關於python基礎數據類型bytes進制轉換
1. bytes字節串類型介紹:
定義一個字節串:
字面量:b=b"he1lo 你好" [默認編碼格式ASCII]
類型: b=bytes("字節內容",encoding= "utf-8") [默認編碼格式ASCII]
Python 3新增瞭bytes 類型,用於代表字節串,是一一個類型。
由於bytes保存的就是原始的字節(二進制格式)數據,因此bytes對象可用於在網絡上傳輸數據,也可用於存儲各種二進制格式的文件,比如圖片、音樂等文件。
2. 二進制、十進制、十六進制之間的轉換:
二進制:
010101, 是電腦識別的一種格式數據
python解析器,幫助我們把我們輸入的python語言解析成二進制的數據,供計算機所識別。
例如:如果我們定義的是十進制,十六進制,等語言,需要先轉成二進制後,計算機在進行執行。進行數據傳遞的過程中如果使用二進制進行數據傳遞的話執行速度會很快
2.1 二進制轉十進制:
把二進制數按權展開、相加即得十進制數


2.2 二進制轉十六進制:
十六進制是取四合一。 (註意:四位二進制轉成十六進制是從右到左開始轉換,不足時補零)

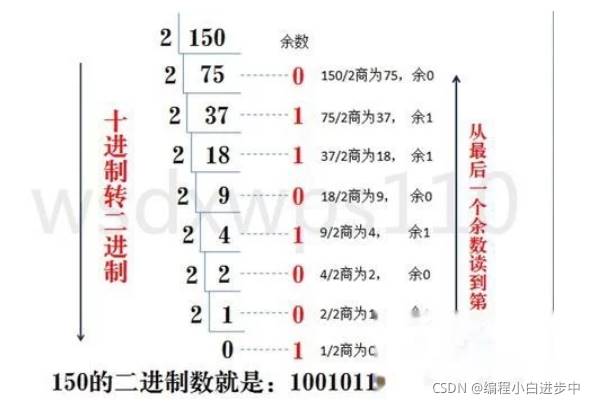
2.3 十進制轉二進制:
十進制數除二取餘法,即十進制數除二,餘數為權位上的數,得到的商值繼續除以二,依次步驟繼續向下運算直到商為零為止
2.4 十進制轉十六進制:
間接法:把十進制轉成二進制,然後再由二進制轉成十六進制
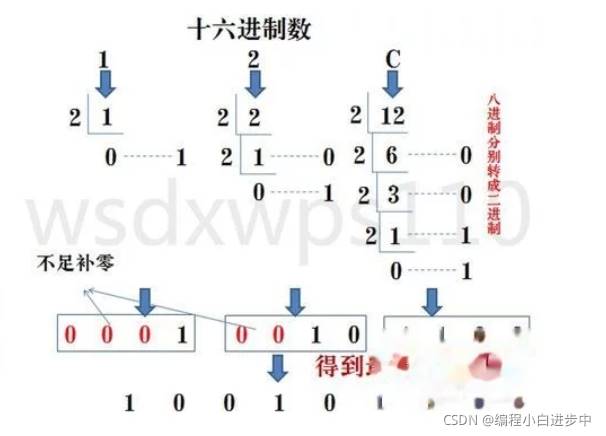
2.5 十六進制轉二進制:
十六進制數通過除2取餘法,得到二進制數,對每一個十六進制為四個二進制,不足時在最左邊補零
2.6 十六進制轉十進制:
把十六進制數按權展開,相加即得十進制數

