mysql 判斷是否為子集的方法步驟
一、問題
故事起源於一個查詢錯漏率的報表:有兩個查詢結果,分別是報告已經添加的項目和報告應該添加的項目,求報告無遺漏率
何為無遺漏?即,應該添加的項目已經被全部添加
報告無遺漏率也就是無遺漏報告數占報告總數的比率
這裡以兩個報告示例(分別是已全部添加和有遺漏的報告)
首先,查出第一個結果——報告應該添加的項目
SELECT
r.id AS 報告ID,m.project_id 應添加項目
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
RIGHT JOIN application_sample_item si ON s.id=si.sample_id
RIGHT JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id;
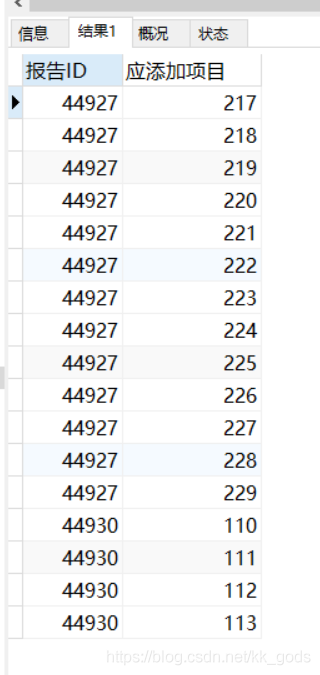
然後,再查出第二個結果——報告已經添加的項目
SELECT r.id AS 報告ID,i.project_id AS 已添加項目
FROM report r
RIGHT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927');
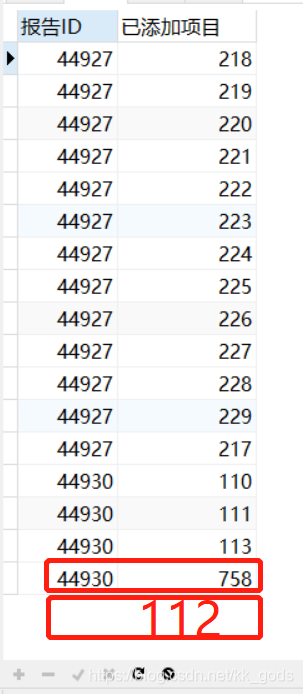
以上就是我們要比較的結果集,不難看出報告44927是無遺漏的,而44930雖然項目數量一致,但實際是多添加瞭項目758,缺少瞭項目112,是有遺漏的報告
二、解決方案
從問題看,顯然是一個判斷是否為子集的問題。可以分別遍歷已添加的項目和應該添加的項目,如果應該添加的項目在已添加的項目中都能匹配上,即代表應該添加的項目是已添加的項目子集,也就是無遺漏。
通過循環遍歷比較確實可以解決這個問題,但是SQL中出現笛卡兒積的交叉連接往往意味著開銷巨大,查詢速度慢,那麼有沒有辦法避免這一問題呢?
方案一:
借助於函數 FIND_IN_SET和GROUP_CONCAT, 首先認識下兩個函數
FIND_IN_SET(str,strlist)
- str: 需要查詢的字符串
- strlist: 參數以英文”,”分隔,如 (1,2,6,8,10,22)
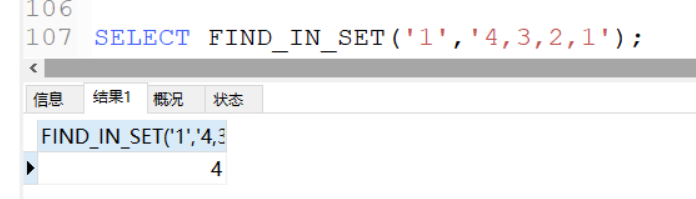
FIND_IN_SET 函數返回瞭需要查詢的字符串在目標字符串的位置
GROUP_CONCAT( [distinct] 要連接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
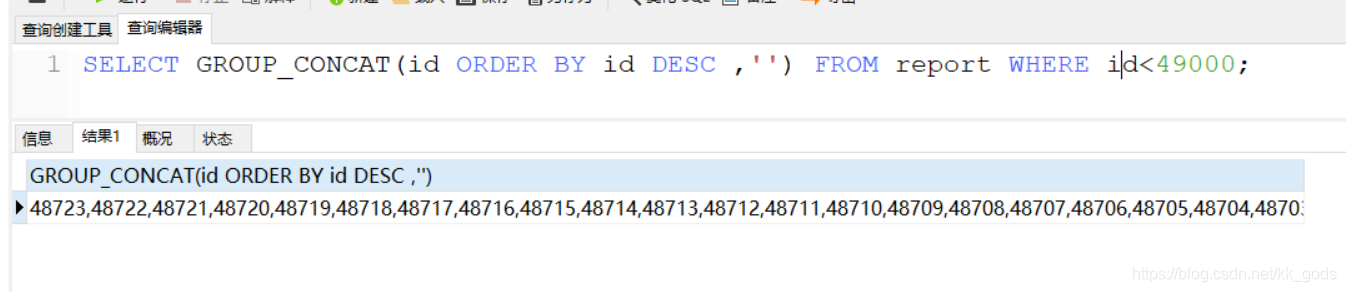
GROUP_CONCAT()函數可以將多條記錄的同一字段的值,拼接成一條記錄返回。默認以英文‘,’分割。
但是,GROUP_CONCAT()默認長度為1024
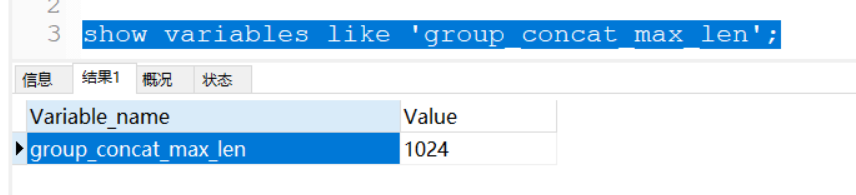
所以,如果需要拼接的長度超過1024將會導致截取不全,需要修改長度
SET GLOBAL group_concat_max_len=102400; SET SESSION group_concat_max_len=102400;
從上述兩個函數介紹中,我們發現FIND_IN_SET和GROUP_CONCAT都以英文‘,’分割(加粗標識)
所以,我們可以用GROUP_CONCAT將已添加項目的項目連接為一個字符串,然後再用FIND_IN_SET逐一查詢應添加項目是否都存在於字符串
1、修改問題中描述中的SQL,用GROUP_CONCAT將已添加項目的項目連接為一個字符串
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加項目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id;

