讓chatgpt將html中的圖片轉為base64方法示例
前言
故事要從我們公司的新官網說起,新官網是叫外包做的,前後端沒有分離,對,你沒聽錯,都到瞭 2023 年的今天,新項目依然是前後端混在一起,堆成一座屎山,然後通過模板渲染展示網頁。
當然,對於非研發的,技術棧咋樣都不重要,又不是不能用~
各位看官,聽到上面的情況,是不是隱隱約約感覺到會有啥驚喜(驚嚇)
哈,你來翻譯翻譯,什麼叫驚喜?好,那我來翻譯翻譯,驚喜(bushi)就是自從新官網上線後,PV(頁面訪問量)下降瞭 50%。是的,你沒看錯,原因就是打開官網巨卡,一般需要 7~8s。

就單單請求個 html,就需要耗費 7s+的時間。
運營那邊被老板親切問候後,就跑過來找我們研發幫忙看問題,把情況說的特嚴重,唉,最終還不是得我們幫忙處理爛攤子
那沒辦法,我們就開始分析一通,啪的一下,很快呀,就找到瞭加載賊慢的原因:
- 剛才所說的服務端響應慢,那這個交給後端去搞就好(這個是重中之重)
- 官網的圖片請求是在是太多瞭,而我們知道 http 請求是有次數限制的(http1.1),太多的話其他隻能處於阻塞狀態
那第二點自然是需要前端去搞瞭,圖片太多,導致 http 請求太多,那好辦,把小圖片轉 base64 不就好。 嗯,思路很簡單,如果是前後端分離的項目,我們一般無腦配置 webpack url-loader 的體積限制就好,或者配置 webpack5 的 asset,即在導出一個 data URI 和發送一個單獨的文件之間自動選擇:
rules: [
{
test: /\.(png|jpe?g|svg|gif)$/,
//webpack4 start
use: [
{
loader: 'url-loader',
options: { limit: 10 * 1024 },
},
],
//webpack4 end
// webapack5 start
type:'asset/inline',
parser: {
dataUrlCondition: {
maxSize: 10 * 1024, // 小於10k則轉為base64
},
},
// webapack5 end
},
],
很簡單對吧,但當你想快速 cv 以上配置的時候,發現,前端代碼都是混在後端代碼裡面,一堆 html 文件,html 裡面又混雜著一堆的 Thymeleaf 語法(Thymeleaf 是一個跟 Velocity、FreeMarker 類似的模板引擎,它可以完全替代 JSP,JSP??都啥年代瞭)

越看越不對勁,正所謂理想很豐滿,現實很骨感,唉,隻能長嘆一聲。
但沒辦法,領導可不管用啥方式,隻要有個方法把 html 裡面圖片小於某個指定值,如 10k,那就轉 base64,讓這些小圖片不走 http 請求。
思路
那麼,正常的路走不通(當然也有可能有其他更快捷的方式,隻是比較趕,暫時想不到更好、更簡單的方式實現),那就另辟蹊徑。
全體流程如下:
1. mvn clean // marven 清空輸出目錄
2. mvn compile // marven編譯
3. 將所有 html 的的小圖片都轉 base64
4. mvn package // marven 打包
以上主要重點關註第3點,既然要將所有 html 的的小圖片都轉 base64,那麼自然而然可以通過寫個 node 腳本來實現,大概可以分為以下幾個步驟:
- 遞歸讀取指定目錄下的所有 html 文件路徑 htmlPaths,這裡我們假設所有 html 都放在 backend/templates 裡面
- 遍歷每個路徑,讀取對應的 html,然後通過正則匹配到每個 html 裡面的所有 img 對應的 src,存放到 imgSrcs 裡面
- 遍歷每個 img 的 src,讀取 imageBuffer,並轉為 base64
- 再將得到的 base64 替換原先的 src
- 最後將新的 html 替換舊的 html
上面的步驟應該比較清晰的,不過,等一下,最近 chatgpt 不是很火嗎,讓它來寫不就好~
實現過程
遞歸讀取指定目錄下的所有 html 文件路徑 htmlPaths
首先判斷入口目錄的下的內容,是文件的話就判斷是否以.html 結尾,是的話則放入 htmlFilePaths,是目錄的話則遞歸遍歷,那我們來問神奇的 chatgpt:

