使用Pytorch實現two-head(多輸出)模型的操作
如何使用Pytorch實現two-head(多輸出)模型
1. two-head模型定義
先放一張我要實現的模型結構圖:
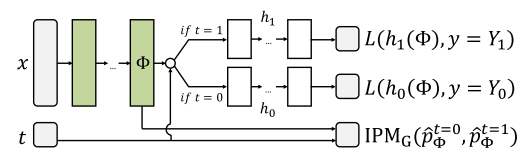
如上圖,就是一個two-head模型,也是一個但輸入多輸出模型。該模型的特點是輸入一個x和一個t,h0和h1中隻有一個會輸出,所以可能這不算是一個典型的多輸出模型。
2.實現所遇到的困難 一開始的想法:
這不是很簡單嘛,做一個判斷不就完瞭,t=0時模型為前半段加h0,t=1時模型為前半段加h1。但實現的時候傻眼瞭,發現在真正前向傳播的時候t是一個tensor,有0有1,沒法兒進行判斷。
靈機一動,又生一法:把這個模型變為三個模型,前半段是一個模型(r),後面的h0和h1分別為另兩個模型。把數據集按t=0和1分開,分別訓練兩個模型:r+h0和r+h1。
但是後來搜如何進行模型串聯,發現極為麻煩。
3.解決方案
後來在pytorch的官方社區中看到一個極為簡單的方法:
(1) 按照一般的多輸出模型進行實現,代碼如下:
def forward(self, x):
#三層的表示層
x = F.elu(self.fcR1(x))
x = F.elu(self.fcR2(x))
x = F.elu(self.fcR3(x))
#two-head,兩個head分別進行輸出
y0 = F.elu(self.fcH01(x))
y0 = F.elu(self.fcH02(y0))
y0 = F.elu(self.fcH03(y0))
y1 = F.elu(self.fcH11(x))
y1 = F.elu(self.fcH12(y1))
y1 = F.elu(self.fcH13(y1))
return y0, y1
這樣就相當實現瞭一個多輸出模型,一個x同時輸出y0和y1.
訓練的時候分別訓練,也即分別建loss,代碼如下:
f_out_y0, _ = net(x0)
_, f_out_y1 = net(x1)
#實例化損失函數
criterion0 = Loss()
criterion1 = Loss()
loss0 = criterion0(f_y0, f_out_y0, w0)
loss1 = criterion1(f_y1, f_out_y1, w1)
print(loss0.item(), loss1.item())
#對網絡參數進行初始化
optimizer.zero_grad()
loss0.backward()
loss1.backward()
#對網絡的參數進行更新
optimizer.step()
先把x按t=0和t=1分為x0和x1,然後分別送入進行訓練。這樣就實現瞭一個two-head模型。
4.後記
我自以為多輸出模型可以分為以下兩類:
多個輸出不同時獲得,如本文情況。
多個輸出同時獲得。
多輸出不同時獲得的解決方法上文已說明。多輸出同時獲得則可以通過把y0和y1拼接起來一起輸出來實現。
補充:PyTorch 多輸入多輸出模型構建
本篇教程基於 PyTorch 1.5版本
直接上代碼!
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.distributed as dist
import torch.utils.data as data_utils
class Net(nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net, self).__init__()
self.hidden1 = nn.Linear(n_input, n_hidden)
self.hidden2 = nn.Linear(n_hidden, n_hidden)
self.predict1 = nn.Linear(n_hidden*2, n_output)
self.predict2 = nn.Linear(n_hidden*2, n_output)
def forward(self, input1, input2): # 多輸入!!!
out01 = self.hidden1(input1)
out02 = torch.relu(out01)
out03 = self.hidden2(out02)
out04 = torch.sigmoid(out03)
out11 = self.hidden1(input2)
out12 = torch.relu(out11)
out13 = self.hidden2(out12)
out14 = torch.sigmoid(out13)
out = torch.cat((out04, out14), dim=1) # 模型層拼合!!!當然你的模型中可能不需要~
out1 = self.predict1(out)
out2 = self.predict2(out)
return out1, out2 # 多輸出!!!
net = Net(1, 20, 1)
x1 = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 請不要關心這裡,隨便弄一個數據,為瞭說明問題而已
y1 = x1.pow(3)+0.1*torch.randn(x1.size())
x2 = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y2 = x2.pow(3)+0.1*torch.randn(x2.size())
x1, y1 = (Variable(x1), Variable(y1))
x2, y2 = (Variable(x2), Variable(y2))
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
loss_func = torch.nn.MSELoss()
for t in range(5000):
prediction1, prediction2 = net(x1, x2)
loss1 = loss_func(prediction1, y1)
loss2 = loss_func(prediction2, y2)
loss = loss1 + loss2 # 重點!
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 100 == 0:
print('Loss1 = %.4f' % loss1.data,'Loss2 = %.4f' % loss2.data,)
至此搞定!
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。
推薦閱讀:
- pytorch訓練神經網絡爆內存的解決方案
- 返回最大值的index pytorch方式
- Pytorch寫數字識別LeNet模型
- 基於Pytorch實現邏輯回歸
- 人工智能學習Pytorch梯度下降優化示例詳解