Pandas使用stack和pivot實現數據透視的方法
前言
筆者最近正在學習Pandas數據分析,將自己的學習筆記做成一套系列文章。本節主要記錄Pandas中使用stack和pivot實現數據透視。
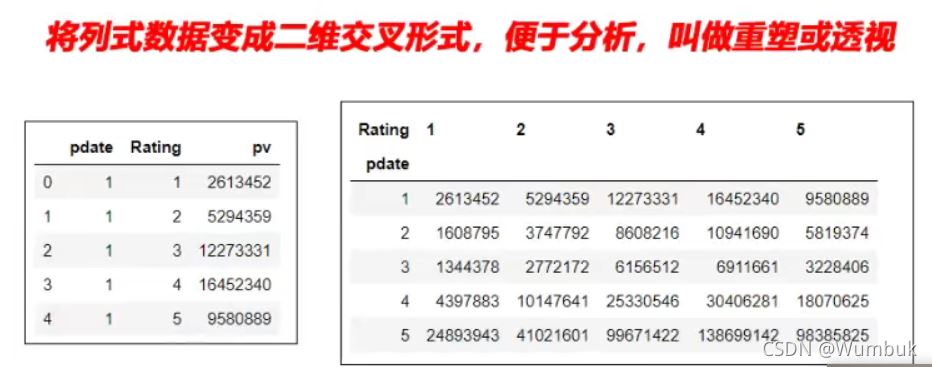
一、經過統計得到多維度指標數據
非常場景的統計場景,指定多個維度,計算聚合後的指標
實例:統計得到“電影評分數據集”,每個月份的每個分數被評分多少次:(月份、分數1-5、次數)
import pandas as pd
import numpy as np
%matplotlib inline
df=pd.read_csv(
"./datas/ml-1m/ratings.dat",
sep="::",
engine='python',
names='UserID::MovieID::Rating::Timestamp'.split("::"),
header=None
)
df.head()
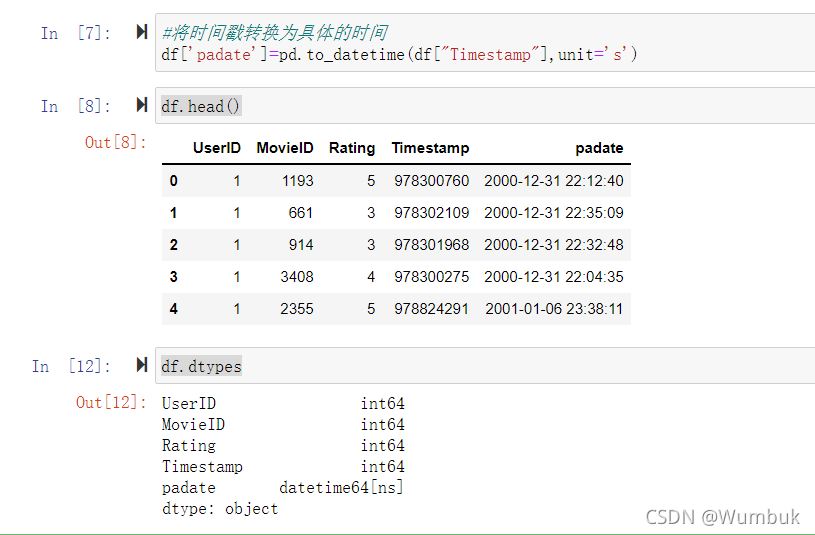