嗯,很不錯,第一次幾乎完美,順利拿到所有的 html 路徑
獲取每個 html 裡面的圖片 src
自然而然想到用正則匹配來做,所以我馬上問:
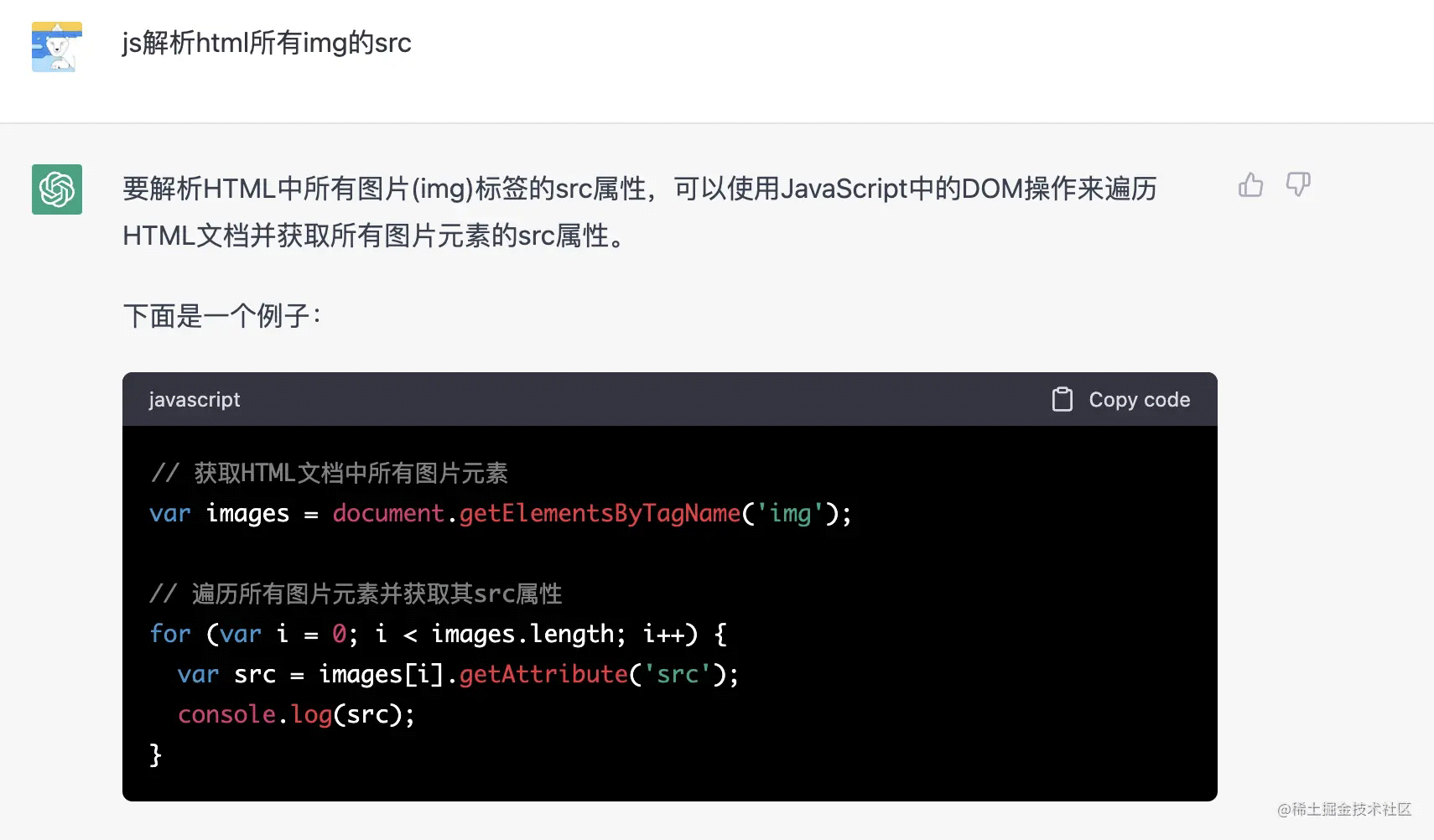
一看結果就不是我想要的,當然也是我描述的不清晰,導致 chatgpt 以為要獲取 html 文檔的圖片 src
獲取 html 字符串的所有圖片 src
應該問要獲取 html 字符串的,所以我接著問:
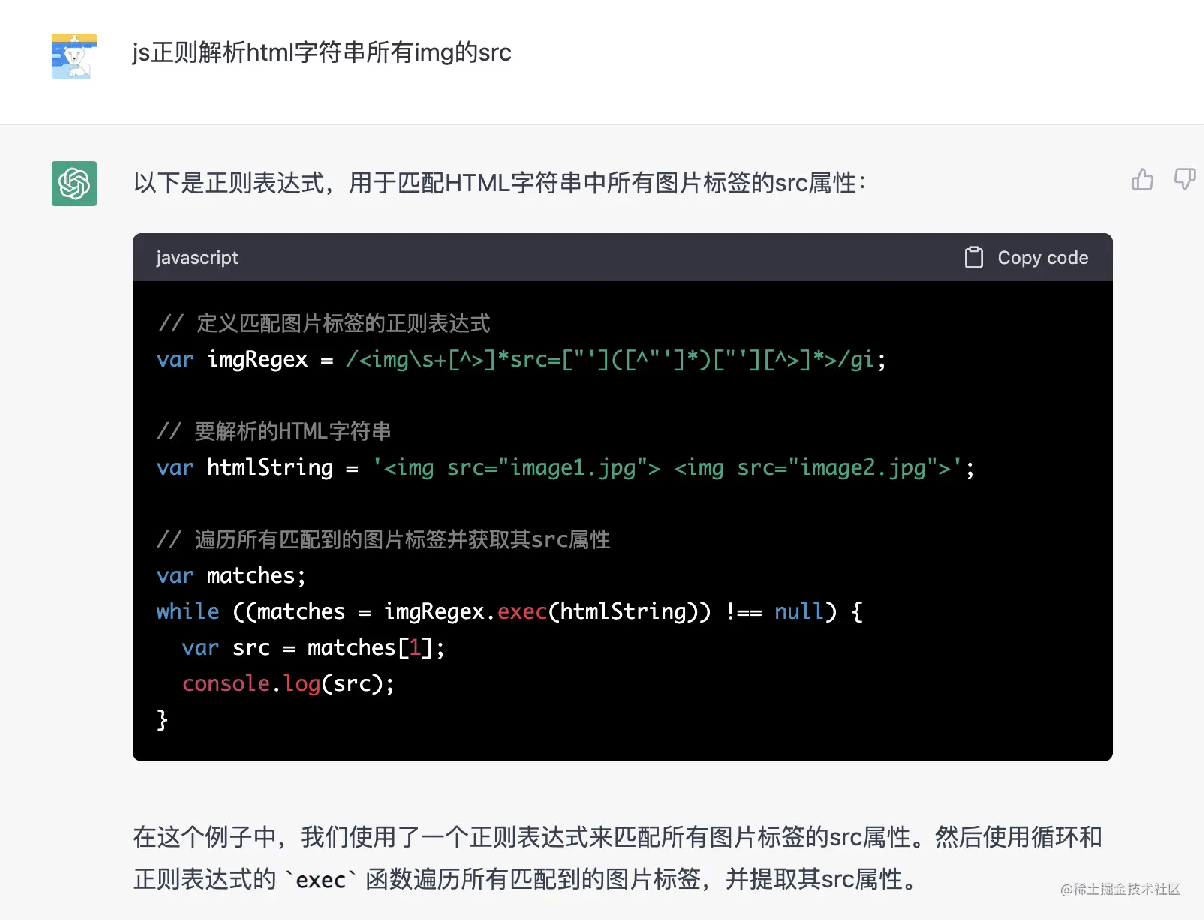
// 定義匹配圖片標簽的正則表達式
var imgRegex = /<img\s+[^>]*src=["']([^"']*)["'][^>]*>/gi;
// 要解析的HTML字符串
var htmlString = '<img src="image1.jpg"> <img src="image2.jpg">';
// 遍歷所有匹配到的圖片標簽並獲取其src屬性
var matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
var src = matches[1];
console.log(src);
}
運行後,得到的結果:

