解讀MySQL的客戶端和服務端協議
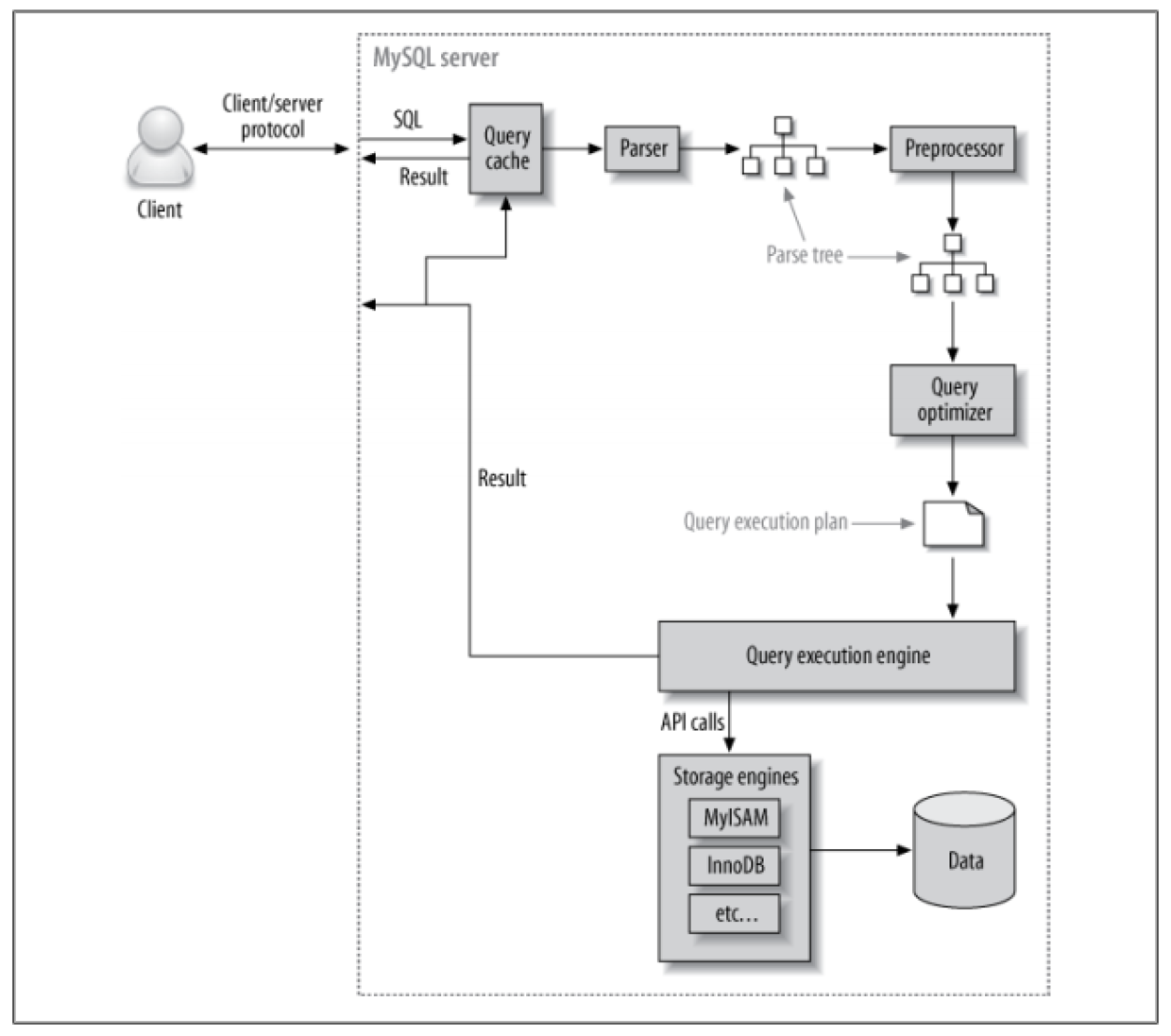
如果需要從 MySQL 服務端獲得很高的性能,最佳的方式就是花時間研究 MySQL 優化和執行查詢的機制。一旦理解瞭這些,大部分的查詢優化是有據可循的,從而使得整個查詢優化的過程更有邏輯性。下圖展示瞭 MySQL 執行查詢的過程:
- 客戶端將 SQL 語句發送到服務端。
- 服務端檢查查詢緩存。如果緩存中已有數據,則直接返回緩存結果;否則,將 SQL 語句傳遞給下一環節。
- 服務端解析、預處理和優化 SQL 語句後,傳遞到查詢優化器中形成查詢計劃。
- 查詢執行引擎通過調用存儲引擎接口執行查詢計劃。
- 服務端將查詢結果返回給客戶端。
上述的幾個步驟都有其復雜性,接下來幾篇文章將詳細講述各個環節。查詢優化過程尤其復雜,並且理解這一環節很重要。
MySQL 客戶端/服務端協議
雖然並不需要瞭解 MySQL 客戶端/服務端協議的內部細節,但需要從高應用層面理解其是如何工作的。這個協議是半雙工的,這意味著 MySQL 服務端不同同時發送和接收消息,以及不可以將消息拆成多條短消息發送。這種機制一方面使得 MySQL 的通信簡單快速,另一方面也增加瞭一些限制。例如,這意味著無法進行流控,一旦一方發送瞭消息,另一方在響應前必須接收整個消息。這就好像來回打乒乓球一樣,同一時間隻有一方有球,隻有接到瞭球才能把它打回去。
客戶端通過單個數據包將查詢語句發送給服務端,因此在存在大的查詢語句時配置 max_allowed_packet 很重要。一旦客戶端發送查詢語句後,它就隻能等待返回結果。
相反,服務端的響應通常是由多個數據包組成的。一旦服務端響應後,客戶端必須獲取整個結果集。客戶端沒法簡單地獲取幾行然後告訴服務端不要再發送剩餘的數據。如果客戶端僅僅需要返回數據前面的幾行,隻能是等待服務端全部數據返回後再從中丟棄不需要的數據,或者是粗暴地斷開連接。不管哪種方式都不是好的選擇,因此合適的 LIMIT子句就顯得十分重要。
大部分的 MySQL連接庫支持獲取整個結果集並在內存中緩存起來,或者是獲取需要的數據行。默認的行為通常是獲取整個結果集然後在內存緩存。知道這一點很重要,因為 MySQL 服務端在所有請求的數據行沒返回前,不會釋放這次查詢的鎖和資源。大部分客戶端庫會讓你感覺數據是從服務端獲取的,實際上這些數據可能僅僅是從緩存中讀取的。這在大部分時間是沒問題的,但對於耗時很久或占據很多內存的大數據量查詢來說就不合適瞭。如果指定瞭不緩存查詢結果,那麼占用的內存會更小,並且可以更快地處理結果。缺點是這種方式會在查詢時引起 服務端的鎖和資源占用。
以 PHP 為例,以下是PHP常用的查詢代碼:
<?php
$link = mysql_connect('localhost', 'user', 'password');
