Python深度學習之Pytorch初步使用
一、Tensor
Tensor(張量是一個統稱,其中包括很多類型):
0階張量:標量、常數、0-D Tensor;1階張量:向量、1-D Tensor;2階張量:矩陣、2-D Tensor;……
二、Pytorch如何創建張量
2.1 創建張量
import torch t = torch.Tensor([1, 2, 3]) print(t)

2.2 tensor與ndarray的關系
兩者之間可以相互轉化
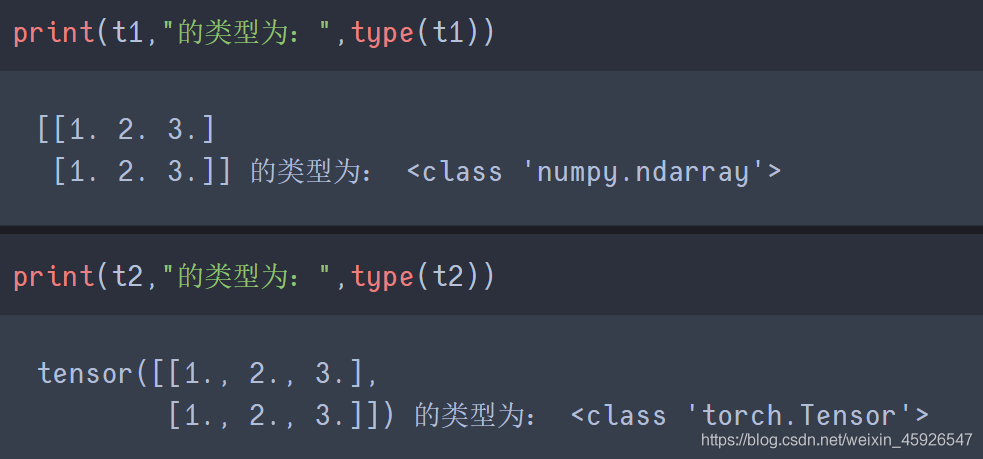
import torch
import numpy as np
t1 = np.array(torch.Tensor([[1, 2, 3],