不錯不錯,再接再厲。
忽略註釋的代碼
但 html 代碼可能 img 被註釋瞭,如 <!-- <img src='xxx.jpg'> -->,那麼我們實際上沒必要去轉換,故我們讓個讓其忽略註釋的:

那我們來試試,將其中註釋代碼中插入 img,看看是否會解析:
// 定義匹配圖片標簽的正則表達式
var imgRegex = /<img\s+[^>]*src=["']([^"']*)["'][^>]*>/gi;
// 定義匹配註釋的正則表達式
var commentRegex = /<!--[\s\S]*?-->/g;
// 要解析的HTML字符串
var htmlString = '<!-- <img src="image3.jpg"> --> <img src="image1.jpg"> <img src="image2.jpg">';
// 刪除所有註釋
htmlString = htmlString.replace(commentRegex, '');
// 遍歷所有匹配到的圖片標簽並獲取其src屬性
var matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
var src = matches[1];
console.log(src);
}

可以看到被註釋掉的 image3 不會被匹配到
本身是 base64,則忽略
繼續繼續,但圖片 src 可能一開始就是 base64 瞭,就沒必要轉瞭,而 base64 是 data:image 開頭的,所以我們再讓它加下條件:

// 定義匹配圖片標簽的正則表達式
var imgRegex = /<img\s+[^>]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi;
// 要解析的HTML字符串
var htmlString = '<img src="image1.jpg"> <img src="data:image/png;base64,iVBORw0KG..."> <img src="image2.jpg"><!-- <img src="image3.jpg"> -->';
// 遍歷所有匹配到的不以 data:image 開頭的圖片標簽並獲取其src屬性
var matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
var src = matches[1];
console.log(src);
}
我們運行看下結果

成功跳過瞭 base64 的,但是,好像沒有瞭忽略註釋代碼的條件,啊這。。
所以我就讓他忽略註釋和 base64 的,但好像一直丟三落四,按下葫蘆浮起瓢,大傢可以看看

上面的註釋的被匹配到瞭


註釋又又又被匹配到瞭,算瞭,我直接問如果忽略 base64,然後再組合忽略註釋的就好,組合後的代碼如下:
const imgRegex = /<img\s+[^>]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi;
// 定義匹配註釋的正則表達式
const commentRegex = /<!--[\s\S]*?-->/g
// 刪除所有註釋
var htmlString = '<img src="image1.jpg"> <img src="data:image/png;base64,iVBORw0KG..."> <img src="image2.jpg"><!-- <img src="image3.jpg"> -->';
htmlString = htmlString.replace(commentRegex, '')
// 遍歷所有匹配到的圖片標簽並獲取其src屬性
const imgSrcs = []
let matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
const src = matches[1];
imgSrcs.push(src)
}
console.log(imgSrcs)

忽略 Thymeleaf 語法
還有個問題,img 的 src 可能是通過服務端渲染導入的,那麼我們要忽略掉,大致語法為 <img th:src="${t.imgUrl1}" />,也就是以 th:開頭的

// 定義匹配圖片標簽的正則表達式
var imgRegex = /<img\s+[^>]*src=["']((?!data:image|@{)(?!\s*th:src)[^"']*)["'][^>]*>/gi;
// 要解析的HTML字符串
var htmlString = '<img src="image1.jpg"> <img src="@{some/url}"> <img src="data:image/png;base64,iVBORw0KG..."> <img src="image2.jpg" th:src="@{some/other/url}">';
// 遍歷所有匹配到的不以 data:image、@{ 和包含 th:src 的圖片標簽並獲取其src屬性
var matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
var src = matches[1];
console.log(src);
}

