MySQL 大表的count()優化實現
以下是基於我結合B+樹的數據結構和對實驗結果的推測作出的判斷,如有錯誤,懇請指正!
今天實驗瞭一下MySQL的count()操作優化, 以下討論基於mysql5.7 InnoDB存儲引擎. x86 windows操作系統。
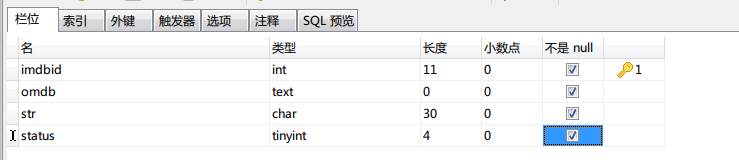
創建的表的結構如下(數據量為100萬):
首先是關於mysql的count(*),count(PK), count(1)哪個快的問題。
實現結果如下:
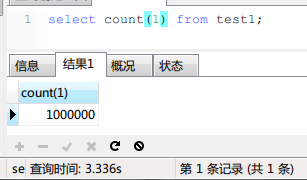
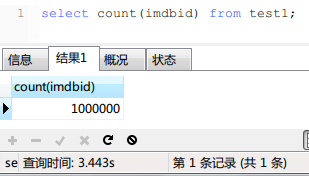
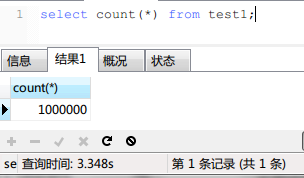
並沒有什麼區別!加上瞭WHERE子句之後3個查詢的時間也是相同的,我就不貼圖片瞭。
之前在公司的時候就寫過一個select count(*) from table的SQL語句,在數據多的時候非常慢。所以要怎麼優化呢?
這要從InnoDB的索引說起, InnoDB的索引是B+Tree。
對主鍵索引來說:它隻有在葉子節點上存儲數據,它的key是主鍵,並且value為整條數據。
對輔助索引來說:key為建索引的列,value為主鍵。
這給我們兩個信息:
1. 根據主鍵會查到整條數據
2. 根據輔助索引隻能查到主鍵,然後必須通過主鍵再查到剩餘信息。
所以如果要優化count(*)操作的話,我們需要找一個短小的列,為它建立輔助索引。
在我的例子中就是status,雖然它的”severelity”幾乎為0.
先建立索引:ALTER TABLE test1 ADD INDEX (status);
然後查詢,如下圖:
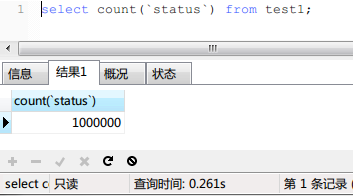
可以看到,查詢時間從3.35s下降到瞭0.26s,查詢速度提升近13倍。
如果索引是str這一列,結果又會是怎麼樣呢?
先建立索引: alter table test1 add index (str)
結果如下:
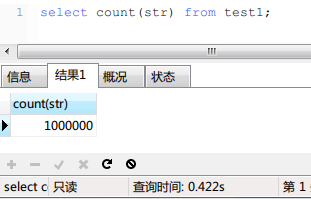
可以看到,時間為0.422s,也很快,但是比起status這列還是有著1.5倍左右的差距。
再大膽一點做個實驗,我把status這列的索引刪掉,建立一個status和left(omdb,200)(這一列平均1000個字符)的聯合索引,然後看查詢時間。
建立索引: alter table test1 add index (status,omdb(200))
結果如下:
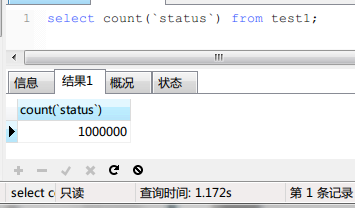
時間為1.172s
alter table test1 add index (status,imdbid);
補充!!
要註意索引失效的情況!
建立瞭索引後正常的的樣子:

可以看到key_len為6, Extra的說明是using index.
而如果索引失效的話:

索引失效有很多種情況,比如使用函數,!=操作等,具體請參考官方文檔。
對MySQL沒有很深的研究,以上是基於我結合B+樹的數據結構和對實驗結果的推測作出的判斷,如有錯誤,懇請指正!
到此這篇關於MySQL 大表的count()優化實現的文章就介紹到這瞭,更多相關MySQL 大表count()優化內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found