python 簡單的股票基金爬蟲
項目地址
https://github.com/aliyoge/fund_crawler_py
所用到的技術
- IP代理池
- 多線程
- 爬蟲
- sql
開始編寫爬蟲
1.首先,開始分析天天基金網的一些數據。經過抓包分析,可知: ./fundcode_search.js包含所有基金代碼的數據。
2.根據基金代碼,訪問地址: fundgz.1234567.com.cn/js/ + 基金代碼 + .js可以獲取基金實時凈值和估值信息。
3.根據基金代碼,訪問地址: fundf10.eastmoney.com/FundArchivesDatas.aspx?type=jjcc&code= + 基金代碼 + &topline=10&year=2021&month=3可以獲取第一季度該基金所持倉的股票。
4.由於這些地址具有反爬機制,多次訪問將會失敗的情況。所以需要搭建IP代理池,用於反爬。搭建很簡單,隻需要將proxy_pool這個項目跑起來就行瞭。
# 通過這個方法就能獲取代理
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
5.搭建完IP代理池後,我們開始著手多線程爬取數據的工作。使用多線程,需要考慮到數據的讀寫順序問題。這裡使用python中的隊列queue存儲基金代碼,不同線程分別從這個queue中獲取基金代碼,並訪問指定基金的數據。因為queue的讀取和寫入是阻塞的,所以可確保該過程不會出現讀取重復和讀取丟失基金代碼的情況。
# 獲取所有基金代碼
fund_code_list = get_fund_code()
fund_len = len(fund_code_list)
# 創建一個隊列
fund_code_queue = queue.Queue(fund_len)
# 寫入基金代碼數據到隊列
for i in range(fund_len):
# fund_code_list[i]也是list類型,其中該list中的第0個元素存放基金代碼
fund_code_queue.put(fund_code_list[i][0])
6.現在開始編寫獲取所有基金的代碼。
# 獲取所有基金代碼
def get_fund_code():
...
# 訪問網頁接口
req = requests.get("http://fund.eastmoney.com/js/fundcode_search.js",
timeout=5,
headers=header)
# 解析出基金代碼存入list中
...
return fund_code_list
7.接下來是從隊列中取出基金代碼,同時獲取基金詳情和基金持倉的股票。
# 當隊列不為空時
while not fund_code_queue.empty():
# 從隊列讀取一個基金代碼
# 讀取是阻塞操作
fund_code = fund_code_queue.get()
...
try:
# 使用該基金代碼進行基金詳情和股票持倉請求
...
8.獲取基金詳情
# 使用代理訪問
req = requests.get(
"http://fundgz.1234567.com.cn/js/" + str(fund_code) + ".js",
proxies={"http": "http://{}".format(proxy)},
timeout=3,
headers=header,
)
# 解析返回數據
...
9.獲取持倉股票信息
# 獲取股票投資明細
req = requests.get(
"http://fundf10.eastmoney.com/FundArchivesDatas.aspx?type=jjcc&code="
+ str(fund_code) + "&topline=10&year=2021&month=3",
proxies={"http": "http://{}".format(proxy)},
timeout=3,
headers=header,
)
# 解析返回數據
...
10.準備一個數據庫,用於存儲數據和對數據進行篩選分析。這裡推薦一個方便的雲數據庫,一鍵創建,一鍵查詢,十分方便,而且是免費的哦。前往MemFireDB註冊一個賬號就能使用。註冊邀請碼:6mxJl6、6mYjGY;

11.創建好數據庫後,點擊連接信息填入代碼中,用於連接數據庫。
# 初始化數據庫連接: engine = create_engine( 'postgresql+psycopg2://username:password@ip:5433/dbname')
12.將數據寫入數據庫中。
with get_session() as s:
# create fund
...