#將時間戳轉換為具體的時間
df['padate']=pd.to_datetime(df["Timestamp"],unit='s')
df.head()
df.dtypes
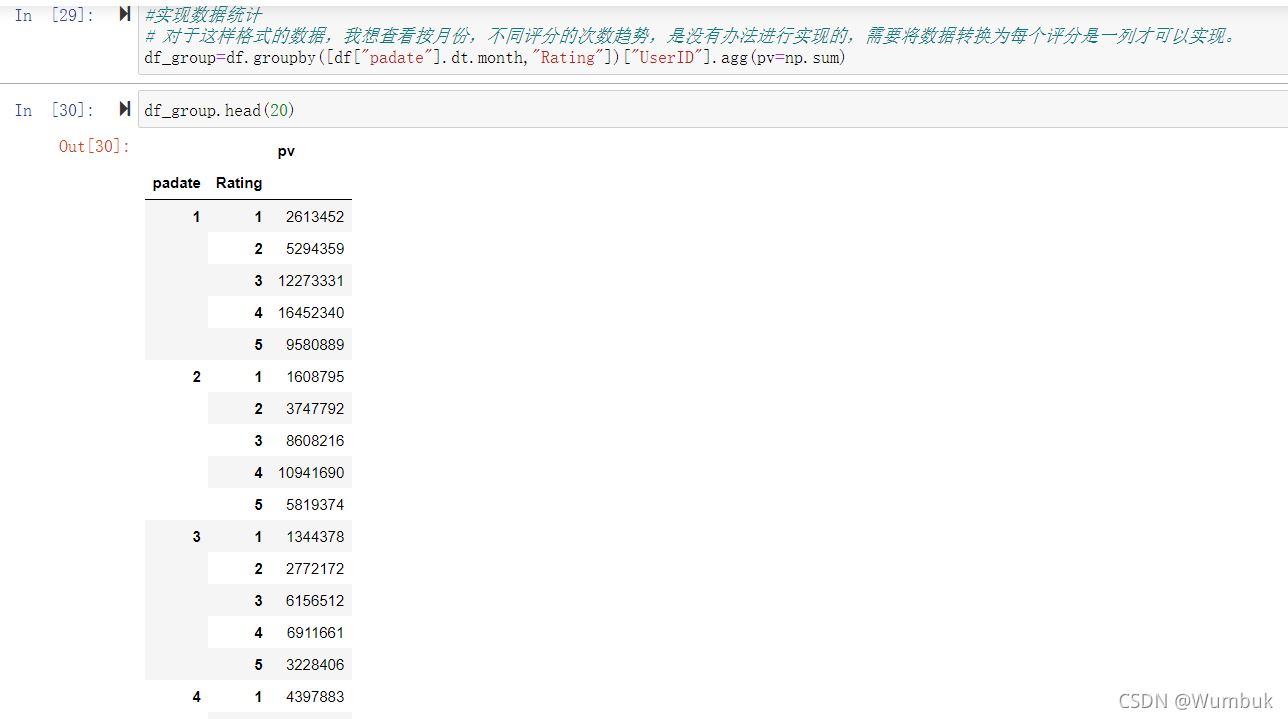
#實現數據統計
# 對於這樣格式的數據,我想查看按月份,不同評分的次數趨勢,是沒有辦法進行實現的,需要將數據轉換為每個評分是一列才可以實現。
df_group=df.groupby([df["padate"].dt.month,"Rating"])["UserID"].agg(pv=np.sum)
df_group.head(20)

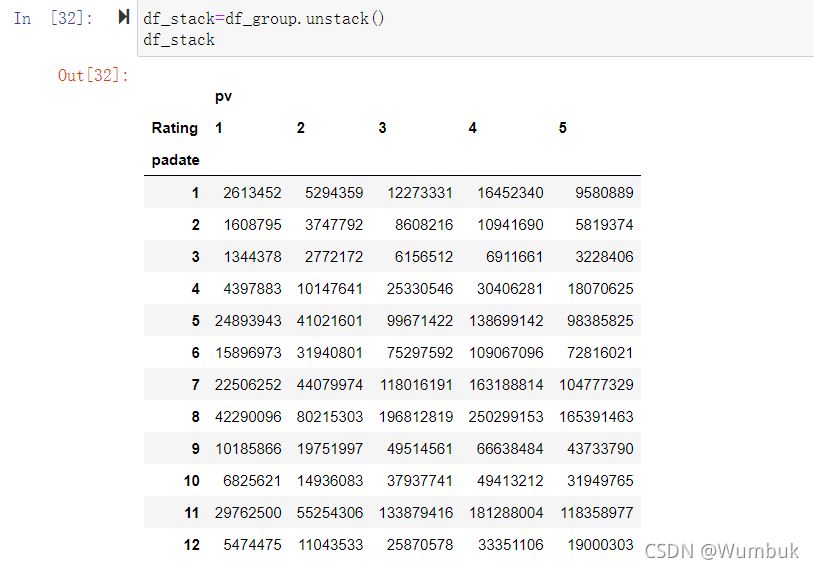
二、使用unstack實現數據的二維透視
目的: 想要畫圖對比按照月份的不同評分的數量趨勢
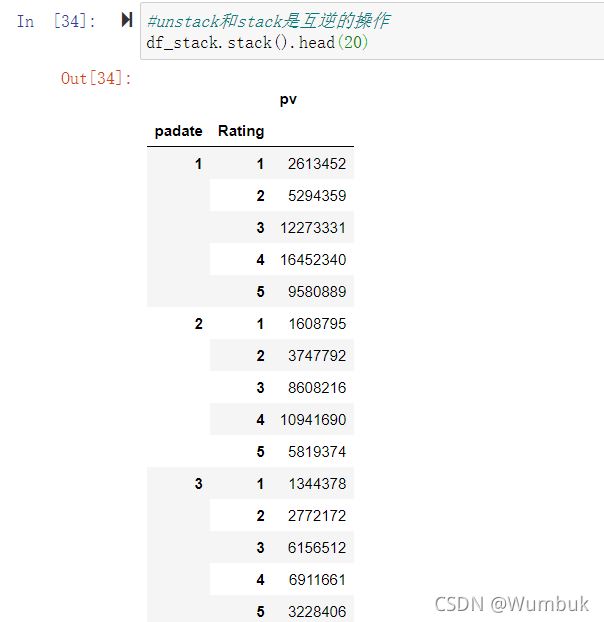
df_stack=df_group.unstack() df_stack df_stack.plot() #unstack和stack是互逆的操作 df_stack.stack().head(20)

