Pandas||過濾缺失數據||pd.dropna()函數的用法說明
看代碼吧~
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values.
pd.dropna()函數(官方文檔)用於過濾數據中的缺失數據.
缺失數據在pandas中用NaN標記.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 隨機產生5行3列的數據
df.ix[1, :-1] = np.nan # 將指定數據定義為缺失
df.ix[1:-1, 2] = np.nan
print(df)
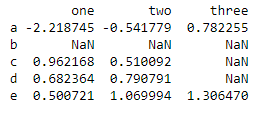
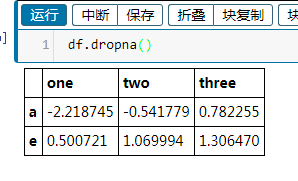
df.dropna() #刪除所有帶缺失數據的行
| parameters | 詳解 |
|---|---|
| axis | default 0指行,1為列 |
| how | {‘any’, ‘all’}, default ‘any’指帶缺失值的所有行;’all’指清除全是缺失值的行 |
| thresh | int,保留含有int個非空值的行 |
| subset | 對特定的列進行缺失值刪除處理 |
| inplace | 這個很常見,True表示就地更改 |
補充:Python-pandas的dropna()方法-丟棄含空值的行、列
0.摘要
dropna()方法,能夠找到DataFrame類型數據的空值(缺失值),將空值所在的行/列刪除後,將新的DataFrame作為返回值返回。
1.函數詳解
函數形式:dropna(axis=0, how=’any’, thresh=None, subset=None, inplace=False)
參數:
axis:軸。0或’index’,表示按行刪除;1或’columns’,表示按列刪除。
how:篩選方式。‘any’,表示該行/列隻要有一個以上的空值,就刪除該行/列;‘all’,表示該行/列全部都為空值,就刪除該行/列。
thresh:非空元素最低數量。int型,默認為None。如果該行/列中,非空元素數量小於這個值,就刪除該行/列。
subset:子集。列表,元素為行或者列的索引。如果axis=0或者‘index’,subset中元素為列的索引;如果axis=1或者‘column’,subset中元素為行的索引。由subset限制的子區域,是判斷是否刪除該行/列的條件判斷區域。
inplace:是否原地替換。佈爾值,默認為False。如果為True,則在原DataFrame上進行操作,返回值為None。
2.示例
創建DataFrame數據:
import numpy as np
import pandas as pd
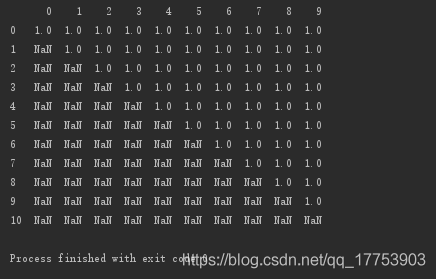
a = np.ones((11,10))
for i in range(len(a)):
a[i,:i] = np.nan
d = pd.DataFrame(data=a)
print(d)
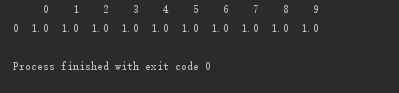
按行刪除:存在空值,即刪除該行
# 按行刪除:存在空值,即刪除該行 print(d.dropna(axis=0, how='any'))
按行刪除:所有數據都為空值,即刪除該行
# 按行刪除:所有數據都為空值,即刪除該行 print(d.dropna(axis=0, how='all'))

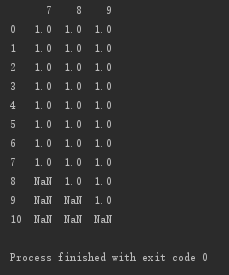
按列刪除:該列非空元素小於5個的,即刪除該列
# 按列刪除:該列非空元素小於5個的,即刪除該列 print(d.dropna(axis='columns', thresh=5))
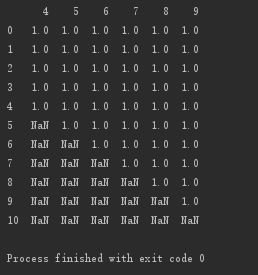
設置子集:刪除第0、5、6、7列都為空的行
# 設置子集:刪除第0、5、6、7列都為空的行 print(d.dropna(axis='index', how='all', subset=[0,5,6,7]))
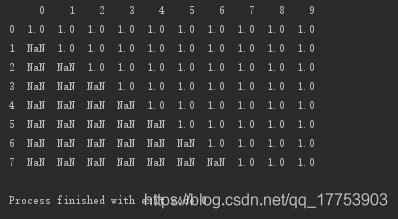
設置子集:刪除第5、6、7行存在空值的列
# 設置子集:刪除第5、6、7行存在空值的列 print(d.dropna(axis=1, how='any', subset=[5,6,7]))
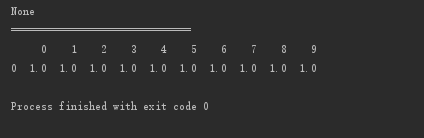
原地修改
# 原地修改
print(d.dropna(axis=0, how='any', inplace=True))
print("==============================")
print(d)
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。
推薦閱讀:
- Pandas缺失值刪除df.dropna()的使用
- Python pandas處理缺失值方法詳解(dropna、drop、fillna)
- Python數據分析之缺失值檢測與處理詳解
- pandas數據清洗(缺失值和重復值的處理)
- pandas中NaN缺失值的處理方法