詳解為什麼現代系統需要一個新的編程模型
為什麼現代系統需要一個新的編程模型?
Actor模型作為一種高性能網絡中的並行處理方式由Carl Hewitt幾十年前提出-高性能網絡環境在當時還不可用。如今,硬件和基礎設施的能力已經趕上並超越瞭Hewitt的願景。因此,高要求的分佈式系統的建造者遇到瞭不能完全由傳統的面向對象編程(OOP)模型解決的挑戰,但這可以從Actor模型中獲益。
今天,Actor模型不僅被認為是高效的解決方案——這已經被世界上要求最高的應用所檢驗。為瞭突出Actor模型解決的問題,這個主題討論以下傳統編程的假設與現代多線程、多CPU體系架構之間的不匹配:
- 封裝的挑戰
- 現代計算機體系結構中共享內存的錯覺
- 一個調用棧的錯覺
封裝的挑戰
OOP的一個核心支柱是封裝。封裝表明一個對象的內部狀態不能直接從外部訪問;它隻可以通過調用一組輔助的方法修改。對象負責暴露保護它所封裝數據的不變性的安全操作。例如,在一個有序二叉樹上的操作不允許違反樹的有序性。調用者希望保持有序性,當查詢樹上一條特定的數據時,它們需要能夠依賴這個約束。
當分析OOP運行時的行為時,我們有時候畫出一個消息序列圖展示方法調用的交互過程。例如:
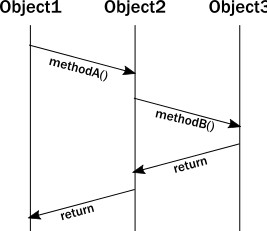
不幸的是,上面的圖表沒能精確表示執行過程中對象的生命線。實際上,一個線程執行所有的調用,所有對象的不變體約束出現在同一個方法被調用的線程中。更新線程執行圖,它看起來是這樣:
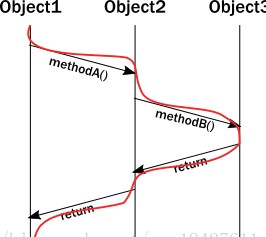
當試圖對多線程行為建模時,上面闡述的重要性變得明顯瞭。突然,我們畫出的簡潔的圖表變得不夠充分瞭。我們可以嘗試解釋多線程訪問同一對象:
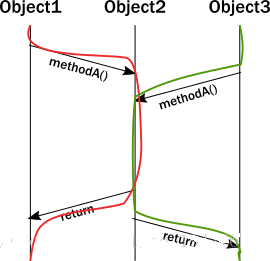
有一個執行部分,兩個線程調用同一個方法。不幸的是,對象的封裝模型不能保證執行這部分時會發生什麼。兩個線程之間沒有某種協調的話,兩個調用指令將以不能保證不變體性質的任意方式相互交錯。現在,想象一下這個由多個線程存在而變得復雜的問題。
解決這個問題的常見方法是給這些方法加一個鎖。盡管這保證瞭在給定的時間內最多一個線程將執行該方法,但是這是一個代價高昂的策略:
- 鎖嚴重限制瞭並發,鎖在現代CPU體系結構中的代價很高,要求操作系統承擔掛起線程並隨後恢復它的重負。
- 調用者線程被阻塞,因此它不能做其他有意義的工作。在桌面應用中這是不能接受的,我們希望使應用程序的用戶界面(UI)即使在一個很長的後臺作業正在運行的時候也是可響應的。在後臺,阻塞是完全浪費的。或許有人想到這可以通過開啟一個新線程彌補,但線程也是一個代價高昂的抽象。
- 鎖引入瞭一個新的威脅:死鎖
這些事實導致一個無法取勝的局面:
- 沒有足夠的鎖,狀態會被破壞
- 有足夠的鎖,性能受損並很容易導致死鎖
另外,鎖隻有在本地有用。當涉及跨機器協調時,唯一可選的是分佈式鎖。不幸的是,分佈式鎖比本地鎖低效幾個數量級,並且限制瞭伸縮性。分佈式鎖協議需要在網絡中跨機器的多輪通信,因此延遲飛漲。
在面向對象語言中,我們通常很少考慮線路或線性執行路徑。我們經常把系統想象成一個對象實例的網絡,這些實例對象響應方法調用、修改自身內部狀態、然後通過方法調用相互通信以驅動整個應用狀態向前:

然而,在一個多線程的分佈式環境中,實際發生的是線程沿著方法調用貫穿這個對象實例網絡。因此,線程是真正的運行驅動者:

