Java並發容器相關知識總結
一、並發容器
1.1 JDK 提供的並發容器總結
JDK 提供的這些容器大部分在java.util.concurrent包中。
ConcurrentHashMap: 線程安全的 HashMap
CopyOnWriteArrayList: 線程安全的 List,在讀多寫少的場合性能非常好,遠遠好於 Vector.
ConcurrentLinkedQueue: 高效的並發隊列,使用鏈表實現。可以看做一個線程安全的
LinkedList,這是一個非阻塞隊列。
BlockingQueue: 這是一個接口,JDK 內部通過鏈表、數組等方式實現瞭這個接口。表示阻塞隊列,非常適合用於作為數據共享的通道。
ConcurrentSkipListMap: 跳表的實現。這是一個 Map,使用跳表的數據結構進行快速查找。
1.2 ConcurrentHashMap
我們知道 HashMap 不是線程安全的,在並發場景下如果要保證一種可行的方式是使用
Collections.synchronizedMap()方法來包裝我們的 HashMap。但這是通過使用一個全局的鎖來同步不同線程間的並發訪問,因此會帶來不可忽視的性能問題。
所以就有瞭 HashMap 的線程安全版本—— ConcurrentHashMap 的誕生。在 ConcurrentHashMap 中,無論是讀操作還是寫操作都能保證很高的性能:在進行讀操作時(幾乎)不需要加鎖,而在寫操作時 通過鎖分段技術隻對所操作的段加鎖而不影響客戶端對其它段的訪問。
1.3 CopyOnWriteArrayList
1.3.1 CopyOnWriteArrayList 簡介

在很多應用場景中,讀操作可能會遠遠大於寫操作。由於讀操作根本不會修改原有的數據,因此對於每 次讀取都進行加鎖其實是一種資源浪費。我們應該允許多個線程同時訪問 List 的內部數據,畢竟讀取操作是安全的。
這和我們之前在多線程章節講過 ReentrantReadWriteLock 讀寫鎖的思想非常類似,也就是讀讀共享、寫寫互斥、讀寫互斥、寫讀互斥。JDK 中提供瞭 CopyOnWriteArrayList 類比相比於在讀寫鎖的思想又更進一步。為瞭將讀取的性能發揮到極致, CopyOnWriteArrayList 讀取是完全不用加鎖的, 並且更厲害的是:寫入也不會阻塞讀取操作。隻有寫入和寫入之間需要進行同步等待。這樣一來,讀操 作的性能就會大幅度提升。那它是怎麼做的呢?
1.3.2 CopyOnWriteArrayList 是如何做到的?

1.3.3 CopyOnWriteArrayList 讀取和寫入源碼簡單分析
1.3.3.1 CopyOnWriteArrayList 讀取操作的實現
讀取操作沒有任何同步控制和鎖操作,理由就是內部數組 array 不會發生修改,隻會被另外一個 array替換,因此可以保證數據安全。
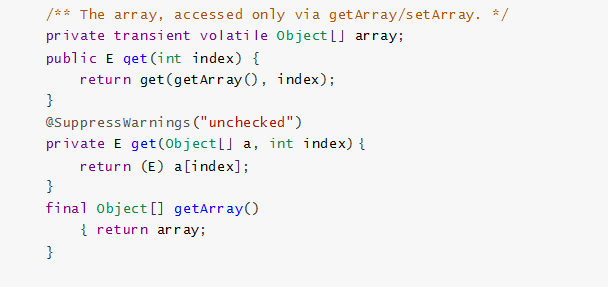
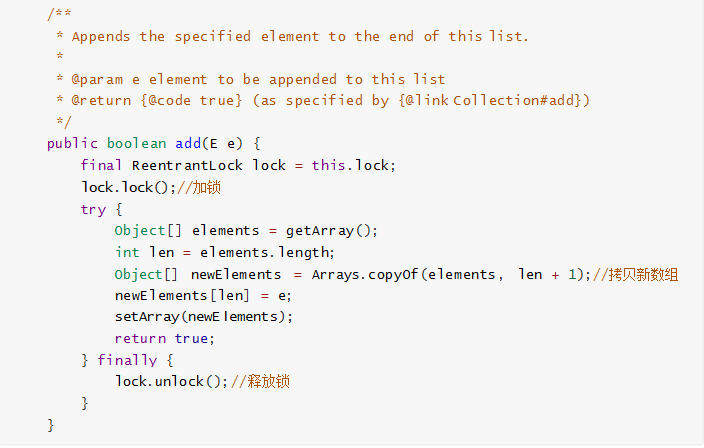
1.3.3.2 CopyOnWriteArrayList 寫入操作的實現
CopyOnWriteArrayList 寫入操作 add() 方法在添加集合的時候加瞭鎖,保證瞭同步,避免瞭多線程寫的時候會 copy 出多個副本出來。
1.4 ConcurrentLinkedQueue

1.5 BlockingQueue
1.5.1 BlockingQueue 簡單介紹
上面我們己經提到瞭 ConcurrentLinkedQueue 作為高性能的非阻塞隊列。下面我們要講到的是阻塞隊列——BlockingQueue。阻塞隊列(BlockingQueue)被廣泛使用在“生產者-消費者”問題中,其原因是BlockingQueue 提供瞭可阻塞的插入和移除的方法。當隊列容器已滿,生產者線程會被阻塞,直到隊列未滿;當隊列容器為空時,消費者線程會被阻塞,直至隊列非空時為止。
BlockingQueue 是一個接口,繼承自 Queue,所以其實現類也可以作為 Queue 的實現來使用,而Queue 又繼承自 Collection 接口。下面是 BlockingQueue 的相關實現類:
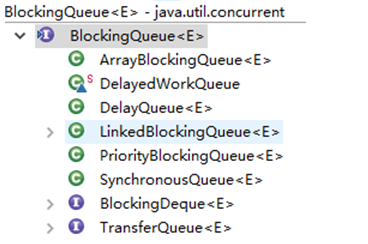
下面主要介紹一下:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,這三個 BlockingQueue 的實現類。
1.5.2 ArrayBlockingQueue


