Python采集天天基金數據掌握最新基金動向
案例實現流程
思路分析:
- 需要什麼數據?需要的數據在哪裡?
代碼實現:
- 發送請求
- 獲取數據
- 解析數據
- 多頁爬取
- 保存數據
知識點:
requests發送請求- 開發者工具的使用
json類型數據解析- 正則表達式的使用
開發環境:
- 版 本:python 3.8
- 編輯器:pycharm 2021.2
本次目標:

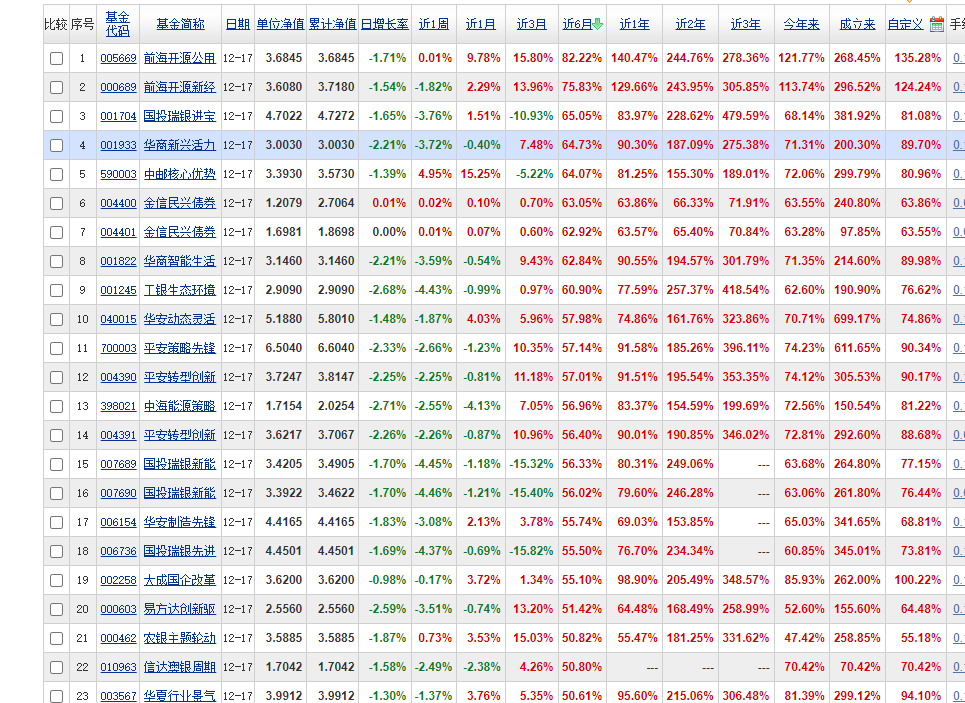
一、分析網站
第一步:打開開發者工具,按F12,或者右鍵點擊檢查
第二步:刷新網站,點擊搜索工具,在搜索框內輸入基金代碼,點擊搜索
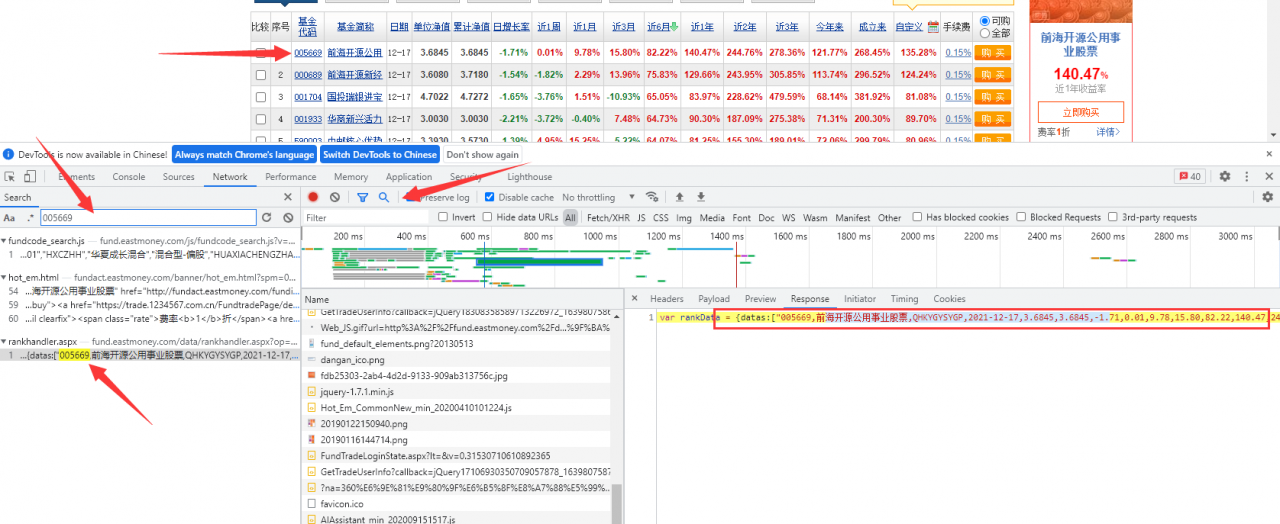
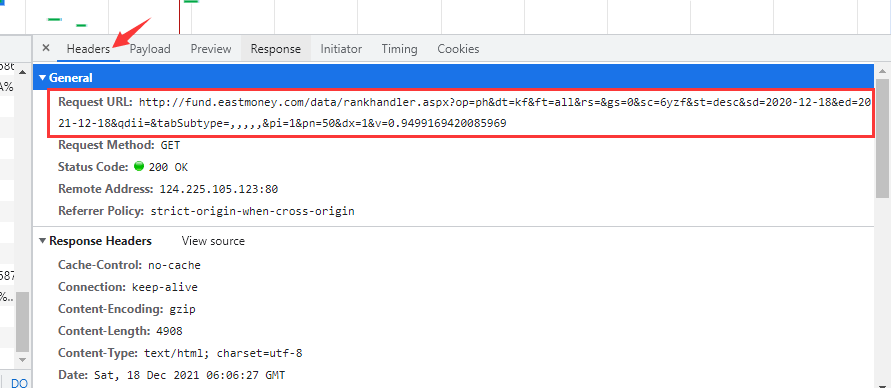
第三步:找到數據所在的真實url
二、開始代碼
導入模塊:
import requests import re import csv
發送請求:
url = f'http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=6yzf&st=desc&sd=2020-12-16&ed=2021-12-16&qdii=&tabSubtype=,,,,,&pi=1&pn=50&dx=1'
headers = {
'Cookie': 'HAList=a-sz-300059-%u4E1C%u65B9%u8D22%u5BCC; em_hq_fls=js; qgqp_b_id=7b7cfe791fce1724e930884be192c85e; _adsame_fullscreen_16928=1; st_si=59966688853664; st_asi=delete; st_pvi=79368259778985; st_sp=2021-12-07%2014%3A33%3A35; st_inirUrl=https%3A%2F%2Fwww.baidu.com%2Flink; st_sn=3; st_psi=20211216201351423-112200312936-0028256540; ASP.NET_SessionId=miyivgzxegpjaya5waosifrb',