【總結】
- 對象隻能在單線程訪問時保證封裝(不變體的保護),多線程執行幾乎總會導致破壞對象內部狀態。每個不變體可以被處於同一代碼段相互競爭的兩個線程違反。
- 雖然鎖似乎是對維護多線程時的封裝很自然的補救,實際上,在任何現實應用中鎖很低效並很容易導致死鎖。
- 鎖在本地有用,但試圖使鎖成為分佈式的,可以提供有限潛力的擴展。
現代計算機體系結構中共享內存的錯覺
80-90年代的編程模型定義:寫入一個變量意味著直接寫到內存位置 (這在一定程上混淆瞭局部變量可能僅存在於寄存器)。在現代體系架構中,如果我們簡化一下,CPUs會寫到cache行而不是直接寫入內存。大多數caches是CPU局部私有的,也就是,一個核寫入變量不會被其他核看到。為瞭使局部改變對其他核可見,因此對於另一個線程,cache行需要被傳送到其他核的cache。
在JVM中,我們必須通過使用volatile或Atomic顯式地指示線程間共享的內存位置。否則,我們隻能在鎖定的部分訪問這些內存。為什麼我們不將所有變量標記為volatile?因為跨核傳送cache行是一個代價非常高昂的操作!這樣做會隱式地停止涉及做額外工作的核,並導致緩存一致性協議的瓶頸。(CPUs用於主存和其他CPUs之間傳輸cache行的協議)。結果便是降低數量級的運行速度。
即使對於瞭解這個情況的開發者,搞清楚哪個內存位置應該被標記為volatile或者使用哪一種原子結構是一門黑暗的藝術。
【總結】
- 沒有真正的共享內存瞭,CPU核就像網絡中的計算機一樣,將數據塊(cache行)顯式地傳送給彼此。CPU之間的通信和網絡中計算機之間通信的相同之處比許多人意識到的要多。傳送消息是如今跨CPUs或網絡中計算機的標準。
- 相對於通過標記為共享或使用原子數據結構的變量來隱藏消息傳遞的層面,一個更規范和有原則的方法是保存狀態到一個並發實體本地並通過消息顯式地在並發實體間傳送數據或事件。
一個調用棧的錯覺
今天,我們常常將調用棧視為理所當然。但是,調用棧是在一個並發程序不那麼重要的時代發明的,因為多CPU系統那時不常見。調用棧沒有跨越線程,因而沒有對異步調用鏈建模。
當一個線程意圖委派一個任務給後臺的時候會出現問題。實際上,這意味著委托給另一個線程。這不是一個簡單的方法、函數調用,因為調用嚴格上屬於線程內部。通常,調用者(caller)線程將一個對象放入與一個工作線程(callee)共享的內存位置,反過來,這個工作線程(callee)在某個循環事件中獲取這個對象。這使得調用者(caller)線程可以向前運行和執行其他任務。
第一個問題是:調用者(caller)線程如何被通知任務完成瞭?但是當一個任務失敗且帶有異常的時候一個更嚴重問題出現瞭。異常應該傳播到哪裡?異常將被傳播到工作者(worker)線程的異常處理器而完全忽略誰是真正的調用者(caller):

這是一個嚴重的問題。工作者(worker)線程如何處理這種情況?它可能無法解決這個問題,因為它通常不知道失敗任務的目的。調用者(caller)線程需要以某種方式被通知,但是沒有調用棧去返回一個異常。失敗通知隻能通過邊信道完成,例如,將一個錯誤代碼放在調用者(caller)線程原本期待結果準備好的地方。如果這個通知不到位,調用者(caller)線程不會被通知任務失敗和丟失!這和網絡系統的工作方式驚人地相似-網絡系統中的消息和請求可以丟失或失敗而沒有任何通知。
在任務出錯和一個工作者(worker)線程遇到一個bug並不可恢復的時候,這個糟糕的情況會變得更糟。例如,一個由bug引起的內部異常向上傳遞到工作者(worker)線程的根部並使該線程關閉。這立即產生一個疑問,誰應該重啟由該線程持有的這一服務的正常操作,以及怎樣將它恢復到一個已知的良好狀態?乍一看,這似乎很容易,但是我們突然遇到一個新的、意外的現象:線程正在執行的實際任務已經不在任務被取走得共享內存位置瞭 (通常是一個隊列)。事實上,由於異常到達頂部,展開所有的調用棧,任務狀態完全丟失瞭!我們已經丟失瞭一條消息,盡管這是本地的通信,沒有涉及到網絡 (消息丟失是可期望的)。
【總結】
為瞭在當下系統實現有意義的並發和性能,線程必須以一種高效的、無阻塞的方式相互委派任務。有瞭這種任務委派並發方式(網絡/分佈式計算更是如此),基於棧調用的error處理失效瞭,新的、顯式的error信號機制需要被引入。失敗成為領域模型的一部分。任務委派的並發系統需要處理服務故障並且有原則性的方法恢復它們。這種服務的客戶端需要知道任務/消息會在重啟中丟失。即使不丟失,一個響應或許會由於隊列 (一個很長的隊列) 中先前的任務而發生任意的延遲,由垃圾回收造成的延遲等等。在這些情況下,並發系統應該以超時的形式對待響應截止時間,就像網絡/分佈式系統一樣。
以上就是詳解為什麼現代系統需要一個新的編程模型的詳細內容,更多關於現代系統需要一個新的編程模型的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- C語言中volatile關鍵字的作用與使用案例教程
- JAVA並發中VOLATILE關鍵字的神奇之處詳解
- Nodejs搭建多進程Web服務器實現過程
- 理解MySQL查詢優化處理過程
- 詳解nginx進程鎖的實現