[1, 2, 3]]))
t2 = torch.Tensor(np.array([[1, 2, 3],
[1, 2, 3]]))
運行結果:
2.3 常用api
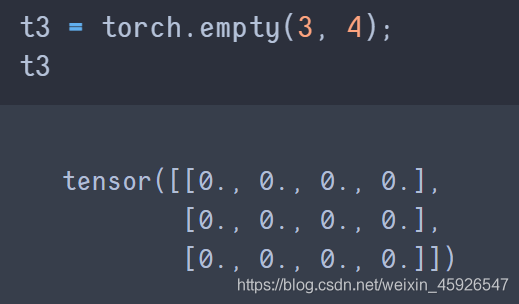
torch.empty(x,y)
創建x行y列為空的tensor。
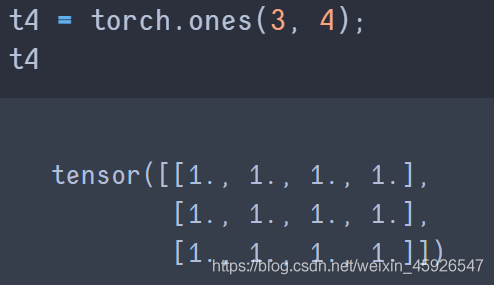
torch.ones([x, y])
創建x行y列全為1的tensor。
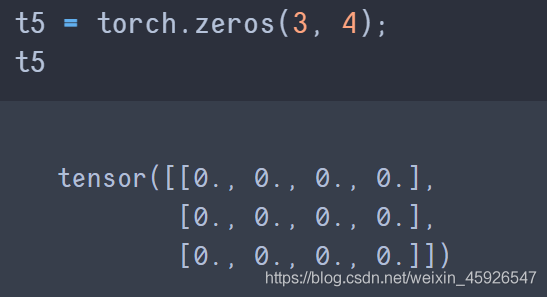
torch.zeros([x,y])
創建x行y列全為0的temsor。
zeros與empty的區別
