序號 s.sort_index(ignore_index=True) s.sort_index(na_position='first') # 空值在前,另'last'表示空值在後 s.sort_index(level=1) # 如果多層,排一級 s.sort_index(level=1, sort_remaining=False) # 這層不排 # 行索引排序,表頭排序 df.sort_index(axis=1) # 會把列按列名順序排序
df.reindex()指定自己定義順序的索引,實現行和列的順序重新定義
import pandas as pd
df = pd.DataFrame({
'A':[1,2,3],
'B':[4,5,6]
},index=['a','b','c'])
# 按要求重新指定索引順序
res1 = df.reindex(['c','b','a'])
# 指定列順序
res2 = df.reindex(['B','A'], axis=1)
結果展示
df

res1

res2

到此這篇關於Pandas索引排序 df.sort_index()的實現的文章就介紹到這瞭,更多相關Pandas索引排序 df.sort_index()內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Pandas數值排序 sort_values()的使用
- Pandas中DataFrame的基本操作之重新索引講解
- Pandas reindex重置索引的使用
- pandas刪除部分數據後重新生成索引的實現
- Pandas數據分析-pandas數據框的多層索引