scrapy-splash簡單使用詳解
1.scrapy_splash是scrapy的一個組件
scrapy_splash加載js數據基於Splash來實現的
Splash是一個Javascrapy渲染服務,它是一個實現HTTP API的輕量級瀏覽器,Splash是用Python和Lua語言實現的,基於Twisted和QT等模塊構建
使用scrapy-splash最終拿到的response相當於是在瀏覽器全部渲染完成以後的網頁源代碼
2.scrapy_splash的作用
scrpay_splash能夠模擬瀏覽器加載js,並返回js運行後的數據
3.scrapy_splash的環境安裝
3.1 使用splash的docker鏡像
docker info 查看docker信息
docker images 查看所有鏡像
docker pull scrapinghub/splash 安裝scrapinghub/splash
docker run -p 8050:8050 scrapinghub/splash & 指定8050端口運行
3.2.pip install scrapy-splash
3.3.scrapy 配置:
SPLASH_URL = 'http://localhost:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
3.4.scrapy 使用
from scrapy_splash import SplashRequest
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
4.測試代碼:
import datetime
import os
import scrapy
from scrapy_splash import SplashRequest
from ..settings import LOG_DIR
class SplashSpider(scrapy.Spider):
name = 'splash'
allowed_domains = ['biqugedu.com']
start_urls = ['http://www.biqugedu.com/0_25/']
custom_settings = {
'LOG_FILE': os.path.join(LOG_DIR, '%s_%s.log' % (name, datetime.date.today().strftime('%Y-%m-%d'))),
'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS': 8,
'AUTOTHROTTLE_ENABLED': True,
'AUTOTHROTTLE_TARGET_CONCURRENCY': 8,
'SPLASH_URL': 'http://localhost:8050',
'DOWNLOADER_MIDDLEWARES': {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
},
'SPIDER_MIDDLEWARES': {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
},
'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter',
'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage',
}
def start_requests(self):
yield SplashRequest(self.start_urls[0], callback=self.parse, args={'wait': 0.5})
def parse(self, response):
"""
:param response:
:return:
"""
response_str = response.body.decode('utf-8', 'ignore')
self.logger.info(response_str)
self.logger.info(response_str.find('http://www.biqugedu.com/files/article/image/0/25/25s.jpg'))
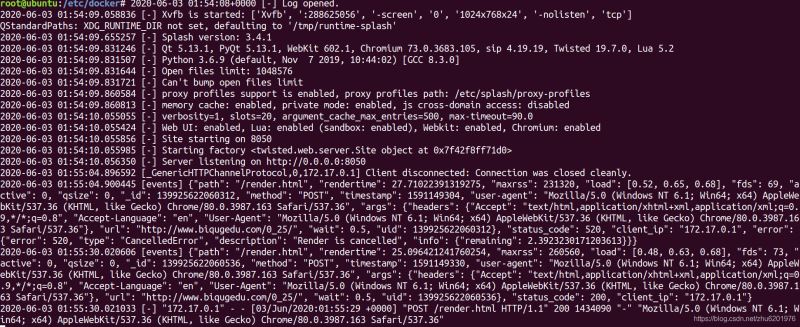
scrapy-splash接收到js請求:
到此這篇關於scrapy-splash簡單使用詳解的文章就介紹到這瞭,更多相關scrapy-splash 使用內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 爬蟲進階-JS自動渲染之Scrapy_splash組件的使用
- scrapy爬蟲遇到js動態渲染問題
- Python Scrapy爬蟲框架使用示例淺析
- 一文讀懂python Scrapy爬蟲框架
- python爬蟲scrapy基本使用超詳細教程