三、使用pivot簡化透視
pivot方法相當於對df使用set_index創建分層索引,然後調用unstack
df_group.head(20)
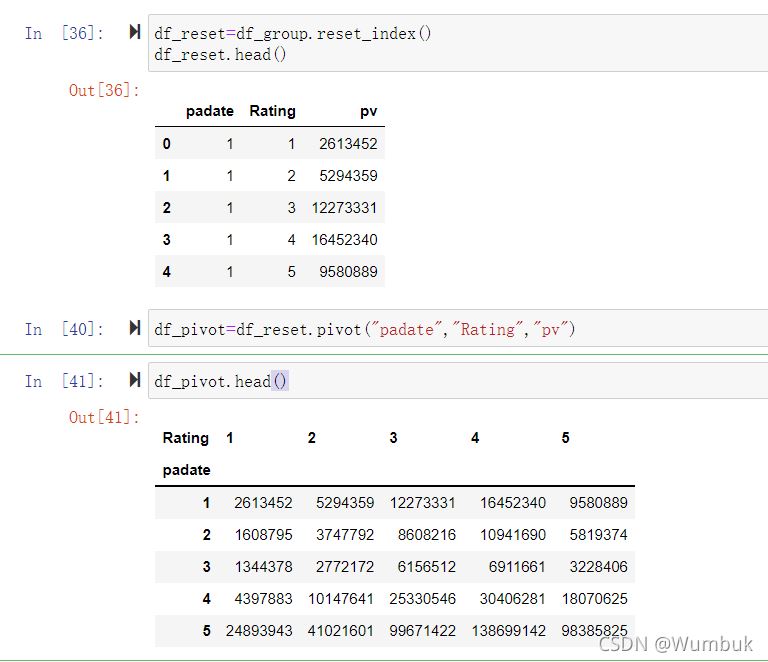
df_reset=df_group.reset_index()
df_reset.head()
df_pivot=df_reset.pivot("padate","Rating","pv")
df_pivot.head()
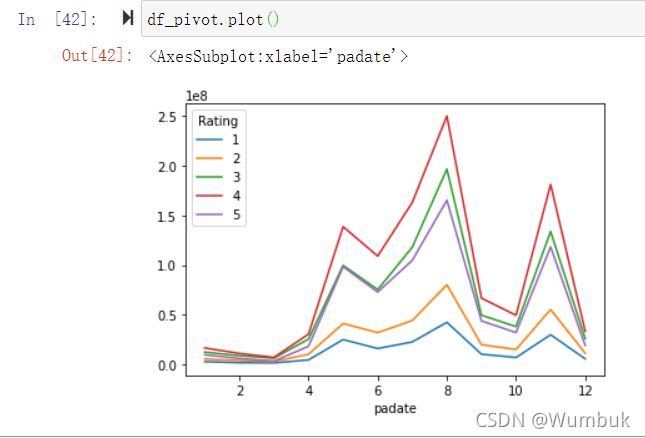
df_pivot.plot()

四、stack、unstack、pivot的語法
1.stack
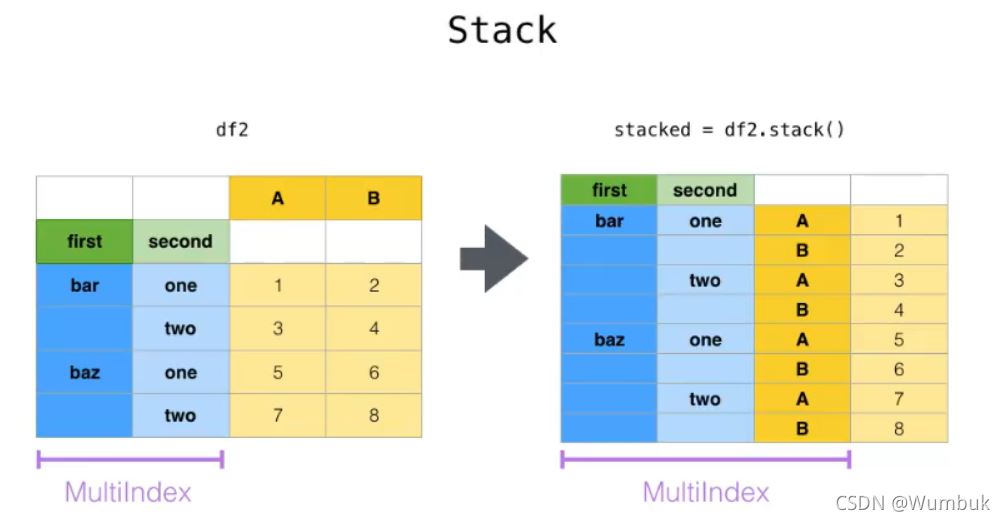
stack:DataFrame.stack(level=-1,dropna=True),將column變成index,類似把橫放的書籍變成豎放
level=-1代表多層索引的最內層,可以通過==0,1,2指定多層索引的對應層
2.unstack
unstack:DataFrame.unstack(level=-1,fill_value=None),將index變成column,類似把豎放的書變成橫放

3.pivot
pivot:DataFrame.pivot(index=None,columns=None,values=None),指定index,columns,values實現二維透視

總結
到此這篇關於Pandas使用stack和pivot實現數據透視的方法的文章就介紹到這瞭,更多相關Pandas stack和pivot數據透視內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python pandas軸旋轉stack和unstack的使用說明
- python中pivot()函數基礎知識點
- Pandas實現Dataframe的重排和旋轉
- pandas groupby + unstack的使用說明
- 一文搞懂Pandas數據透視的4個函數的使用