爬蟲進階-JS自動渲染之Scrapy_splash組件的使用
1. 什麼是scrapy_splash?
scrapy_splash是scrapy的一個組件
- scrapy-splash加載js數據是基於Splash來實現的。
- Splash是一個Javascript渲染服務。它是一個實現瞭HTTP API的輕量級瀏覽器,Splash是用Python和Lua語言實現的,基於Twisted和QT等模塊構建。
- 使用scrapy-splash最終拿到的response相當於是在瀏覽器全部渲染完成以後的網頁源代碼。
splash官方文檔
https://splash.readthedocs.io/en/stable/
2. scrapy_splash的作用
scrapy-splash能夠模擬瀏覽器加載js,並返回js運行後的數據
3. scrapy_splash的環境安裝
3.1 使用splash的docker鏡像
splash的dockerfile
https://github.com/scrapinghub/splash/blob/master/Dockerfile
觀察發現splash依賴環境略微復雜,所以我們可以直接使用splash的docker鏡像
如果不使用docker鏡像請參考splash官方文檔 安裝相應的依賴環境
3.1.1 安裝並啟動docker服務
安裝參考 https://www.jb51.net/article/213611.htm
3.1.2 獲取splash的鏡像
在正確安裝docker的基礎上pull取splash的鏡像
sudo docker pull scrapinghub/splash
3.1.3 驗證是否安裝成功
運行splash的docker服務,並通過瀏覽器訪問8050端口驗證安裝是否成功
- 前臺運行
sudo docker run -p 8050:8050 scrapinghub/splash - 後臺運行
sudo docker run -d -p 8050:8050 scrapinghub/splash
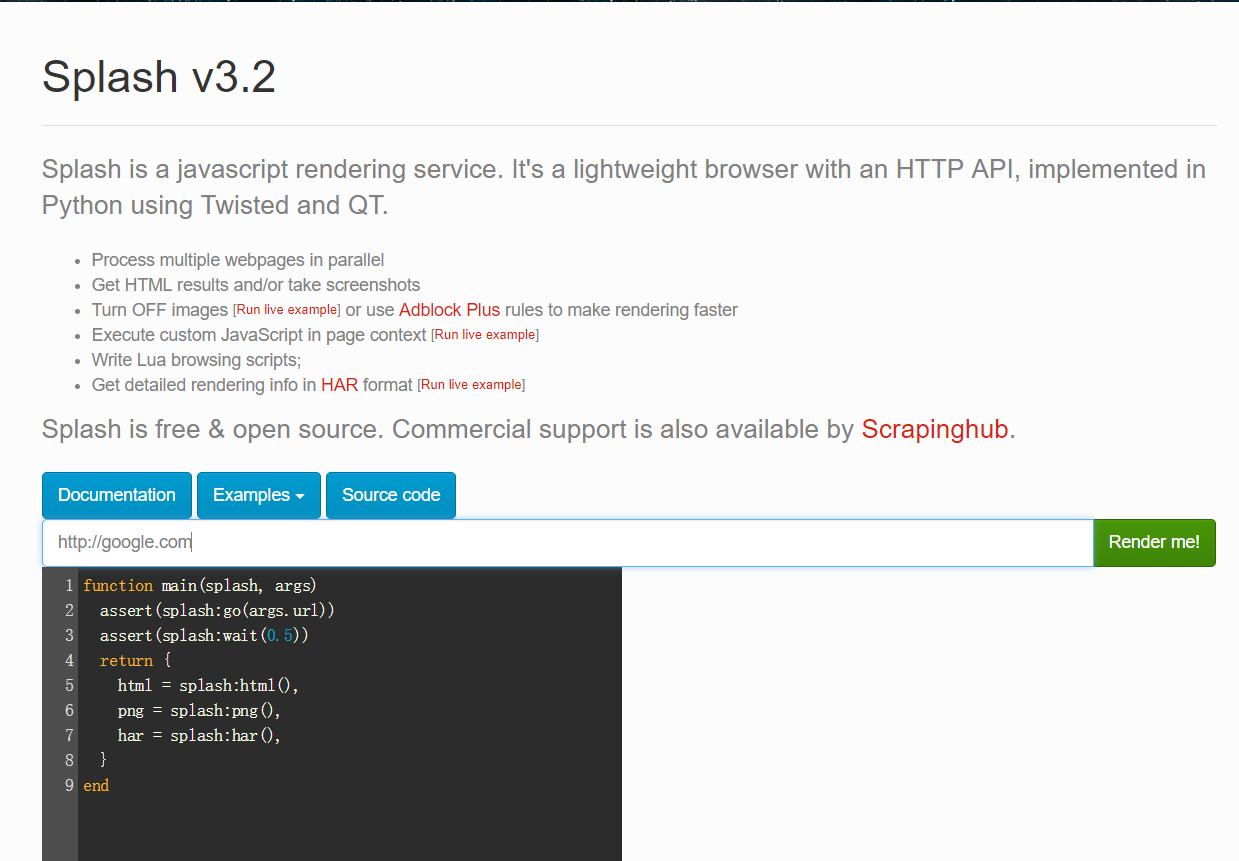
訪問http://127.0.0.1:8050 看到如下截圖內容則表示成功
3.1.4 解決獲取鏡像超時:修改docker的鏡像源
以ubuntu18.04為例
1.創建並編輯docker的配置文件
sudo vi /etc/docker/daemon.json
2.寫入國內docker-cn.com的鏡像地址配置後保存退出
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
3.重啟電腦或docker服務後重新獲取splash鏡像
4.這時如果還慢,請使用手機熱點(流量orz)
3.1.5 關閉splash服務
需要先關閉容器後,再刪除容器
sudo docker ps -a sudo docker stop CONTAINER_ID sudo docker rm CONTAINER_ID
3.2 在python虛擬環境中安裝scrapy-splash包
pip install scrapy-splash
4. 在scrapy中使用splash
以baidu為例
4.1 創建項目創建爬蟲
scrapy startproject test_splash cd test_splash scrapy genspider no_splash baidu.com scrapy genspider with_splash baidu.com
4.2 完善settings.py配置文件
在settings.py文件中添加splash的配置以及修改robots協議