2、用FIND_IN_SET逐一查詢應添加項目是否都存在於字符串
SELECT Q.id,FIND_IN_SET(W.應添加項目列表,Q.已添加項目列表) AS 是否遺漏
FROM
(
-- 報告已經添加的項目
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加項目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)Q,
(
-- 報告應該添加的項目
SELECT
r.id,s.app_id,m.project_id 應添加項目列表
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)W
WHERE Q.id=W.id;
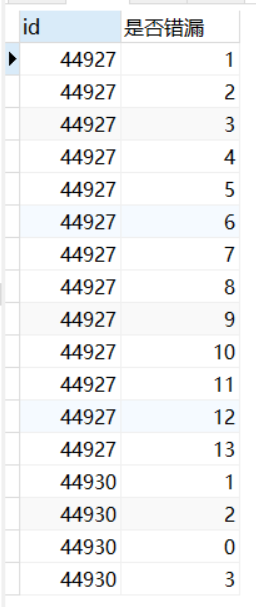
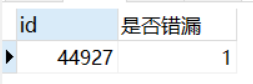
3、過濾掉有遺漏的報告
SELECT Q.id,CASE WHEN FIND_IN_SET(W.應添加項目列表,Q.已添加項目列表)>0 THEN 1 ELSE 0 END AS 是否遺漏
FROM
(
-- 報告已經添加的項目
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加項目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)Q,
(
-- 報告應該添加的項目
SELECT
r.id,s.app_id,m.project_id 應添加項目列表
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)W
WHERE Q.id=W.id
GROUP BY Q.id
HAVING COUNT(`是否遺漏`)=SUM(`是否遺漏`);
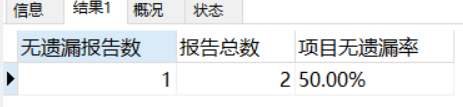
4、我們的最終目標是求無遺漏率
SELECT COUNT(X.id) 無遺漏報告數,Y.total 報告總數, CONCAT(FORMAT(COUNT(X.id)/Y.total*100,2),'%') AS 項目無遺漏率 FROM
(
SELECT Q.id,CASE WHEN FIND_IN_SET(W.應添加項目列表,Q.已添加項目列表)>0 THEN 1 ELSE 0 END AS 是否遺漏
FROM
(
-- 報告已經添加的項目
SELECT r.id,GROUP_CONCAT(i.project_id ORDER BY i.project_id,'') AS 已添加項目列表
FROM report r
LEFT JOIN report_item i ON r.id=i.report_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)Q,
(
-- 報告應該添加的項目
SELECT
r.id,s.app_id,m.project_id 應添加項目列表
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)W
WHERE Q.id=W.id
GROUP BY Q.id
HAVING COUNT(`是否遺漏`)=SUM(`是否遺漏`)
)X,
(
-- 總報告數
SELECT COUNT(E.nums) AS total FROM
(
SELECT COUNT(r.id) AS nums FROM report r
WHERE r.id IN ('44930','44927')
GROUP BY r.id
)E
)Y
;
方案二:
上述方案一雖然避免瞭逐行遍歷對比,但本質上還是對項目的逐一對比,那麼有沒有什麼方式可以不用對比呢?