上面的@{可以忽略,實際上也是屬於 Thymeleaf 語法,屏蔽 th:src 即可
結合起來,封裝成一個函數
function getImgSrcInHtml(htmlString) {
/** 定義匹配圖片標簽的正則表達式
* 1.src中不以data:image開頭,即不以base64開頭,沒必要再轉化瞭
* 2.不是th:src
* 3.忽略註釋的代碼
* */
const imgRegex = /<img\s+[^>th:]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi;
// 定義匹配註釋的正則表達式
const commentRegex = /<!--[\s\S]*?-->/g
// 刪除所有註釋
htmlString = htmlString.replace(commentRegex, '')
// 遍歷所有匹配到的圖片標簽並獲取其src屬性
const imgSrcs = []
let matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
const src = matches[1];
imgSrcs.push(src)
}
return imgSrcs.filter(Boolean)
}
運行下,看下結果:

src 轉 base64
自此,我們拿到所有 html 裡面的 src 瞭,那麼判斷下是否小於指定 size,是的話轉 base64
獲取文件大小可通過 fs 的 statSync 來拿到對應文件的 size,如下
/** 獲取文件大小 */
function getFileSize(filePath) {
const stat = fs.statSync(filePath)
return stat.size
}
如果滿足條件則將圖片轉 base64,而圖片本身是 Buffer,所以要轉一下:
/** 圖片轉成base64 */
function imageToBase64(filePath) {
// 讀取圖片文件
const imageBuffer = fs.readFileSync(filePath)
const extname = getExtname(filePath)
// 將圖片文件轉換為 base64 編碼字符串
const base64String = Buffer.from(imageBuffer).toString('base64')
return `data:image/${extname.slice(1)};base64,${base64String}`
}
通過加上前綴data:image/${extname.slice(1)};base64,,其中 extname 是文件後綴名,通過path.extname拿到:
/** 獲取後綴名 */
function getExtname(filePath) {
return path.extname(filePath)
}
每得到一個 base64,則替換原先的 src:
htmlString = htmlString.replace(src, imgBase64)
最後將新的 html 替換舊的 html
html 下滿足條件的 src 全部替換好後,就可以將新的 html 替換老的瞭,實際上也就是重寫回去:
writeFile(htmlPath, htmlString)
性能優化
但我們發現整個過程中有兩處可以優化代碼:
- 如果 src 大於指定尺寸,那麼下次遇到直接跳過,不再獲取尺寸大小
- 一個圖片可能被多處引用到,那麼轉 base64 後,下次遇到就沒必要再轉瞭,直接復用即可
針對第一點,我們可以通過聲明一個 Set,存放大於指定尺寸的 src:
for (const src of imgSrcs) {
/** 之前已經大於瞭,這次遇到就直接跳過即可 */
if (imgOverSizeSet.has(src)) continue
let absoluteSrc = src
// 如果不是相對路徑,那麼轉換為絕對路徑
if (!src.startsWith('.')) absoluteSrc = path.join(STATIC_PATH, src)
// 不存在或者超出限制,則不替換
if (getFileSize(absoluteSrc) >= FILE_LIMIE_SIZE) {
imgNotExistOrOverSizeSet.add(src)
continue
}
}
針對第二點,我們可以通過聲明一個 Map,key 為 src,value 為 base64:
/** 存imgSrc -> 圖片base64 */ const imgSrc2Base64Map = new Map()
每次判斷到對應的 src 有值,則直接拿之前的 base64,不再轉化:
let imgBase64 = imgSrc2Base64Map.get(src)
if (!imgBase64) {
imgBase64 = imageToBase64(absoluteSrc)
imgSrc2Base64Map.set(src, imgBase64)
}
總的代碼
const fs = require('fs')
const path = require('path')
function resolve(relativePath) {
return path.resolve(__dirname, relativePath)
}
/** 靜態資源路徑 */
const STATIC_PATH = resolve('xxx')
/** html模板路徑 */
const TEMPLATE_PATH = resolve('yyy')
/** 文件大小限制 10K */
const FILE_LIMIE_SIZE = 1024 * 10
/** 圖片轉成base64 */
function imageToBase64(filePath) {
// 讀取圖片文件
const imageBuffer = fs.readFileSync(filePath)
const extname = getExtname(filePath)
// 將圖片文件轉換為 base64 編碼字符串
const base64String = Buffer.from(imageBuffer).toString('base64')
return `data:image/${extname.slice(1)};base64,${base64String}`
}
/** 獲取文件大小 */
function getFileSize(filePath) {