後者的數據類型是不固定的。
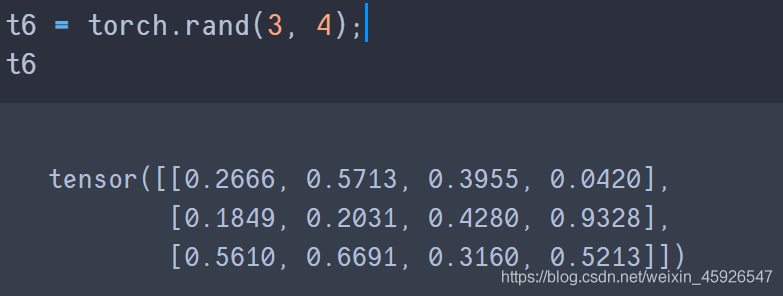
torch.rand(x, y)
創建3行4列的隨機數,隨機數是0-1。
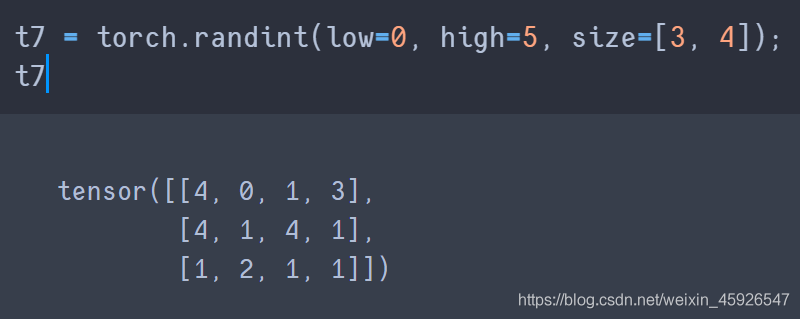
torch.randint(low, high, size)
創建一個size的tensor,隨機數為low到high之間。
torch.randn([x, y])
創建一個x行y列的tensor,隨機數的分佈式均值為0,方差1。
2.4 常用方法
item():
獲取tensor中的元素,註意隻有
一個元素的時候才可以用。

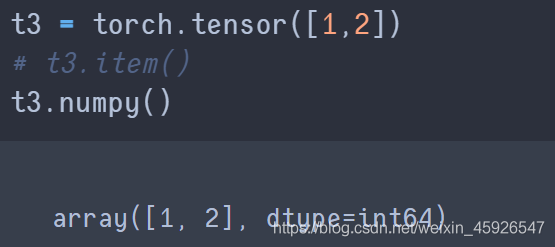
