MySQL中的回表和索引覆蓋示例詳解
索引類型
聚簇索引: 葉子節點存儲的是行記錄,每個表必須要有至少一個聚簇索引。使用聚簇索引查詢會很快,因為可以直接定位到行記錄
普通索引:二級索引,除聚簇索引外的索引,即非聚簇索引。普通索引葉子節點存儲的是主鍵(聚簇索引)的值。
聚簇索引遞推規則:
- 如果表設置瞭主鍵,則主鍵就是聚簇索引
- 如果表沒有主鍵,則會默認第一個NOT NULL,且唯一(UNIQUE)的列作為聚簇索引
- 以上都沒有,則會默認創建一個隱藏的row_id作為聚簇索引
索引結構
id 是主鍵,所以是聚簇索引,其葉子節點存儲的是對應行記錄的數據
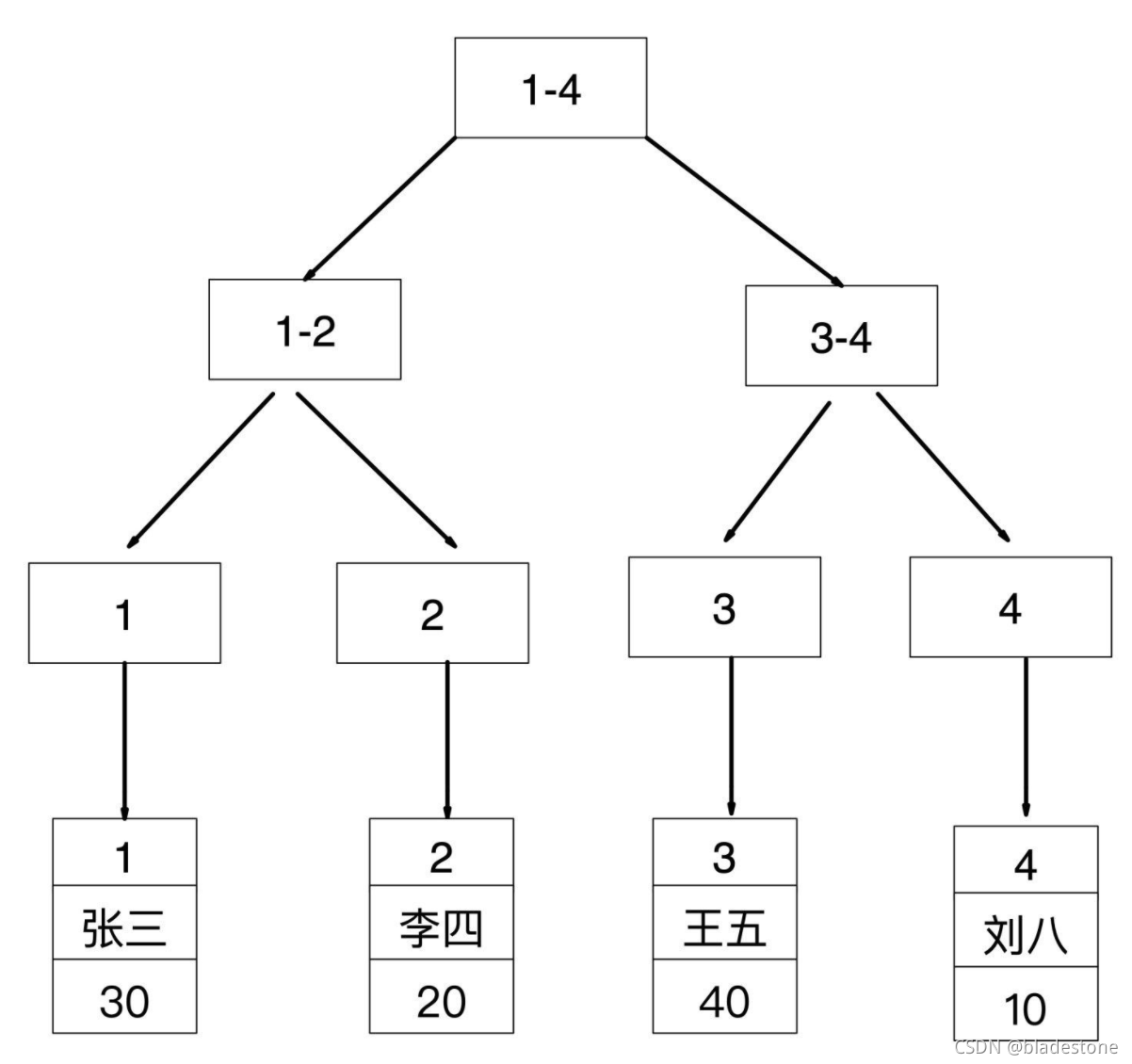
非聚簇索引(Non-ClusteredIndex)

