Python爬取動態網頁中圖片的完整實例
動態網頁爬取是爬蟲學習中的一個難點。本文將以知名插畫網站pixiv為例,簡要介紹動態網頁爬取的方法。
寫在前面
本代碼的功能是輸入畫師的pixiv id,下載畫師的所有插畫。由於本人水平所限,所以代碼不能實現自動登錄pixiv,需要在運行時手動輸入網站的cookie值。
重點:請求頭的構造,json文件網址的查找,json中信息的提取
分析
創建文件夾
根據畫師的id創建文件夾(相關路徑需要自行調整)。
def makefolder(id): # 根據畫師的id創建對應的文件夾
try:
folder = os.path.join('E:\pixivimages', id)
os.mkdir(folder)
return folder
except(FileExistsError):
print('the folder exists!')
exit()
獲取作者所有圖片的id
訪問url:https://pixiv.net/ajax/user/畫師id/profile/all(這個json可以在畫師主頁url:https://www.pixiv.net/users/畫師id 的開發者面板中找到,如圖:)
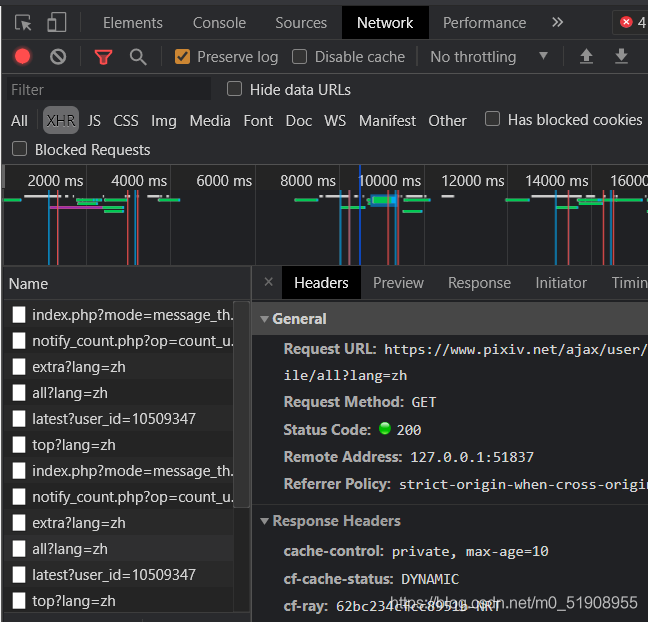
json內容:

將json文檔轉化為python的字典,提取對應元素即可獲取所有的插畫id。
def getAuthorAllPicID(id, cookie): # 獲取畫師所有圖片的id
url = 'https://pixiv.net/ajax/user/' + id + '/profile/all' # 訪問存有畫師所有作品
headers = {
'User-Agent': user_agent,
'Cookie': cookie,
'Referer': 'https://www.pixiv.net/artworks/'
# referer不能缺少,否則會403
}
res = requests.get(url, headers=headers, proxies=proxies)
if res.status_code == 200:
resdict = json.loads(res.content)['body']['illusts'] # 將json轉化為python的字典後提取元素
return [key for key in resdict] # 返回所有圖片id
else:
print("Can not get the author's picture ids!")
exit()
獲取圖片的真實url並下載
訪問url:https://www.pixiv.net/ajax/illust/圖片id?lang=zh,可以看到儲存有圖片真實地址的json:(這個json可以在圖片url:https://www.pixiv.net/artworks/圖片id 的開發者面板中找到)

用同樣的方法提取json中有用的元素:
def getPictures(folder, IDlist, cookie): # 訪問圖片儲存的真實網址
for picid in IDlist:
url1 = 'https://www.pixiv.net/artworks/{}'.format(picid) # 註意這裡referer必不可少,否則會報403
headers = {
'User-Agent': user_agent,
'Cookie': cookie,
'Referer': url1
}
url = 'https://www.pixiv.net/ajax/illust/' + str(picid) + '?lang = zh' #訪問儲存圖片網址的json
res = requests.get(url, headers=headers, proxies=proxies)
if res.status_code == 200:
data = json.loads(res.content)
picurl = data['body']['urls']['original'] # 在字典中找到儲存圖片的路徑與標題
title = data['body']['title']
title = changeTitle(title) # 調整標題
print(title)
print(picurl)
download(folder, picurl, title, headers)
else:
print("Can not get the urls of the pictures!")
exit()
def changeTitle(title): # 為瞭防止
global i
title = re.sub('[*:]', "", title) # 如果圖片中有下列符號,可能會導致圖片無法成功下載
# 註意可能還會有許多不能用於文件命名的符號,如果找到對應符號要將其添加到正則表達式中
if title == '無題': # pixiv中有許多名為'無題'(日文)的圖片,需要對它們加以區分以防止覆蓋
title = title + str(i)
i = i + 1
return title
def download(folder, picurl, title, headers): # 將圖片下載到文件夾中
img = requests.get(picurl, headers=headers, proxies=proxies)
if img.status_code == 200:
with open(folder + '\\' + title + '.jpg', 'wb') as file: # 保存圖片
print("downloading:" + title)
file.write(img.content)
else:
print("download pictures error!")