numpy():
轉化成
ndarray類型。
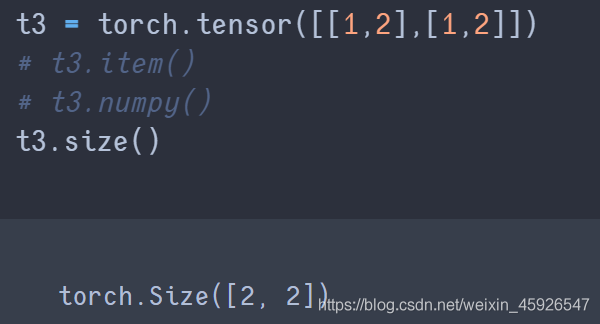
size()
獲取tensor的
形狀。
view()
淺拷貝,tensor的形狀改變。可以傳參,表示獲取第幾個。若參數為-1,表示不確定,與另一個參數的乘積等於原始形狀的乘積。 例如:原始形狀為8,則
view(-1,2)⇒view(4, 2); 參數隻有-1,表示一維。

dim()
獲取維度。

max()
獲取最大值。
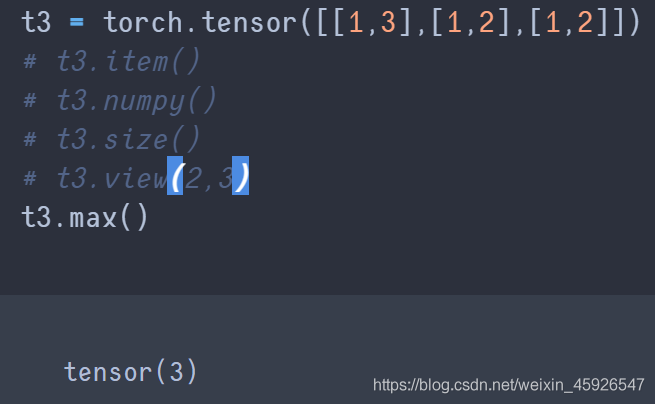
t()
轉置。
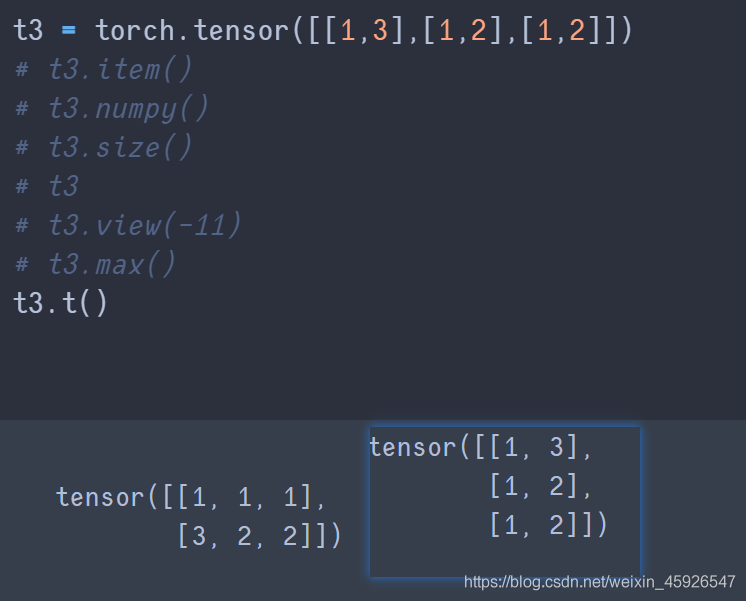