if (create):
s.add(fund)
s.commit()
13.到這裡,大部分工作已經完成瞭,我們在main函數中開啟線程,開始爬取。
# 在一定范圍內,線程數越多,速度越快
for i in range(50):
t = threading.Thread(target=get_fund_data, name="LoopThread" + str(i))
t.start()
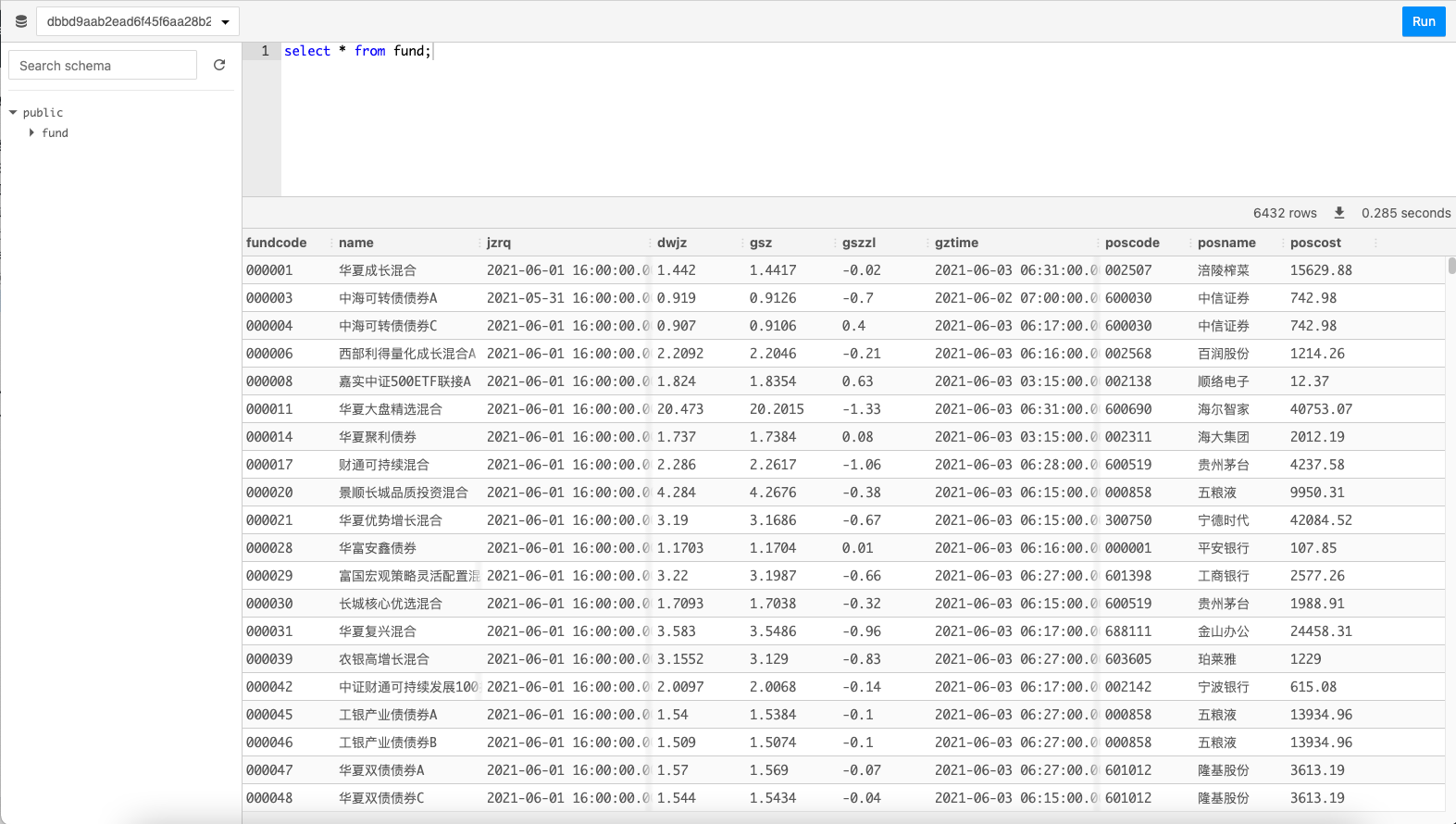
14.等到爬蟲運行完成之後,我們打開MemFireDB,點擊對應數據庫的SQL查詢按鈕,就可以查看我們爬取的數據。哇!我們獲取到瞭6432條數據。
15.接下來讓我們來看看這些基金最喜歡買哪些股票吧。