const stat = fs.statSync(filePath)
return stat.size
}
/** 獲取後綴名 */
function getExtname(filePath) {
return path.extname(filePath)
}
/** 獲取所有html路徑 */
function getHtmlPaths(dir, filePaths = []) {
const files = fs.readdirSync(dir);
for (const file of files) {
const filePath = path.join(dir, file);
const fileStat = fs.statSync(filePath);
if (fileStat.isDirectory()) {
getHtmlPaths(filePath, filePaths);
} else if (fileStat.isFile() && getExtname(filePath) === '.html') {
filePaths.push(filePath);
}
}
return filePaths;
}
function readFile(filePath) {
return fs.readFileSync(filePath, 'utf-8')
}
function writeFile(filePath, source) {
return fs.writeFileSync(filePath, source)
}
/** 獲取html中滿足規則的img src */
function getImgSrcInHtml(htmlString) {
/** 定義匹配圖片標簽的正則表達式
* 1.src中不以data:image開頭,即不以base64開頭,沒必要再轉化瞭
* 2.不是th:src
* 3.忽略註釋的代碼
* */
const imgRegex = /<img\s+[^>th:]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi;
// 定義匹配註釋的正則表達式
const commentRegex = /<!--[\s\S]*?-->/g
// 刪除所有註釋
htmlString = htmlString.replace(commentRegex, '')
// 遍歷所有匹配到的圖片標簽並獲取其src屬性
const imgSrcs = []
let matches;
while ((matches = imgRegex.exec(htmlString)) !== null) {
const src = matches[1];
imgSrcs.push(src)
}
return imgSrcs.filter(Boolean)
}
/** 主程序 */
function main() {
const htmlPaths = getHtmlPaths(TEMPLATE_PATH)
/** 存imgSrc -> 圖片base64 */
const imgSrc2Base64Map = new Map()
/** 存不存在,或者超過指定大小的img */
const imgNotExistOrOverSizeSet = new Set()
htmlPaths.forEach(htmlPath => {
let htmlString = readFile(htmlPath)
const imgSrcs = getImgSrcInHtml(htmlString)
if (!imgSrcs.length) return
for (const src of imgSrcs) {
if (imgNotExistOrOverSizeSet.has(src)) continue
let absoluteSrc = src
// console.log(imgSrcs)
// 如果不是相對路徑,那麼轉換為絕對路徑
if (!src.startsWith('.')) absoluteSrc = path.join(STATIC_PATH, src)
const isExist = fs.existsSync(absoluteSrc)
if (!isExist) console.log('not isExist', src)
// 不存在或者超出限制,則不替換
if (!isExist || getFileSize(absoluteSrc) >= FILE_LIMIE_SIZE) {
imgNotExistOrOverSizeSet.add(src)
continue
}
let imgBase64 = imgSrc2Base64Map.get(src)
if (!imgBase64) {
imgBase64 = imageToBase64(absoluteSrc)
imgSrc2Base64Map.set(src, imgBase64)
}
htmlString = htmlString.replace(src, imgBase64)
}
// 替換好後,寫回
writeFile(htmlPath, htmlString)
})
}
main()
總結
因為太多的小圖片導致 http 請求阻塞,所以要把滿足條件的小圖片轉為 base64, 而前端的 html 混在在後端代碼裡面,且裡面混雜著 Thymeleaf 模板語法,想通過 webpack 打包的方式看起來好像不行(至少目前不知道咋辦),所以退而求其之自己寫個腳本來處理。
大致思路就是:
- 讀取所有 html,匹配到裡面的所有 img 的 src
- 匹配的過程中我們要忽略註釋的代碼、已經是 base64 的圖片、Thymeleaf 模板語法的,涉及到挺多的正則語法,這部分我通過調戲 chatgpt 來實現,雖然過程中不是十分完美
- src 可能被重復用到,所以這裡又可以優化為:
- 如果 src 大於指定尺寸,那麼下次遇到直接跳過,不再獲取尺寸大小
- 一個圖片可能被多處引用到,那麼轉 base64 後,下次遇到就沒必要再轉瞭,直接復用即可
以上就是讓chatgpt將html中的圖片轉為base64方法示例的詳細內容,更多關於chatgpt html圖片轉base64的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- vue後臺返回base64圖片無法顯示的解決
- Node.js開發靜態資源服務器
- vue實現調取手機攝像頭和相冊功能
- 將InputStream轉化為base64的實例
- node.js-path模塊你瞭解多少