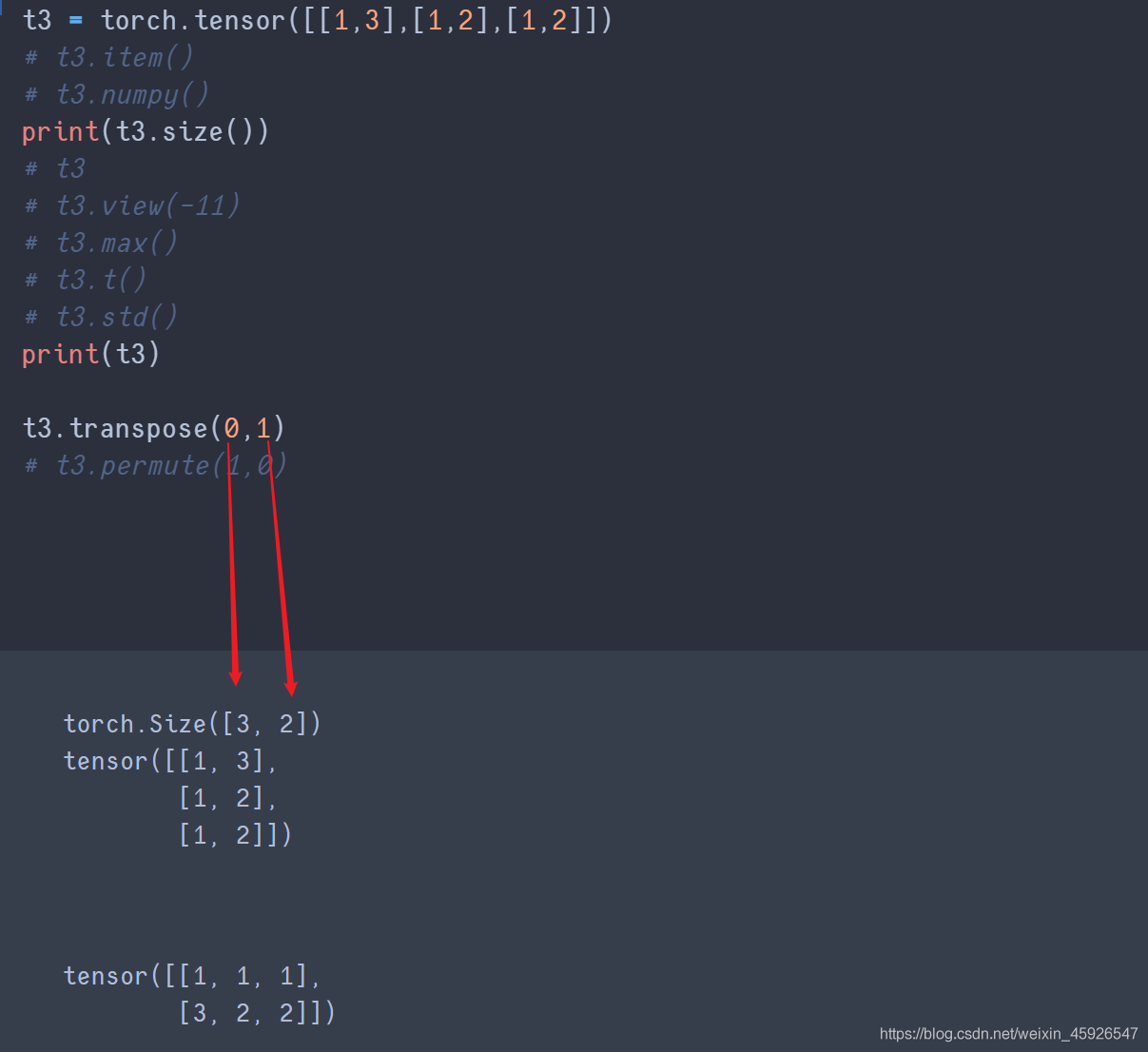
transpose(x,y)
x,y是size裡面返回的形狀相換。
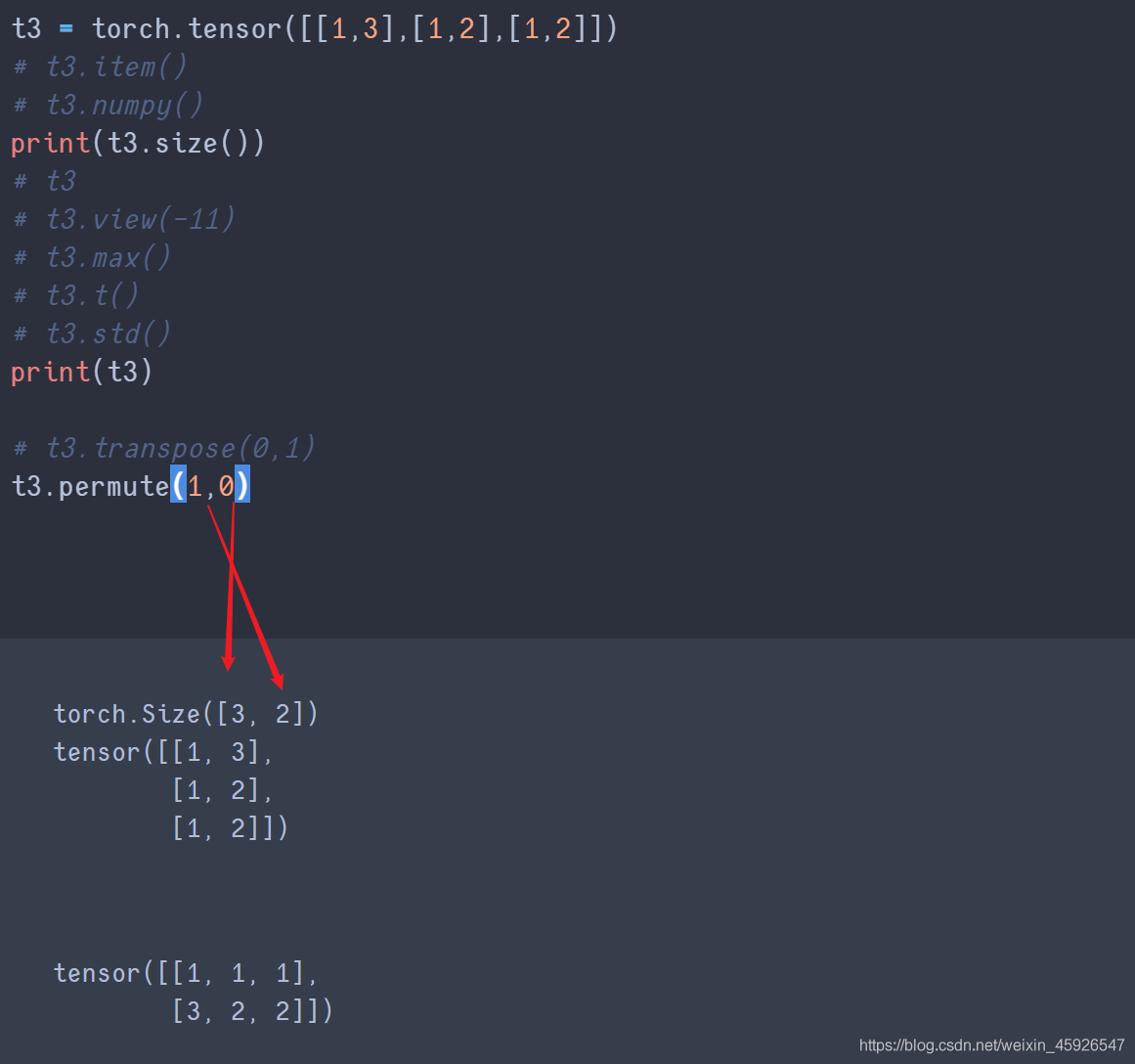
permute()
傳入size()返回的形狀的順序。
transpose與permute的區別
前者傳入列即可相互交換;後者傳入列會根據傳入的順序來進行轉化,且需要傳入所有列數的索引。
取值[第一階, 第二階,……]
一個逗號隔開代表一個階乘冒號代表全取
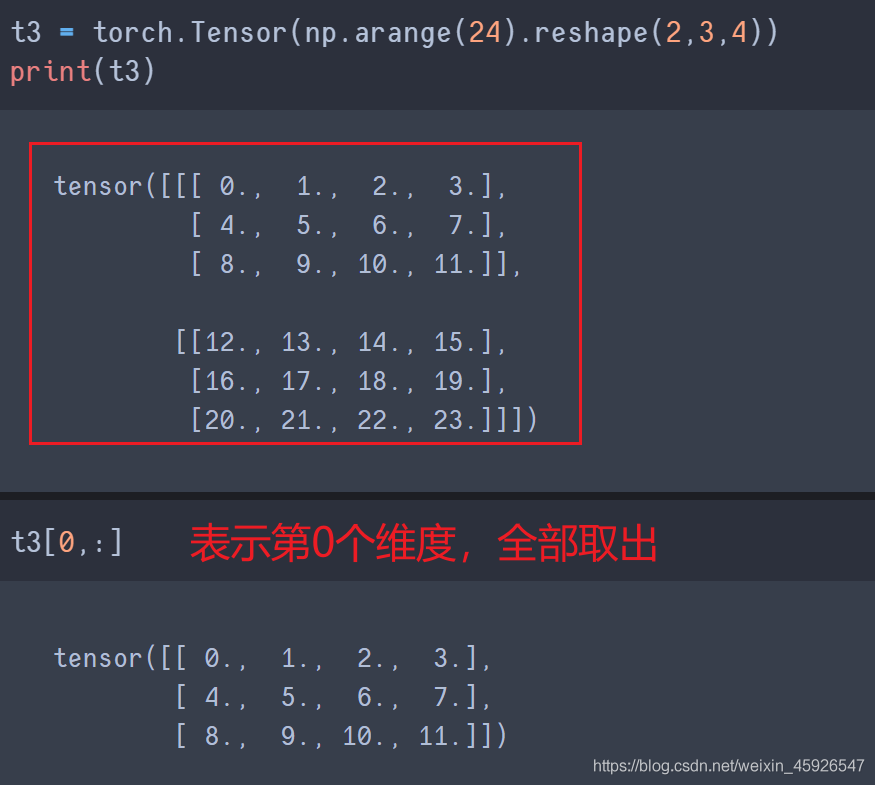
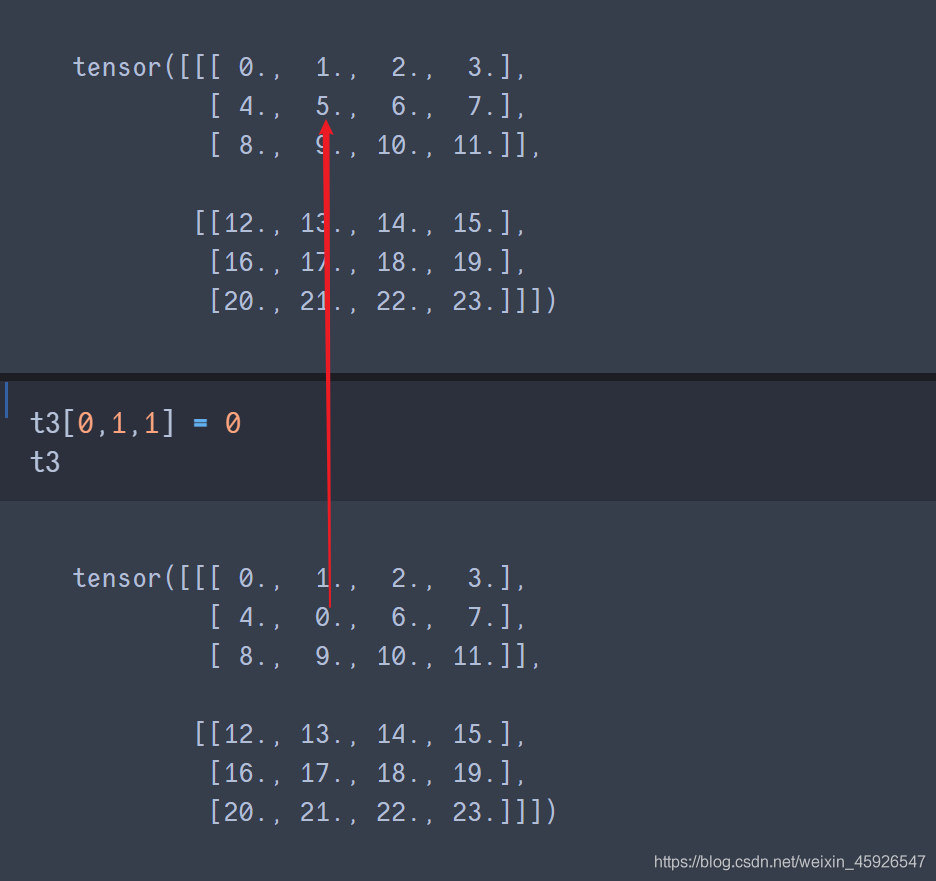
賦值[第一階, 第二階,……]
