MySQL JOIN關聯查詢的原理及優化
1 關聯查詢的執行
關聯查詢的執行過程是:先遍歷關聯表t1(驅動表,全表掃描),然後根據從表t1中取出的每行數據中的a值,去表t2(被關聯表,被驅動表)中查找滿足條件的記錄,可以走t2的索引搜索。在形式上,這個過程就跟我們寫程序時的嵌套查詢類似,並且可以用上被驅動表的索引,所以我們稱之為“Index Nested-Loop Join”,簡稱NLJ。在join語句的執行流程中,驅動表是走全表掃描,而被驅動表是走索引樹搜索。
假設被驅動表的行數是M。每次在被驅動表查一行數據,要先搜索索引a,再搜索主鍵索引。每次搜索一棵樹近似復雜度是以2為底的M的對數,記為log2M,所以在被驅動表上查一行的時間復雜度是 2*log2M。
假設驅動表的行數是N,執行過程就要掃描驅動表N行,然後對於每一行,到被驅動表上匹配一次。
因此整個執行過程,近似復雜度是 N + N2log2M。顯然,N對掃描行數的影響更大,因此應該讓小表來做驅動表:N擴大1000倍的話,掃描行數就會擴大1000倍;而M擴大1000倍,掃描行數擴大不到10倍。
結論:如果使用join語句的話,需要讓小表做驅動表,並且被驅動表的關聯字段應該建立索引。一般來說,除非有其他理由,否則隻需要在關聯順序中的第二個表的相應列上創建索引,即在被驅動的表的關聯字段簡歷索引。
2 沒有索引的算法
如果,被驅動表的關聯字段沒有使用索引,那麼MySQL將使用另一種Block Nested-Loop Join算法。
- 把表t1的數據讀入線程內存join_buffer中,這隻會將查詢需要返回的列放入,如果我們的語句中寫的是select *,就會把整個表t1放入瞭內存;
- 掃描表t2,把表t2中的每一行取出來,跟join_buffer中的數據做對比,滿足join條件的,作為結果集的一部分返回。
這個過程的流程圖如下:
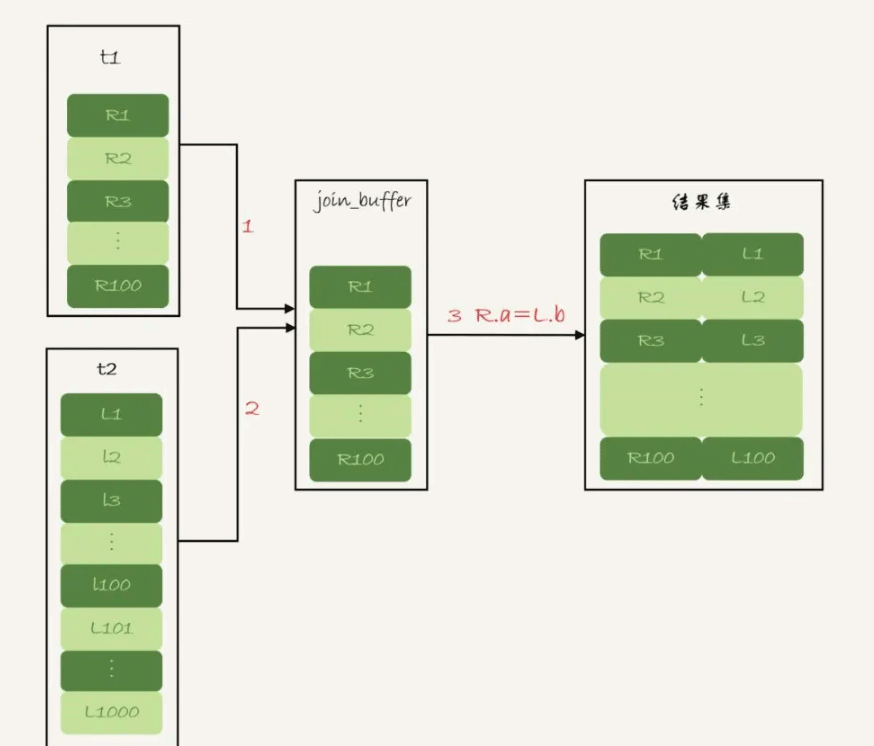
對應地,這條SQL語句的explain結果的Extra字段中將會展示:Block Nested Loop。在這個過程中,對表t1和t2都做瞭一次全表掃描,因此總的掃描行數是量表的數據總和M+N。由於join_buffer是以無序數組的方式組織的,因此對表t2中的每一行,都要做100次判斷,總共需要在內存中做的判斷次數是:M* N次。
假設小表的行數是N,大表的行數是M,那麼在這個算法裡:
- 兩個表都做一次全表掃描,所以總的掃描行數是M+N;
- 內存中的判斷次數是M*N,雖然不需要讀盤,但是需要占用大量CPU進行計算。
可以看到,調換這兩個算式中的M和N沒差別,因此這時候選擇大表還是小表做驅動表,執行耗時是一樣的。
join_buffer的大小是由參數join_buffer_size設定的,默認值是256k。如果放不下表t1的所有數據話,策略很簡單,就是將t1的數據分段放入、比較,假設表t1被分成瞭兩次放入join_buffer中,那麼會導致表t2會被掃描兩次。雖然分成兩次放入join_buffer,但是內存中判斷等值條件的次數還是不變的,依然是M*N次。
假設,驅動表的數據行數是N,需要分K段才能完成算法流程,K大於等於1,被驅動表的數據行數是M。註意,這裡的K不是常數,N越大K就會越大。
所以,在這個算法的執行過程中:
- 掃描行數是 N+K*M;
- 內存判斷 N*M次。
可以看到,如果join_buffer_size沒有足夠大(這是常見的情況),那麼N越小,這樣K就更小,掃描的行數才會更少,因此仍然應該讓小表當驅動表。而且K也是影響掃描行數的關鍵因素,這個值越小越好,如果N不變,那麼影響K的就是join_buffer_size的大小。join_buffer_size越大,一次可以放入的行越多,分成的段數K也就越少,對被驅動表的全表掃描次數就越少。
因此,如果你的join語句很慢,除瞭讓小表當驅動表,還有就把join_buffer_size改大。
如果確定“小表”呢?除瞭總行數之外,還應該是兩個表按照各自的條件過濾,過濾完成之後,再計算參與join的各個字段的總數據量(因為還要放入內存中),數據量小的那個表,就是“小表”,應該作為驅動表。
實際在查詢優化時,如果join不是使用的Index Nested-Loop Join算法,則應該盡量改為使用該算法。
到此這篇關於MySQL JOIN關聯查詢的原理及優化的文章就介紹到這瞭,更多相關MySQL JOIN關聯查詢 內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- MYSQL數據庫基礎之Join操作原理
- 一文教你MySQL如何優化無索引的join
- 為什麼代碼規范要求SQL語句不要過多的join
- MySQL關聯查詢優化實現方法詳解
- MySQL order by與group by查詢優化實現詳解