聚簇索引查詢
如果查詢條件為主鍵(聚簇索引),則隻需掃描一次B+樹即可通過聚簇索引定位到要查找的行記錄數據。
如:select * from user where id = 1;
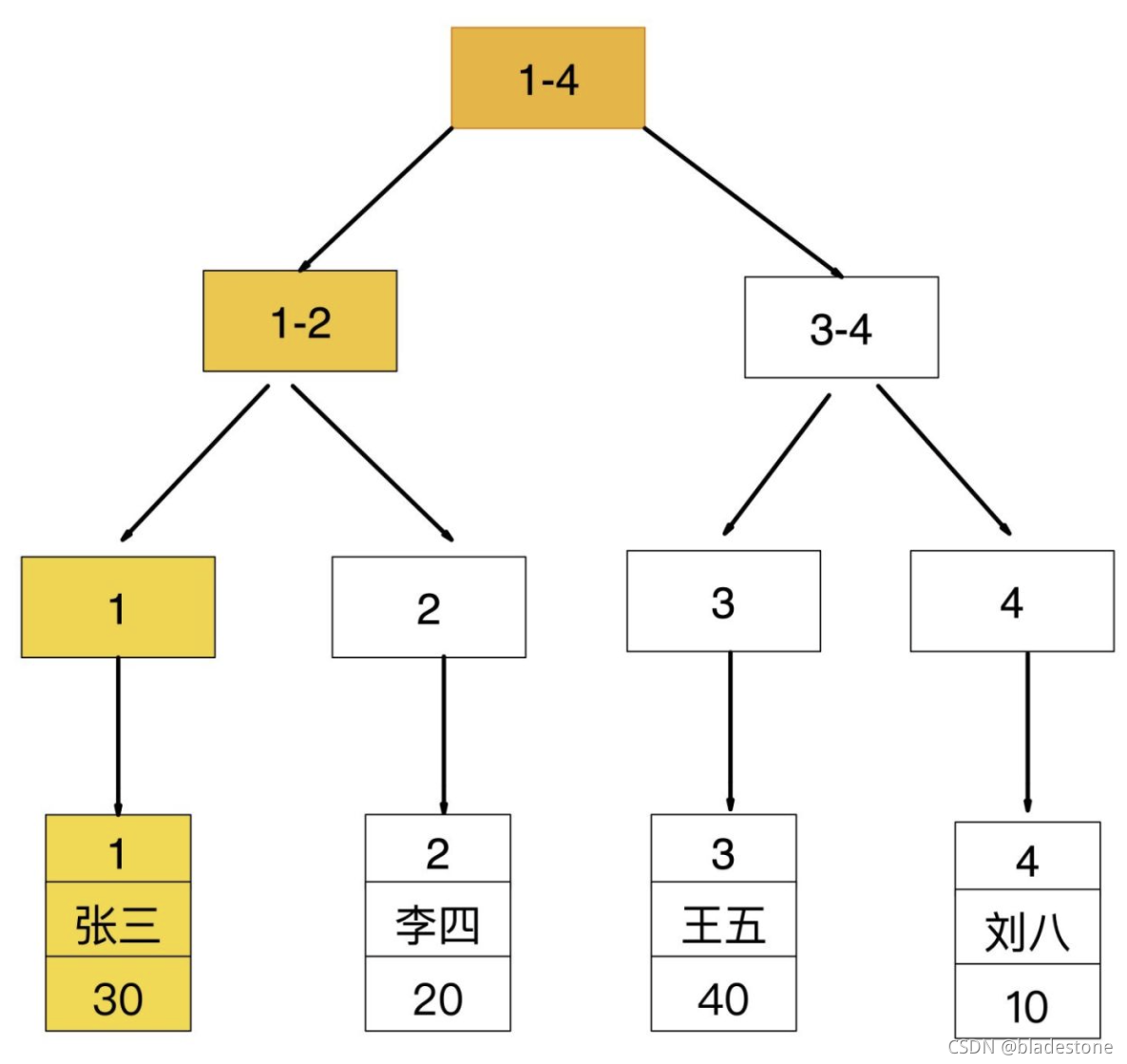
非聚簇索引查詢
如果查詢條件為普通索引(非聚簇索引),需要掃描兩次B+樹,第一次掃描通過普通索引定位到聚簇索引的值,然後第二次掃描通過聚簇索引的值定位到要查找的行記錄數據。
如:select * from user where age = 30;
1. 先通過普通索引 age=30 定位到主鍵值 id=1
2. 再通過聚集索引 id=1 定位到行記錄數據

先通過普通索引的值定位聚簇索引值,再通過聚簇索引的值定位行記錄數據,需要掃描兩次索引B+樹,它的性能較掃一遍索引樹更低。
索引覆蓋
隻需要在一棵索引樹上就能獲取SQL所需的所有列數據,無需回表,速度更快。
例如:select id,age from user where age = 10;

使用id,age,name查詢:
select id,age,name, salary from user where age = 10;
explain分析:age是普通索引,但name列不在索引樹上,所以通過age索引在查詢到id和age的值後,需要進行回表再查詢name的值。此時的Extra列的Using where表示進行瞭回表查詢
Type: all, 表示全表掃描

增加表的聯合索引:CREATE INDEX idx_user_name_age_salary ON mydb.user (name, age, salary);
explain分析:此時字段age和name是組合索引idx_age_name,查詢的字段id、age、name的值剛剛都在索引樹上,隻需掃描一次組合索引B+樹即可,這就是實現瞭索引覆蓋,此時的Extra字段為Using index表示使用瞭索引覆蓋。

分頁查詢(非利用索引):

添加索引之後,即可實現利用索引快速查找。
總結
到此這篇關於MySQL中回表和索引覆蓋的文章就介紹到這瞭,更多相關MySQL回表和索引覆蓋內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!