直接賦值即可
三、數據類型
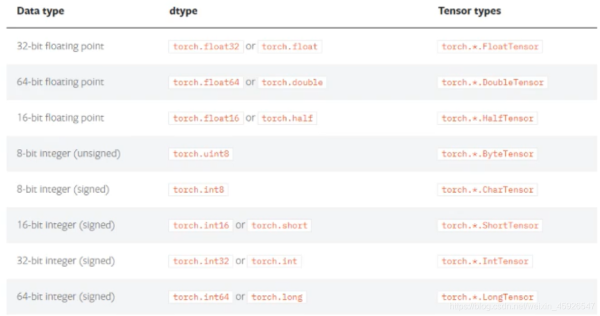
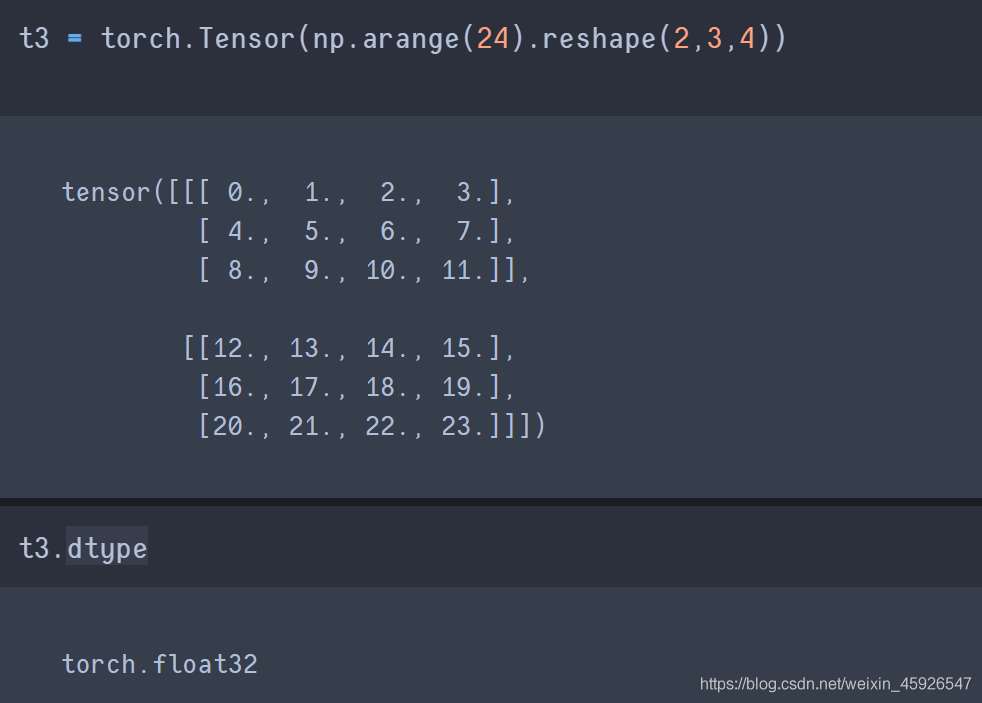
3.1 獲取數據類型
tensor.dtype
獲取數據類型
設置數據類型
註意使用
Tensor()不能指定數據類型。
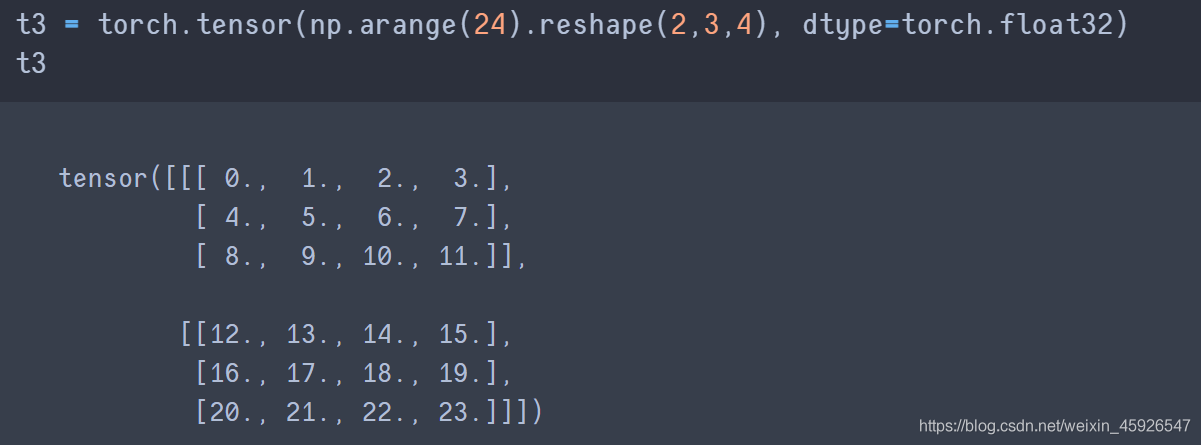
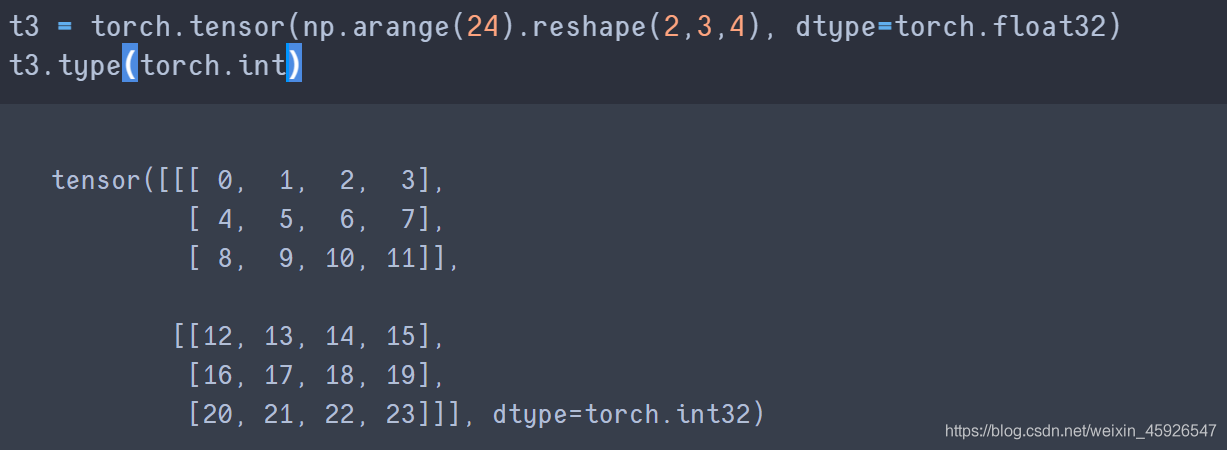
type()
修改數據類型。
四、tensor的其他操作
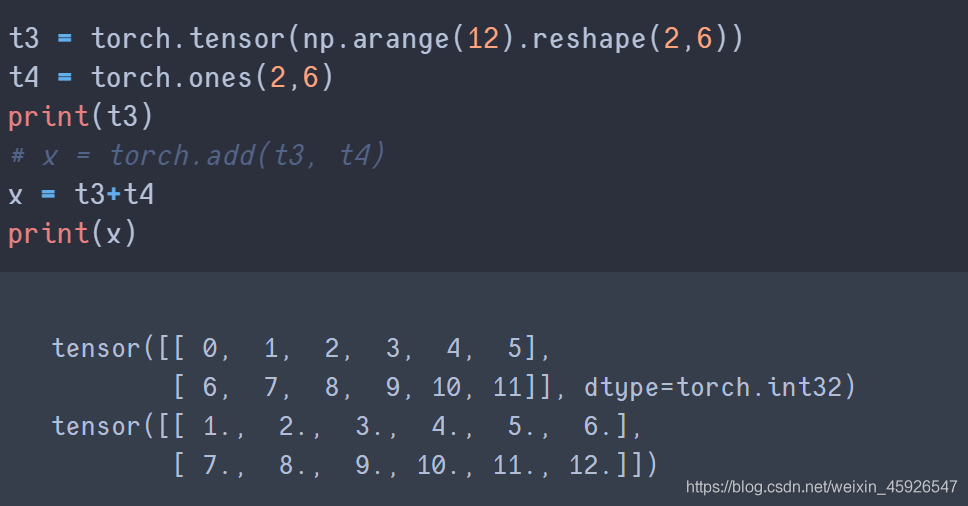
4.1 相加
torch.add(x, y)
