R語言 用均值替換、回歸插補及多重插補進行插補的操作
用均值替換、回歸插補及多重插補進行插補
# 設置工作空間
# 把“數據及程序”文件夾拷貝到F盤下,再用setwd設置工作空間
setwd("E:\\R_workspace\\R語言數據分析與挖掘實戰\\chp4")
# 讀取銷售數據文件,提取標題行
inputfile <- read.csv('./data/catering_sale.csv', header = TRUE)
View(inputfile)
# 變換變量名
inputfile <- data.frame(sales = inputfile$'銷量', date = inputfile$'日期')
View(inputfile)
# 數據截取
inputfile <- inputfile[5:16, ]
View(inputfile)
# 缺失數據的識別
is.na(inputfile) # 判斷是否存在缺失
n <- sum(is.na(inputfile)) # 輸出缺失值個數
n
# 異常值識別
par(mfrow = c(1, 2)) # 將繪圖窗口劃為1行兩列,同時顯示兩圖
dotchart(inputfile$sales) # 繪制單變量散點圖
boxplot(inputfile$sales, horizontal = TRUE) # 繪制水平箱形圖
# 異常數據處理
inputfile$sales[5] = NA # 將異常值處理成缺失值
fix(inputfile) # 表格形式呈現數據
# 缺失值的處理
inputfile$date <- as.numeric(inputfile$date) # 將日期轉換成數值型變量
sub <- which(is.na(inputfile$sales)) # 識別缺失值所在行數
sub
# 將數據集分成完整數據和缺失數據兩部分
inputfile1 <- inputfile[-sub, ]
inputfile2 <- inputfile[sub, ]
# 行刪除法處理缺失,結果轉存
result1 <- inputfile1
View(result1)
# 均值替換法處理缺失,結果轉存
avg_sales <- mean(inputfile1$sales) # 求變量未缺失部分的均值
avg_sales
# 用均值替換缺失
inputfile2$sales <- rep(avg_sales,n)
# 並入完成插補的數據
result2 <- rbind(inputfile1, inputfile2)
View(result2)
# 回歸插補法處理缺失,結果轉存
# 回歸模型擬合
# 註意:因變量~自變量
model <- lm(sales ~ date, data = inputfile1)
# 模型預測
inputfile2$sales <- predict(model, inputfile2)
result3 <- rbind(inputfile1, inputfile2)
# 多重插補法處理缺失,結果轉存
library(lattice) # 調入函數包
library(MASS)
library(nnet)
library(mice) # 前三個包是mice的基礎
# 4重插補,即生成4個無缺失數據集
imp <- mice(inputfile, m = 4)
# 選擇插補模型
# inputfile為原始數據,有缺失
fit <- with(imp,lm(sales ~ date, data = inputfile))
# m重復完整數據分析結果池
pooled <- pool(fit)
summary(pooled)
result4 <- complete(imp, action = 3) # 選擇第三個插補數據集作為結果
補充:R語言數據缺失值處理(隨機森林,多重插補)
缺失值是指數據由於種種因素導致的數據不完整,可以分為機械原因和人為原因。對於缺失值我們通常采用以下幾種方法來進行插補。
1.讀取數據
通過read.csv函數導入文檔,也可以用其他函數讀入,如openxlsx::read.xlsx,read.table等。
head()查看數據前幾行。
airquality <- read.csv(data.csv) head(airquality)
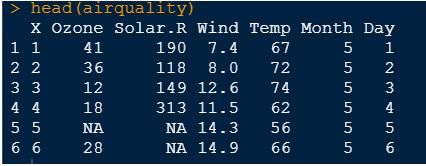
2.檢查數據完整性
首先,summary()查看數據基本信息
summary(airairquality)
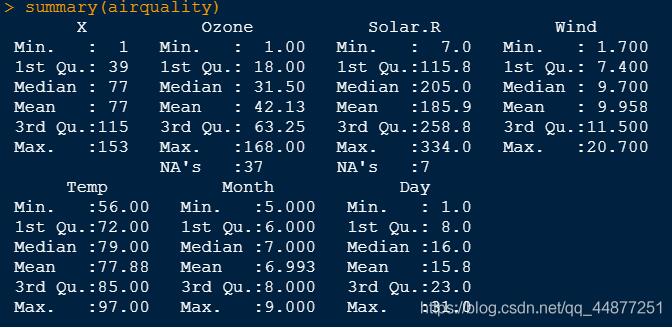