輸入SQL語句select poscode, posname, count(*) as count, cast(sum(poscost) as int) from fund group by poscode, posname order by count desc limit 10;
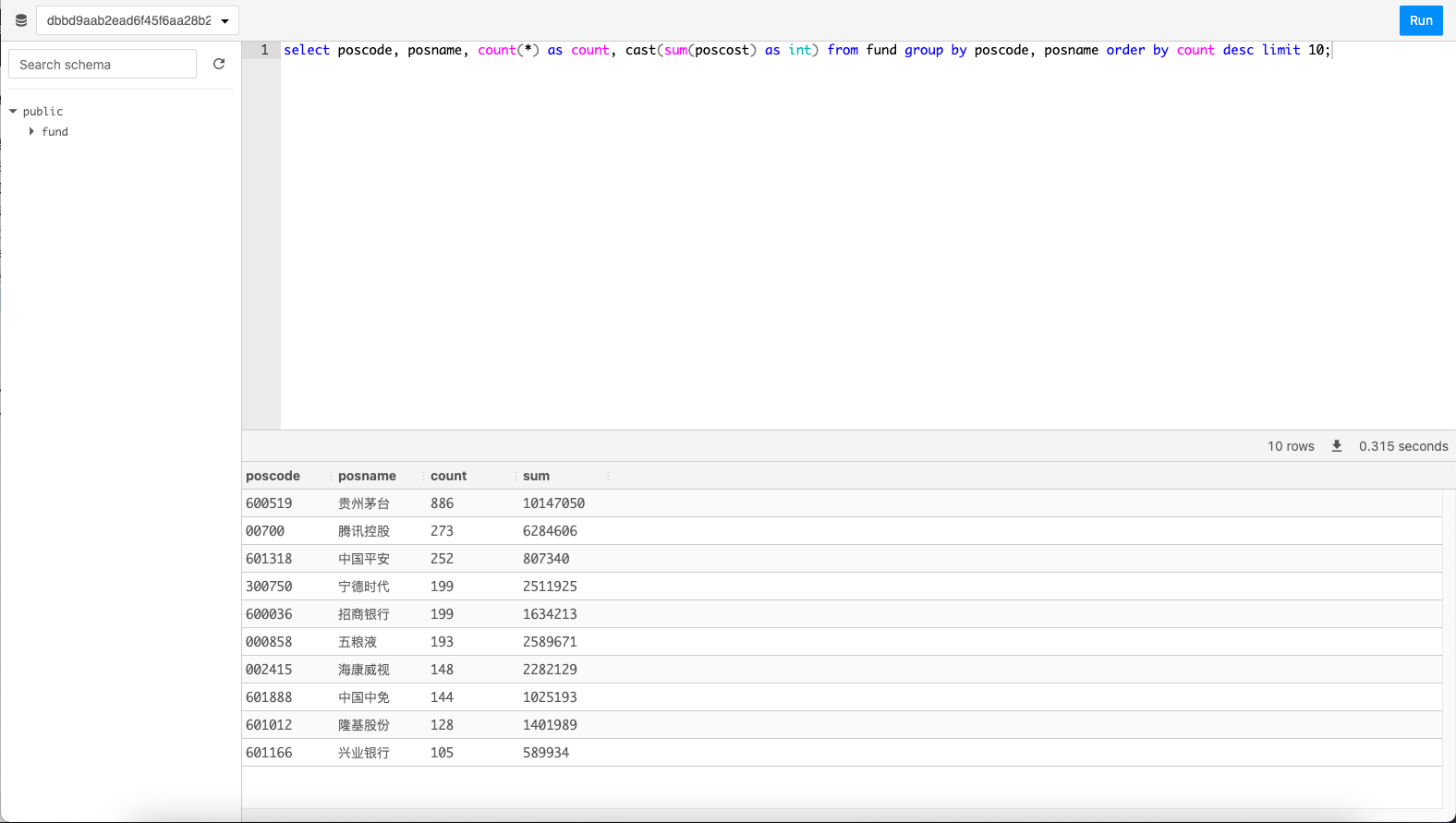
它就是茅臺!
以上就是python 簡單的股票基金爬蟲的詳細內容,更多關於python 股票基金爬蟲的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Python采集天天基金數據掌握最新基金動向
- Python爬蟲實現搭建代理ip池
- 如何在Pycharm中制作自己的爬蟲代碼模板
- python爬取免費代理並驗證代理是否可用
- 用Python獲取亞馬遜商品信息