將x和y
相加。

直接相加
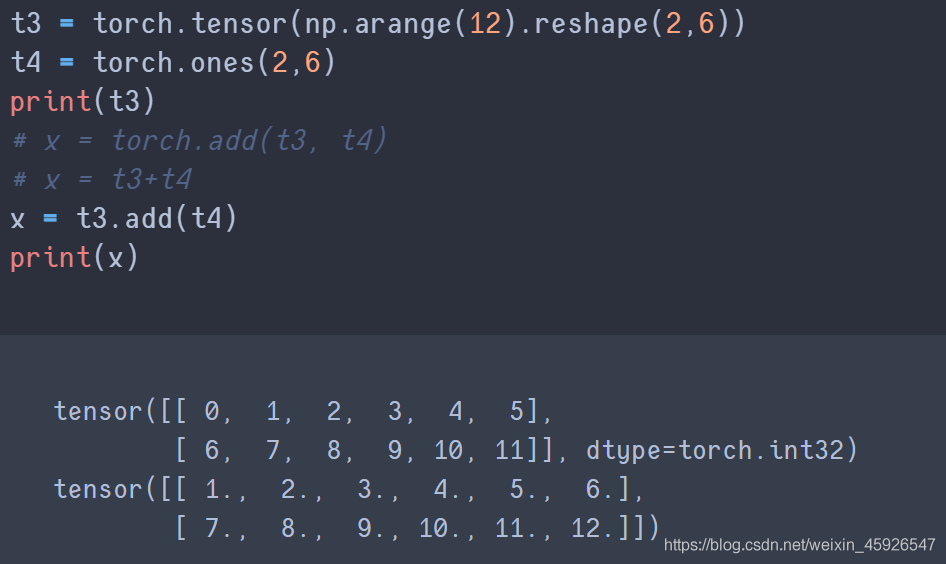
tensor.add()
使用add_() 可相加後直接保存在tensor中
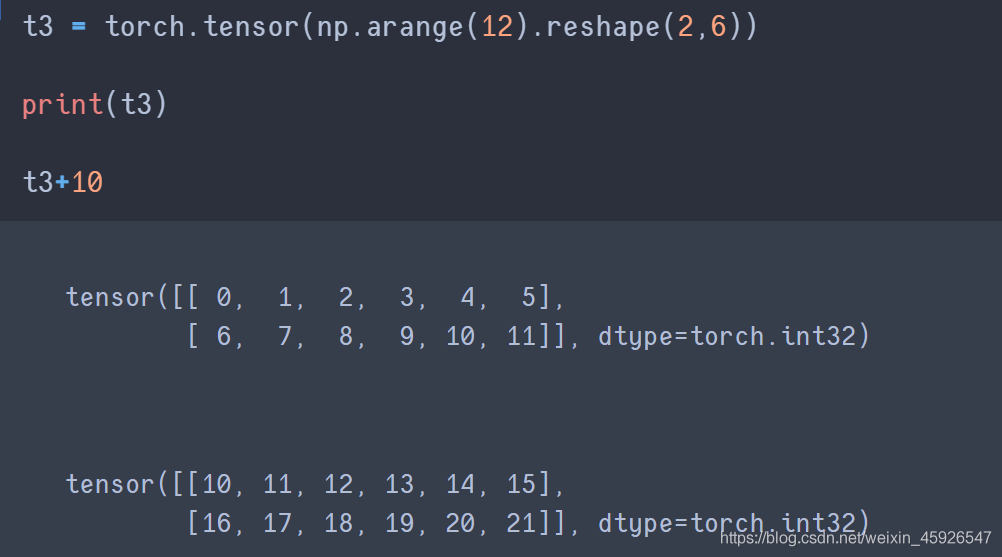
4.2 tensor與數字的操作
tensor + 數值
五、CUDA中的tensor
CUDA (Compute Unified Device Architecture),是NVIDIA推出的運算平臺。CUDATM是一種由NVIDIA推出的通用並行計算架構,該架構使GPU能夠解決復雜的計算問題。
torch.cuda這個模塊增加瞭對CUDA tensor的支持,能夠在cpu和gpu上使用相同的方法操作tensor通過.to方法能夠把一個tensor轉移到另外一個設備(比如從CPU轉到GPU)
可以使用torch.cuda.is_available()判斷電腦是否支持GPU
到此這篇關於Python深度學習之Pytorch初步使用的文章就介紹到這瞭,更多相關Pytorch初步使用內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- PyTorch中Tensor和tensor的區別及說明
- pytorch教程之Tensor的值及操作使用學習
- 人工智能學習Pytorch教程Tensor基本操作示例詳解
- PyTorch中的CUDA的操作方法
- pytorch tensor計算三通道均值方式