可以看到Ozone中存在缺失值NA
通過調用VIM::aggr()查看函數的缺失值(如果包安裝較慢,可選用本地安裝,鏈接已附需自行下載)
#install.packages(‘VIM') library(VIM) aggr(airquality)

通過上圖,可以看到Ozone和Solar.R存在缺失值。
3.缺失值填補
3.1簡單處理填補
(1)刪除缺失值
若樣本中存在較少缺失值或缺失值比例較小不影響分析結果時,可選擇直接將缺失值刪除。
dat1 <- na.omit(airquality)
(2)平均值、中位數填補
若不能直接將缺失值刪除也可選擇平均值、眾數、中位數等進行填補
#平均值填補
airquality$ Ozone[is.na(airquality$Ozone)] <- mean(airquality $ Ozone,na.rm=T)
#中位數填補
airquality$ Solar.R[is.na(airquality$ Solar.R)] <- median(airquality$ Solar.R,na.rm = T)
#計算缺失值個數,等於0 則不存在缺失值
sum(is.na(airquality))
#相鄰均值填補
airquality <- read.csv(data.csv) #重新讀入數據
for (i in 1:length(airquality$ Ozone)) {
airquality$ Ozone[i] <- ifelse(is.na(airquality$ Ozone[i]),
mean(c(airquality$ Ozone[i-1],airquality$ Ozone[i+1]),na.rm=T),
airquality$ Ozone[i])
}
3.2復雜處理填補
(1)K-近鄰算法填補
基本思想:對於需要填補的觀測值,先利用歐氏距離找到其鄰近的K個觀測,再將這K個鄰近的值進行加權平均進行填補。
原始數據中存在多個缺失值,可以利用DMwR包中的knnImputation()函數進行填補
dat1 <- knnImputation(airquality[,c(1:4)],meth = ‘weighAvg',scale = T)
提取原始數據中的前4列進行填補,meth = ‘weighAvg’指使用加權平均的方法進行填補,scale = T指在選取鄰近值時,先對數據進行標準化。
aggr(dat1) #查看缺失值分佈
(2)隨機森林填補缺失值
接下來介紹一個新的填補方法–隨機森林填補,隨機森林是機器學習中一種常見的方法,以決策樹為基分類的器的集成學習模型。
missForest包中missForest()函數可實現隨機森林填補,ntree代表模型中的樹的棵數,一般情況下,對於高維數據可選擇較小的值(如100),以達到快速插補的效果;對於大數據集進行填補時,可能耗時比較多。
library(missForest) dat2 <- missForest(airquality,ntree = 100)
dat2中包含填補好的數據,可利用dat2$ximp查看填補後的值,
head(dat2$ximp) aggr(dat2$ximp)
同時,OOBerror表示袋外填補缺失的誤差估計。
dat2$OOBerror

4.多重插補法
多重插補法是在一個缺失的數據集中生成一個完整的數據集,並利用蒙特卡洛的方法進行填補的一種重復模擬的方法。
包mice中的mice()函數可實現對缺失數據的多重插補,原數據集中Ozone和Solar.R變量存在缺失,采用‘rf’法插補。
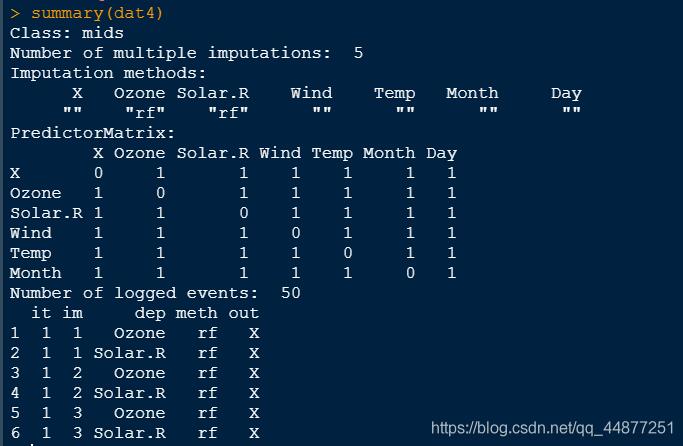
dat3 <- mice(airquality,m=5,method = ‘rf')
其中,m為生成完整數據集的個數,默認為5. method為插補參數的方法,‘norm.predict’、‘pmm’、‘rf’、‘norm’依次為回歸預測法、平均值插補法、隨機森林法和高斯線性回歸法。
summary(dat3)
通過以下代碼可查看填補的值
dat3$ imp$Solar.R
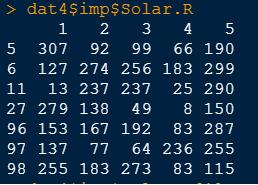
最後選擇某一列(如1,2,3)填充到缺失數據集中即可形成完整的數據集.
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- R語言 出現矩陣/缺失值的解決方案
- R語言初學者的一些常見報錯指南
- R語言數據可視化ggplot添加左右y軸繪制天貓雙十一銷售圖
- R語言處理JSON文件的方法
- Python抓取數據到可視化全流程的實現過程