Pandas 實現分組計數且不計重復
在對dataframe進行分析的時候會遇到需要分組計數,計數的column中屬性有重復,但又需要僅對不重復的項計數(即重復N次出現的項隻計1次)。
函數如下:
dataframe.groupby([‘分組的列名’]).需要計數的列名.nunique()
舉例:
數組“data”如下:
| StoreID | Sales | SalesDate | Channel |
|---|---|---|---|
| A | 100 | 2018/1/1 | 01 |
| A | 90 | 2018/1/1 | 02 |
| A | 110 | 2018/1/2 | 01 |
| B | 82.2 | 2018/1/1 | 01 |
| B | 90 | 2018/1/2 | 02 |
如果要按StoreID來統計每一傢店的營業日期數(可以通過不計重復的count “SalesDate”來完成)
代碼如下:
data.groupby(['StoreID']).SalesDate.nunique()
補充:pandas 統計分組內不重復計數
在數據分析中的數據處理過程中,經常需要對數據進行分組計數,看下下面這組數據
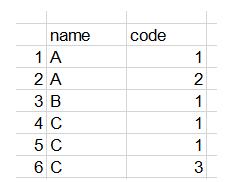
數據中name 為C 的有三行,其中有2個code是重復的
目標:
按name 分組,統計每組中code的不重復數量
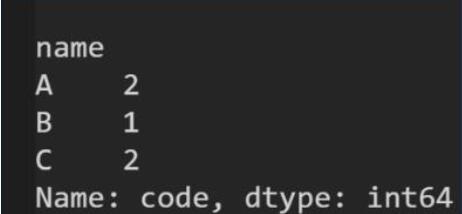
df.groupby('name')['code'].nunique()
# 以name 分組後,統計code的不重復數目
結果如下:
排序
df.groupby('name')['code'].nunique().sort_values(ascending=False)
# 以name 分組後,統計code的不重復數目
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- pandas groupby分組對象的組內排序解決方案
- python中pandas對多列進行分組統計的實現
- python數據處理67個pandas函數總結看完就用
- Pandas數值排序 sort_values()的使用
- pandas組內排序,並在每個分組內按序打上序號的操作