Python爬蟲實戰之爬取攜程評論
一、分析數據源
這裡的數據源是指html網頁?還是Aajx異步。對於爬蟲初學者來說,可能不知道怎麼判斷,這裡辰哥也手把手過一遍。
提示:以下操作均不需要登錄(當然登錄也可以)
咱們先在瀏覽器裡面搜索攜程,然後在攜程裡面任意搜索一個景點:長隆野生動物世界,這裡就以長隆野生動物世界為例,講解如何去爬取攜程評論數據。

頁面下方則是評論數據

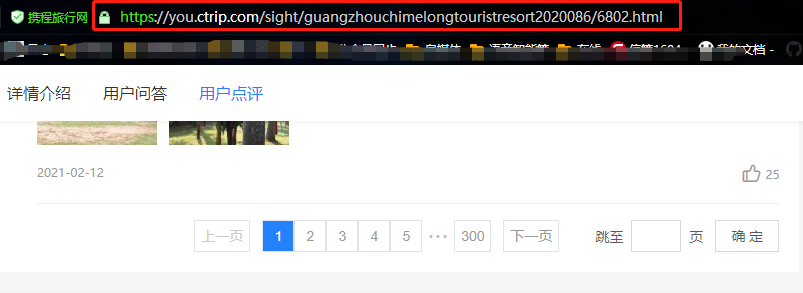

從上面兩張圖可以看出,點擊評論下一頁,瀏覽器的鏈接沒有變化,說明數據是Ajax異步請求。因此我們就找到瞭數據是異步加載過來的,這時候需要去network裡面是查看數據包。
二、分析數據包
在network中找到下面這個數據包

查看Preview裡面的內容(請求返回內容)
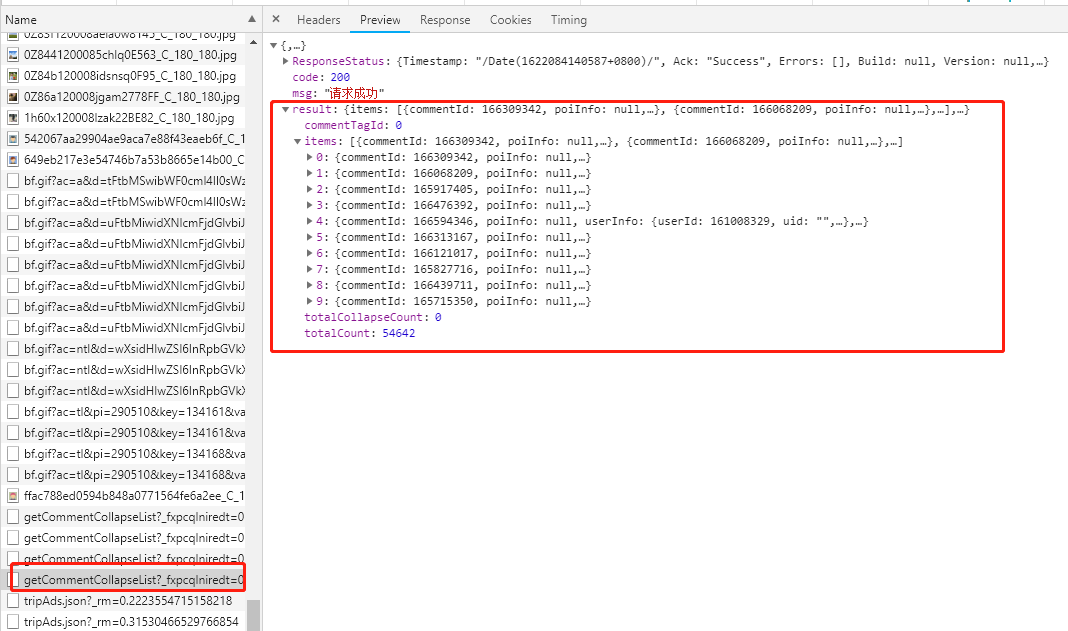
可以看到數據已經請求到瞭,下面看一下數據是否是正確的(和網頁內容一致)。

ok,沒問題之後,下面開始編寫Python程序去請求數據。
1.請求地址

可以獲取到請求鏈接和請求方式。

這裡請求不用添加請求頭header也是可以的。其中postUrl是請求鏈接,data_1是請求參數。
2.請求參數
在network裡可以看到請求參數

在程序中的構建如下:

其中需要關註的是arg中的pageIndex(頁數),pageSize(每頁條數)。
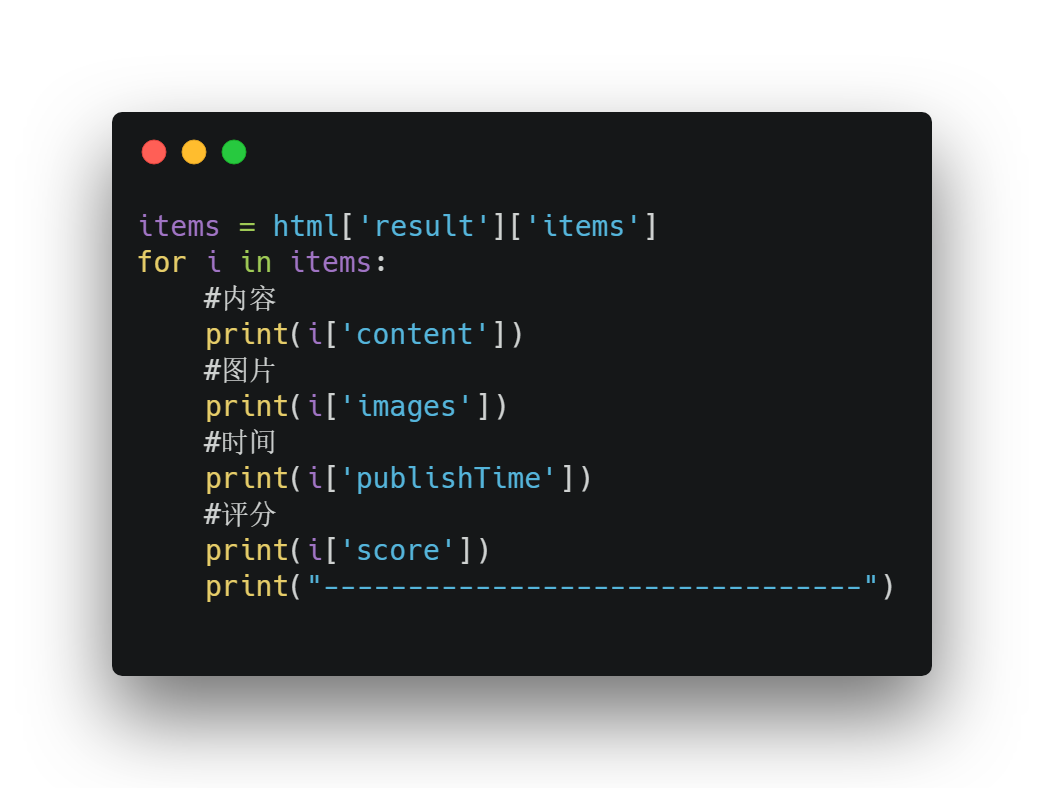
最終結果如下:

該景點的評論就可以成功爬取下來瞭。
三、采集全部評論
上面隻是采集瞭第一頁的評論數據,通過改變arg中的pageIndex(頁數),就可以遍歷爬取全部的評論。

比如這個景點一共是300頁。現在把循環給加上
最終的完整代碼如下:

到此這篇關於Python爬蟲實戰之爬取攜程評論的文章就介紹到這瞭,更多相關Python爬取攜程評論內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python爬取肯德基官網ajax的post請求實現過程
- Python獲取時光網電影數據的實例代碼
- python爬蟲之爬取百度翻譯
- Vue首頁加載白屏原因以及10種解決方法匯總
- Ajax內部交流文檔284278分享