'Host': 'fund.eastmoney.com',
'Referer': 'http://fund.eastmoney.com/data/fundranking.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
獲取數據:
data = response.text
解析數據 篩選數據:
data_str = re.findall('\[(.*?)\]', data)[0]
轉變數據類型:
tuple_data = eval(data_str)
for td in tuple_data:
# 把td 變成列表
td_list = td.split(',')
翻頁:
分析不同頁數url變化規律
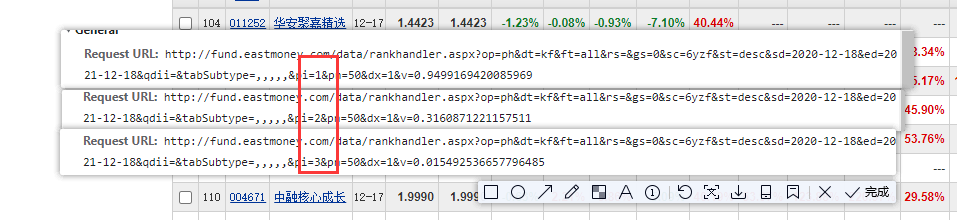
for page in range(1, 193):
print(f'-------------------------正在爬取第{page}頁內容-----------------------')
url = f'http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=6yzf&st=desc&sd=2020-12-16&ed=2021-12-16&qdii=&tabSubtype=,,,,,&pi={page}&pn=50&dx=1'
保存數據:
with open('基金.csv', mode='a', encoding='utf-8', newline='') as f:
csv_write = csv.writer(f)
csv_write.writerow(td_list)
print(td)
三、運行代碼,得到數據

到此這篇關於Python采集天天基金數據掌握最新基金動向的文章就介紹到這瞭,更多相關Python采集天天基金數據內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python 簡單的股票基金爬蟲
- Python爬取股票交易數據並可視化展示
- 教你如何利用python3爬蟲爬取漫畫島-非人哉漫畫
- Python爬蟲之requests庫基本介紹
- Python爬蟲實戰之虎牙視頻爬取附源碼