3. 字節串和字符串之間的區別:
bytes和str 除操作的數據單元不同之外,它們支持的所有方法都基本相同,bytes也是不可變序列。
字符串(str) 由多個字符組成,以字符為單位進行操作;
字節串(bytes) 由多個字節組成,以字節為單位進行操作。
4. 字節介紹:
計算機底層有兩個基本概念:位(bit) 和字節(Byte) ,其中 bit代表1位,要麼是0,要麼是1; Byte代表1字節,1字節包含8位二進制。 定義一個字節串:“123” 裡面有三個字節, 每一個字節由8位二進制構成。兩個十六進制組成 每4位二進制可以用一個十六進制數表示。(一個字節需要兩個十六進制的數)每四位相當於4位二進制數。
b’\xe6\x88\x91 \xe7\x88 \xb1Python\xe7\xbc \x96\xe7\xa8\x8b’,
比如: \xe6 就表示1字節,其中\x表示十六進制,e6就是兩位的十六進制數。
5. 字節串和字符串之間的轉換:
5.1 如果字符串內容都是 ASCII 字符,則可以通過直接在字符串之前添加b來構建字節串值。
b=b"he1lo"
print (b)
# 輸出: b"he1lo"
5.2 調用 bytes()函數(其實是bytes的構造方法)將字符串按指定字符集轉換成字節串,
b=bytes("字節內容v,encoding= "utf-8") [默認編碼格式ASCII]
b=bytes("he111o字節內容",encoding="utf-8" )
print (b)
# 輸出: b' he11lo\xe5\xad\x97\xe8\x8a^ \x82\xe5 \x86\x85\xe5\xae \xb9'
5.3 調用字符串本身的encode()方法將字符串按指定字符集轉換成字節串(常用) 如果不指定字符集,默認使用UTF-8 字符集。
str="nihao你好"
b=str. encode("utf-8")
print (b)
#輸出: b' nihao\xe4\xbd\xa0\xe5\xa5\xbd'|
6. 將一個bytes對象轉換成字符串(decode(“編碼類型” ) ):
str="nihao你好"
b=str. encode("utf-8")
str1=b. decode("utf-8" )
print (str1)
# 輸出:nihao你好
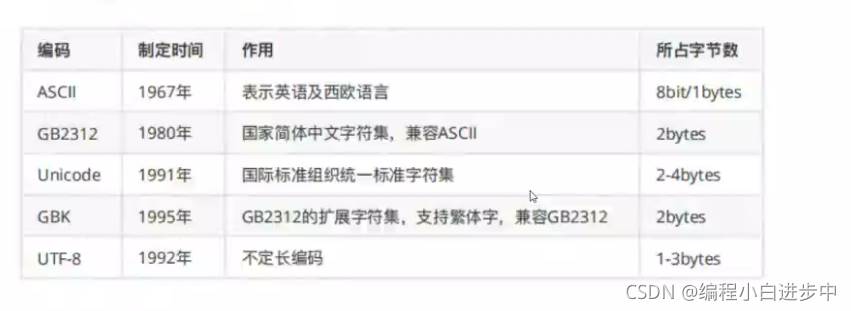
7. 編 碼:
Unicode字符集,包括漢字,為兩個字節(6位,支持6536個字符編號)。實際使用的UTF-8, UTF-16 GeBK GB2312等其實都屬於Unicode字符集。
ASCII碼:是用一個字節(8bit 0-255) 中的127個字母表示大小寫字母,數字和一些鍵盤 上有的符號。其餘的例如漢字等不能被表示。
為瞭統各國的編碼,減少亂碼, 誕生瞭Unicode, 把所有編碼統-到- 套編碼中。
為瞭節約位置以及效率低下等問題。出現瞭把Unicde編碼轉化為“可變長編碼”的UTF- 8編碼。
UTF-8編碼(針對中文) .把-一個Cide字符根據不同的數字大小編碼成4-6個字節,常用的英文祖母被編碼成瞭1個字節,漢字是3個字節,隻有特別偏僻的字才會被編碼成4-6個字節.
如果需要傳輸的文本包含大量的英文字符,UTF-8就能節省空間。(ASCII碼可以看成是UTF-8的一 部分, 所以大量隻支持ASCII編碼的歷史遺留軟件可以在UTF-8編碼下繼續工作)
GBK:隻識別中文
8. 開發過程中遇見亂碼問題:
- 你自己創建的文件書寫瞭一些文字保存之後發現亂碼考慮編碼的問題編碼改為utf-8
- 數據傳遞的時候
python端開發的時候C語言項目c—-python端傳遞數據接收到的數據中文亂碼瞭
需要判斷
C語言那邊數據是不是用utf-8編碼和你接收數據的時候是不是也是通過utf-8
到此這篇關於關於python基礎數據類型bytes進制轉換的文章就介紹到這瞭,更多相關python bytes數據類型進制轉換內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python字符串編碼轉換 encode()和decode()方法詳細說明
- Python之string編碼問題
- python 中文編碼亂碼問題的解決
- Python有關Unicode UTF-8 GBK編碼問題詳解
- Python編碼規范擺脫Python編碼噩夢