# 渲染服務的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下載器中間件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重過濾器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http緩存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
4.3 不使用splash
在spiders/no_splash.py中完善
import scrapy
class NoSplashSpider(scrapy.Spider):
name = 'no_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def parse(self, response):
with open('no_splash.html', 'w') as f:
f.write(response.body.decode())
4.4 使用splash
import scrapy
from scrapy_splash import SplashRequest # 使用scrapy_splash包提供的request對象
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10}, # 最大超時時間,單位:秒
endpoint='render.html') # 使用splash服務的固定參數
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
4.5 分別運行倆個爬蟲,並觀察現象
4.5.1 分別運行倆個爬蟲
scrapy crawl no_splash scrapy crawl with_splash
4.5.2 觀察獲取的倆個html文件
不使用splash
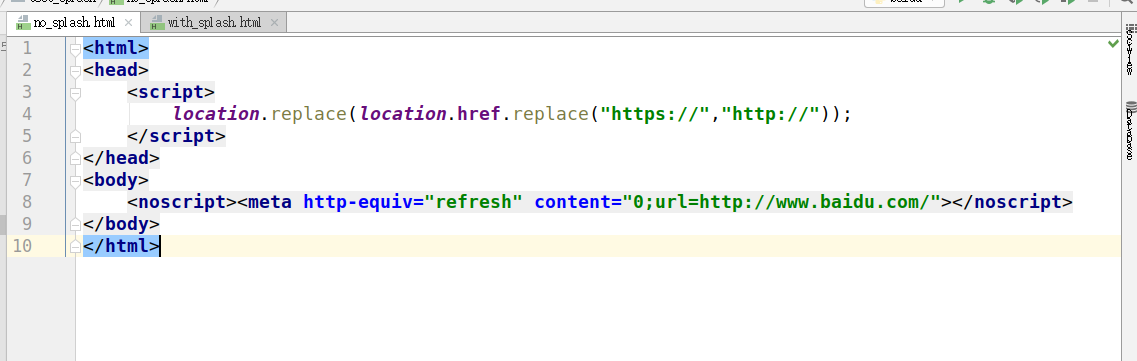
使用splash

4.6 結論
- splash類似selenium,能夠像瀏覽器一樣訪問請求對象中的url地址
- 能夠按照該url對應的響應內容依次發送請求
- 並將多次請求對應的多次響應內容進行渲染
- 最終返回渲染後的response響應對象
5. 瞭解更多
關於splash https://www.jb51.net/article/219166.htm
關於scrapy_splash(截屏,get_cookies等)
https://www.e-learn.cn/content/qita/800748
6. 小結
1.scrapy_splash組件的作用
- splash類似selenium,能夠像瀏覽器一樣訪問請求對象中的url地址
- 能夠按照該url對應的響應內容依次發送請求
- 並將多次請求對應的多次響應內容進行渲染
- 最終返回渲染後的response響應對象
2.scrapy_splash組件的使用
- 需要splash服務作為支撐
- 構造的request對象變為splash.SplashRequest
- 以下載中間件的形式使用
- 需要scrapy_splash特定配置
3.scrapy_splash的特定配置
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
到此這篇關於爬蟲進階-JS自動渲染之Scrapy_splash組件的使用的文章就介紹到這瞭,更多相關js Scrapy_splash組件使用內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- scrapy-splash簡單使用詳解
- scrapy爬蟲遇到js動態渲染問題
- 一文讀懂python Scrapy爬蟲框架
- python爬蟲scrapy基本使用超詳細教程
- Python Scrapy爬蟲框架使用示例淺析