$result = mysql_query('SELECT * FROM huge_table', $link);
while ($row = mysql_fetch_array($result)) {
//處理數據結果
}
?>
這個代碼看起來好像是隻獲取瞭需要的數據行。然而,這個查詢通過 mysql_query 的調用後實際上將全部結果放到瞭內存中。而 while 循環實際上是對內存中的數據進行循環迭代。相反,如果使用 mysql_unbuffered_query 替代 mysql_query 的話,那就不會緩存結果。
<?php
$link = mysql_connect('localhost', 'user', 'password');
$result = mysql_unbuffered_query('SELECT * FROM huge_table', $link);
while ($row = mysql_fetch_array($result)) {
//處理數據結果
}
?>
不同的編程語言處理緩存覆蓋的方式不同。例如,Perl 的 DBD::mysql 驅動需要通過 mysql_use_result 屬性指定 C 語音客戶端庫(默認是 mysql_buffer_result),示例如下:
#!/usr/bin/perl
use DBI;
my $dbn = DBI->connect('DBI:mysql:;host=localhost', 'user', 'password');
my $sth = $dbn->prepare('SELECT * FROM huge_table', {mysql_use_result => 1});
$sth->execute();
while (my $row = $sth->fetchrow_array()) {
#處理數據結果
}
註意到 prepare 指定瞭使用結果而不是緩存結果。也可以通過在連接的時候指定,這會使得每次查詢都不緩存。
my $dbn = DBI->connect('DBI:mysql:;mysql_use_result=1;host=localhost', 'user', 'password');
以上就是解讀MySQL的客戶端和服務端協議的詳細內容,更多關於MySQL 客戶端和服務端協議的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- 一文詳解PHP連接MySQL數據庫的三種方式
- nodejs中關於mysql數據庫的操作
- 全面分析MySQL ERROR 1045出現的原因及解決
- MySQL與PHP的基礎與應用專題之表連接
- MySQL與PHP的基礎與應用專題之自連接