MYSQL數據庫基礎之Join操作原理
Join使用的是Nested-Loop Join算法,Nested-Loop Join有三種
select * from t1 join t2 on t1.a = t2.a; -- a 100條數據, b 1000條數據
Simple Nested-Loop Join
會遍歷t1全表,t1作為驅動表,t1中的每一條數據都會到t2中做一次全表查詢,該過程會比較100*1000次。
每次在t2中做全表查詢時,全表掃描可就不保證在內存裡瞭,Buffer Pool會淘汰,有可能在磁盤。
Block Nested-Loop Join(MYSQL驅動鏈接沒有使用索引)
會遍歷t1全表,將t1數據加載到join_buffer中,再遍歷t2全表,讓t2的每條數據去匹配join_buffer中t1緩存的數據。
t1全表掃描 = 100次
t2全表掃描 = 1000次
查詢次數 = 1100次
join_buffer中比較 = 100 * 1000次
比較的次數和Simple Nested-Loop Join是一樣的,但是比較的過程會比Simple Nested-Loop Join快很多,性能更好。
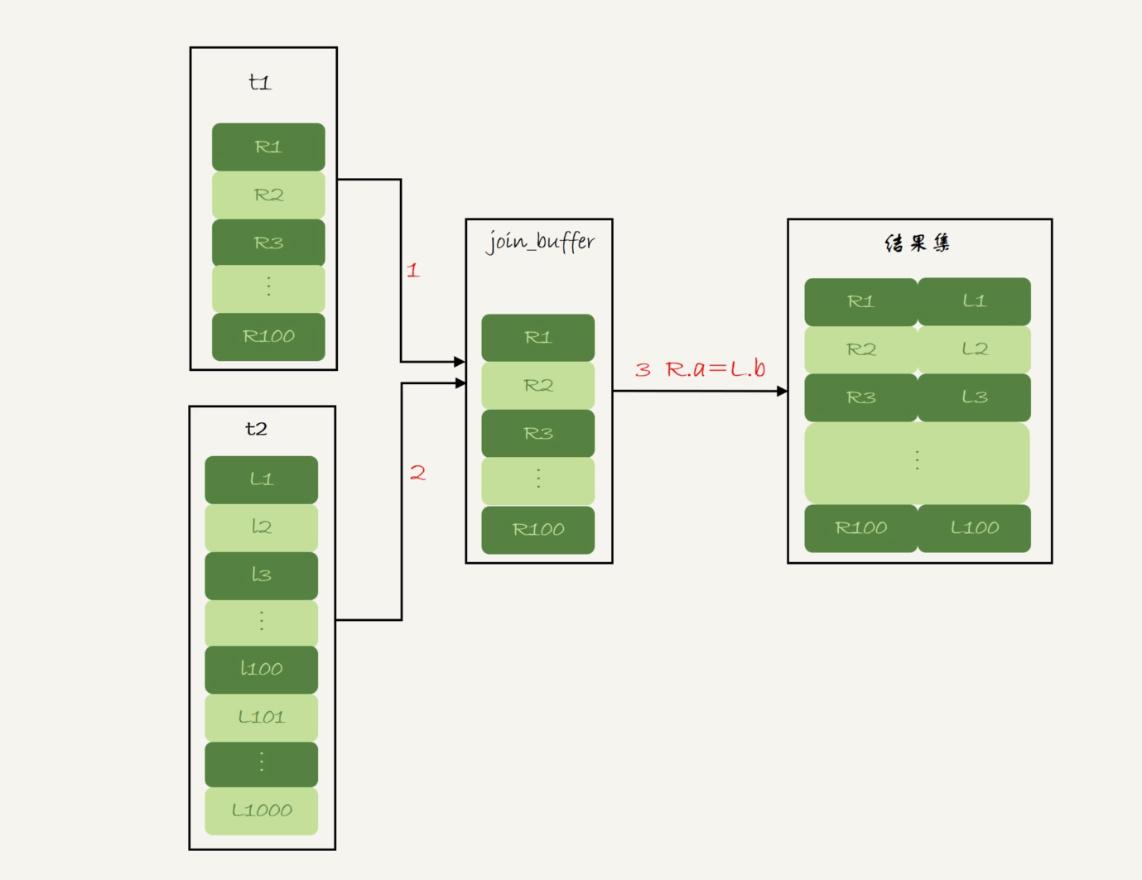
join_buffer是有大小的,如果t1查出來的數據是大於join_buffer大小的,則會先加載部分t1中的數據,比較完t2以後,清空join_buffer,再加載t1中剩餘數據,加載不完全,再重復該操作。
t1全表掃描次數和join_buffer中比較1次數不變,但是t2的掃描次數會根據分段次數做一個乘法。
假設,驅動表的數據行數是 N,需要分 K 段才能完成算法流程,被驅動表的數據行數是 M。
K = λ * N
掃描被驅動表次數 = M * λ * N

λ是和join_buffer的大小有關的,join_buffer大小足夠的情況下,大表驅動和小表驅動的時間是一樣的。
需要分段的情況下,分段次數越少,被驅動表掃描的次數也會越少,所以應該采用小表驅動。
Index Nested-Loop Join(MYSQL驅動鏈接使用索引)
還是以上面的sql為例,如果a字段是有索引的。
t1表會掃描全表,t1表中每條數據會去t2表中做索引查詢,查到id後再進行回表查詢(如果連接字段是t2表的主鍵,回表操作將省略)。
t1掃描全表 = 100次
t2索引查詢 = log1000次
t2回表查詢 = log1000次
假設,驅動表的數據行數是 N,被驅動表的數據行數是 M。
總查詢次數 = N + N * 2logM
由上可見,驅動表數據越大,查詢的次數會越多,所以應該使用小表作為驅動表。

文章參考《MySQL實戰45講–第34講》
總結
到此這篇關於MYSQL數據庫基礎之Join操作原理的文章就介紹到這瞭,更多相關MYSQL Join原理內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- MySQL JOIN關聯查詢的原理及優化
- 為什麼代碼規范要求SQL語句不要過多的join
- 一文教你MySQL如何優化無索引的join
- MySQL中limit對查詢語句性能的影響
- MySQL 用 limit 為什麼會影響性能