1.5.3 LinkedBlockingQueue
LinkedBlockingQueue 底層基於單向鏈表實現的阻塞隊列,可以當做無界隊列也可以當做有界隊列來使用,同樣滿足 FIFO 的特性,與 ArrayBlockingQueue 相比起來具有更高的吞吐量,為瞭防止LinkedBlockingQueue 容量迅速增,損耗大量內存。通常在創建 LinkedBlockingQueue 對象時,會指定其大小,如果未指定,容量等於 Integer.MAX_VALUE。
相關構造方法:

1.5.4 PriorityBlockingQueue

1.6 ConcurrentSkipListMap
為瞭引出 ConcurrentSkipListMap,先帶著大傢簡單理解一下跳表。
對於一個單鏈表,即使鏈表是有序的,如果我們想要在其中查找某個數據,也隻能從頭到尾遍歷鏈表, 這樣效率自然就會很低,跳表就不一樣瞭。跳表是一種可以用來快速查找的數據結構,有點類似於平衡樹。它們都可以對元素進行快速地查找。但一個重要的區別是:對平衡樹的插入和刪除往往很可能導致 平衡樹進行一次全局的調整。而對跳表的插入和刪除隻需要對整個數據結構的局部進行操作即可。這樣 帶來的好處是:在高並發的情況下,你會需要一個全局鎖來保證整個平衡樹的線程安全。而對於跳表, 你隻需要部分鎖即可。這樣,在高並發環境下,你就可以擁有更好的性能。而就查詢的性能而言,跳表的時間復雜度也是 O(logn) 所以在並發數據結構中,JDK 使用跳表來實現一個 Map。
跳表的本質是同時維護瞭多個鏈表,並且鏈表是分層的
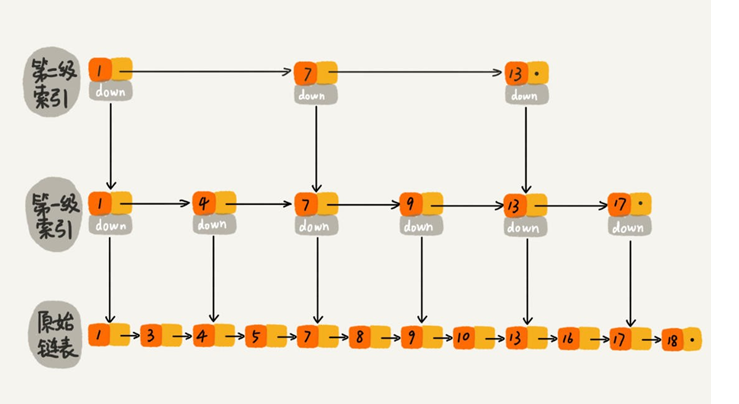
最低層的鏈表維護瞭跳表內所有的元素,每上面一層鏈表都是下面一層的子集。
跳表內的所有鏈表的元素都是排序的。查找時,可以從頂級鏈表開始找。一旦發現被查找的元素大於當前鏈表中的取值,就會轉入下一層鏈表繼續找。這也就是說在查找過程中,搜索是跳躍式的。如上圖所示,在跳表中查找元素 18。
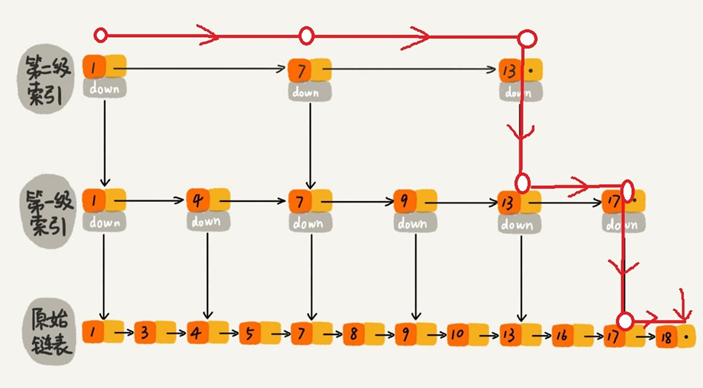
查找 18 的時候原來需要遍歷 18 次,現在隻需要 7 次即可。針對鏈表長度比較大的時候,構建索引查找效率的提升就會非常明顯。
從上面很容易看出,跳表是一種利用空間換時間的算法。
使用跳表實現 Map 和使用哈希算法實現 Map 的另外一個不同之處是:哈希並不會保存元素的順序,而跳表內所有的元素都是排序的。因此在對跳表進行遍歷時,你會得到一個有序的結果。所以,如果你的應用需要有序性,那麼跳表就是你不二的選擇。JDK 中實現這一數據結構的類是ConcurrentSkipListMap。
到此這篇關於Java並發容器相關知識總結的文章就介紹到這瞭,更多相關Java並發容器內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- JAVA 並發容器的一些易出錯點你知道嗎
- Java並發容器介紹
- java並發編程工具類JUC之LinkedBlockingQueue鏈表隊列
- Java十分鐘精通集合的使用與原理上篇
- 詳解Java中的延時隊列 DelayQueue