完整代碼
import requests
from fake_useragent import UserAgent
import json
import re
import os
global i
i = 0
ua = UserAgent() # 生成假的瀏覽器請求頭,防止被封ip
user_agent = ua.random # 隨機選擇一個瀏覽器
proxies = {'http': 'http://127.0.0.1:51837', 'https': 'http://127.0.0.1:51837'} # 代理,根據自己實際情況調整,註意在請求時一定不要忘記代理!!
def makefolder(id): # 根據畫師的id創建對應的文件夾
try:
folder = os.path.join('E:\pixivimages', id)
os.mkdir(folder)
return folder
except(FileExistsError):
print('the folder exists!')
exit()
def getAuthorAllPicID(id, cookie): # 獲取畫師所有圖片的id
url = 'https://pixiv.net/ajax/user/' + id + '/profile/all' # 訪問存有畫師所有作品
headers = {
'User-Agent': user_agent,
'Cookie': cookie,
'Referer': 'https://www.pixiv.net/artworks/'
}
res = requests.get(url, headers=headers, proxies=proxies)
if res.status_code == 200:
resdict = json.loads(res.content)['body']['illusts'] # 將json轉化為python的字典後提取元素
return [key for key in resdict] # 返回所有圖片id
else:
print("Can not get the author's picture ids!")
exit()
def getPictures(folder, IDlist, cookie): # 訪問圖片儲存的真實網址
for picid in IDlist:
url1 = 'https://www.pixiv.net/artworks/{}'.format(picid) # 註意這裡referer必不可少,否則會報403
headers = {
'User-Agent': user_agent,
'Cookie': cookie,
'Referer': url1
}
url = 'https://www.pixiv.net/ajax/illust/' + str(picid) + '?lang = zh' #訪問儲存圖片網址的json
res = requests.get(url, headers=headers, proxies=proxies)
if res.status_code == 200:
data = json.loads(res.content)
picurl = data['body']['urls']['original'] # 在字典中找到儲存圖片的路徑與標題
title = data['body']['title']
title = changeTitle(title) # 調整標題
print(title)
print(picurl)
download(folder, picurl, title, headers)
else:
print("Can not get the urls of the pictures!")
exit()
def changeTitle(title): # 為瞭防止
global i
title = re.sub('[*:]', "", title) # 如果圖片中有下列符號,可能會導致圖片無法成功下載
# 註意可能還會有許多不能用於文件命名的符號,如果找到對應符號要將其添加到正則表達式中
if title == '無題': # pixiv中有許多名為'無題'(日文)的圖片,需要對它們加以區分以防止覆蓋
title = title + str(i)
i = i + 1
return title
def download(folder, picurl, title, headers): # 將圖片下載到文件夾中
img = requests.get(picurl, headers=headers, proxies=proxies)
if img.status_code == 200:
with open(folder + '\\' + title + '.jpg', 'wb') as file: # 保存圖片
print("downloading:" + title)
file.write(img.content)
else:
print("download pictures error!")
def main():
global i
id = input('input the id of the artist:')
cookie = input('input your cookie:') # 半自動爬蟲,需要自己事先登錄pixiv以獲取cookie
folder = makefolder(id)
IDlist = getAuthorAllPicID(id, cookie)
getPictures(folder, IDlist, cookie)
if __name__ == '__main__':
main()
效果
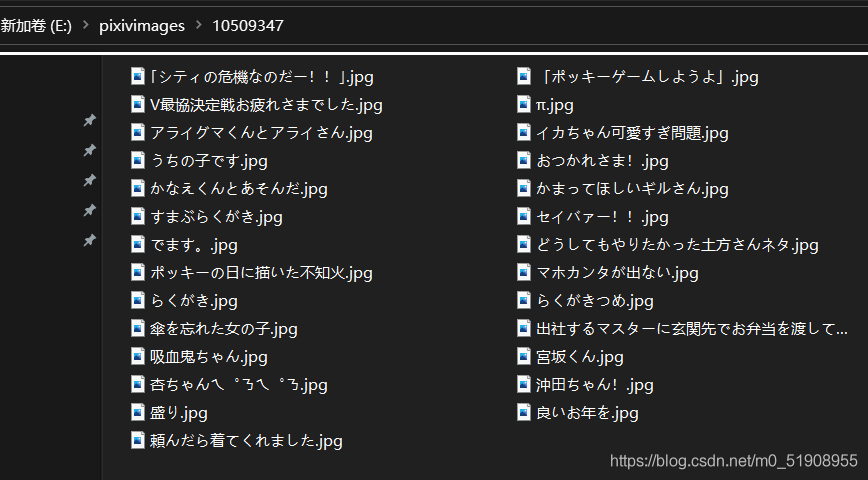
總結
到此這篇關於Python爬取動態網頁中圖片的文章就介紹到這瞭,更多相關Python爬取動態網頁圖片內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python爬蟲之requests庫基本介紹
- python爬蟲之requests庫的使用詳解
- Python爬蟲采集微博視頻數據
- 用Python獲取亞馬遜商品信息
- Python爬蟲Requests庫的使用詳情