答案當然是有的。我們可以根據統計數量判斷是否完全包含。
1、使用union all 將已添加項目與應添加項目聯表,不去重
(
-- 應該添加的項目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已經添加的項目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
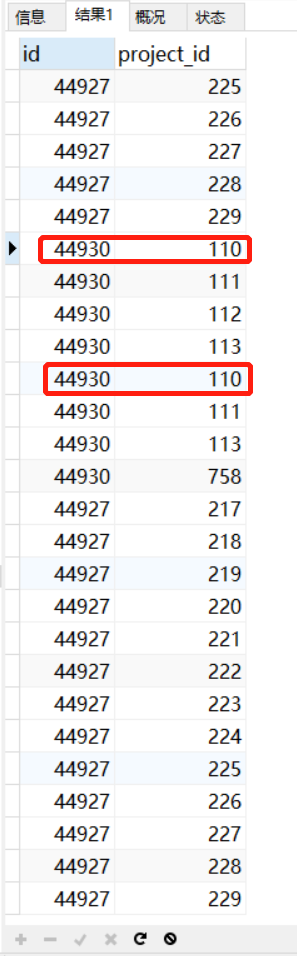
從結果可以看出,項目同一個報告下有重復的項目,分別代表瞭應該添加和已經添加的項目
2、根據聯表結果,統計報告重合的項目數量
# 應該添加與已經添加的項目重疊數量
select tt.id,count(*) count from
(
select t.id,t.project_id,count(*) from
(
(
-- 應該添加的項目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已經添加的項目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
) t
GROUP BY t.id,t.project_id
HAVING count(*) >1
) tt group by tt.id
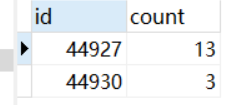
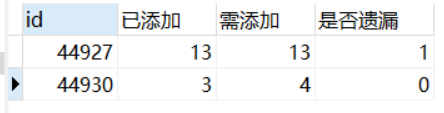
3、將第二步的數量與應該添加的數量作比較,如果相等,則代表無遺漏
select bb.id,aa.count 已添加,bb.count 需添加,
CASE WHEN aa.count/bb.count=1 THEN 1
ELSE 0
END AS '是否遺漏'
from
(
# 應該添加與已經添加的項目重疊數量
select tt.id,count(*) count from
(
select t.id,t.project_id,count(*) from
(
(
-- 應該添加的項目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已經添加的項目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
) t
GROUP BY t.id,t.project_id
HAVING count(*) >1
) tt group by tt.id
) aa RIGHT JOIN
(
-- 應該添加的項目數量
SELECT
r.id,s.app_id,COUNT(m.project_id) count
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
ORDER BY r.id,m.project_id
) bb ON aa.id = bb.id
ORDER BY aa.id
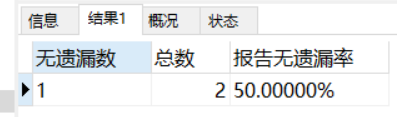
4、求出無遺漏率
select
SUM(asr.`是否遺漏`) AS 無遺漏數,COUNT(asr.id) AS 總數,CONCAT(FORMAT(SUM(asr.`是否遺漏`)/COUNT(asr.id)*100,5),'%') AS 報告無遺漏率
from
(
select bb.id,aa.count 已添加,bb.count 需添加,
CASE WHEN aa.count/bb.count=1 THEN 1
ELSE 0
END AS '是否遺漏'
from
(
# 應該添加與已經添加的項目重疊數量
select tt.id,count(*) count from
(
select t.id,t.project_id,count(*) from
(
(
-- 應該添加的項目
SELECT
r.id,m.project_id
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
ORDER BY r.id,m.project_id
)
UNION ALL
(
-- 已經添加的項目
select r.id,i.project_id from report r,report_item i
where r.id = i.report_id and r.id IN ('44930','44927')
group by r.app_id,i.project_id
)
) t
GROUP BY t.id,t.project_id
HAVING count(*) >1
) tt group by tt.id
) aa RIGHT JOIN
(
-- 應該添加的項目數量
SELECT
r.id,s.app_id,COUNT(m.project_id) count
FROM
report r
INNER JOIN application a ON r.app_id=a.id
INNER JOIN application_sample s ON a.id=s.app_id
INNER JOIN application_sample_item si ON s.id=si.sample_id
INNER JOIN set_project_mapping m ON si.set_id=m.set_id
WHERE r.id IN ('44930','44927')
GROUP BY r.id
ORDER BY r.id,m.project_id
) bb ON aa.id = bb.id
ORDER BY aa.id
) asr;
到此這篇關於mysql 判斷是否為子集的方法步驟的文章就介紹到這瞭,更多相關mysql 判斷是否子集內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 詳解Mysql兩表 join 查詢方式
- MYSQL Left Join優化(10秒優化到20毫秒內)
- MySQL之復雜查詢的實現
- MySQL一些常用高級SQL語句
- 詳細聊聊關於Mysql聯合查詢的那些事兒