如何使用python爬取知乎熱榜Top50數據
1、導入第三方庫
import urllib.request,urllib.error #請求網頁 from bs4 import BeautifulSoup # 解析數據 import sqlite3 # 導入數據庫 import re # 正則表達式 import time # 獲取當前時間
2、程序的主函數
def main():
# 聲明爬取網頁
baseurl = "https://www.zhihu.com/hot"
# 爬取網頁
datalist = getData(baseurl)
#保存數據
dbname = time.strftime("%Y-%m-%d", time.localtime()) #
dbpath = "zhihuTop50 " + dbname
saveData(datalist,dbpath)
3、正則表達式匹配數據
#正則表達式 findlink = re.compile(r'<a class="css-hi1lih" href="(.*?)" rel="external nofollow" rel="external nofollow" ') #問題鏈接 findid = re.compile(r'<div class="css-blkmyu">(.*?)</div>') #問題排名 findtitle = re.compile(r'<h1 class="css-3yucnr">(.*?)</h1>') #問題標題 findintroduce = re.compile(r'<div class="css-1o6sw4j">(.*?)</div>') #簡要介紹 findscore = re.compile(r'<div class="css-1iqwfle">(.*?)</div>') #熱門評分 findimg = re.compile(r'<img class="css-uw6cz9" src="(.*?)"/>') #文章配圖
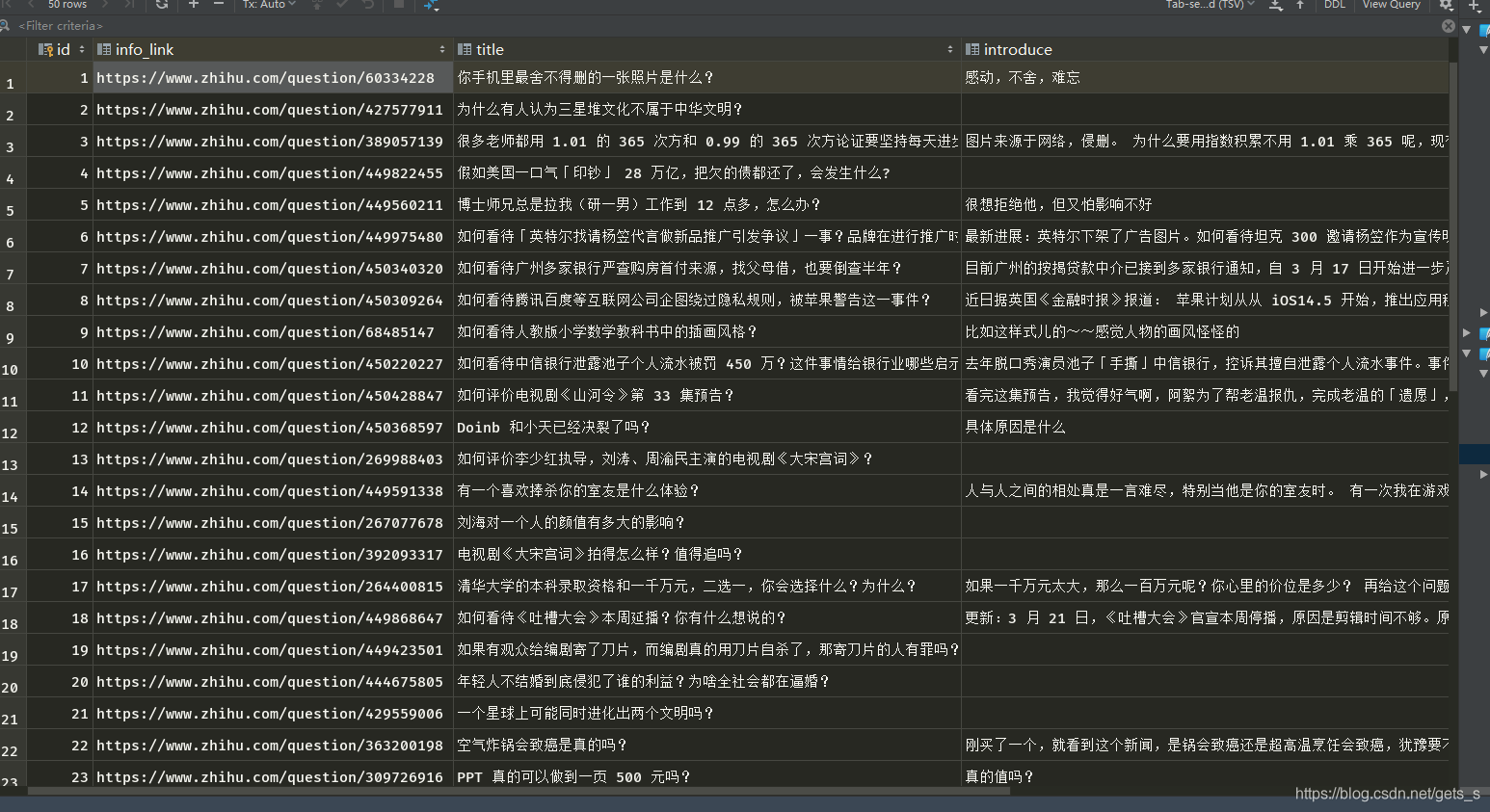
4、程序運行結果
5、程序源代碼
import urllib.request,urllib.error
from bs4 import BeautifulSoup
import sqlite3
import re
import time
def main():
# 聲明爬取網頁
baseurl = "https://www.zhihu.com/hot"
# 爬取網頁
datalist = getData(baseurl)
#保存數據
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "zhihuTop50 " + dbname
saveData(datalist,dbpath)
print()
#正則表達式
findlink = re.compile(r'<a class="css-hi1lih" href="(.*?)" rel="external nofollow" rel="external nofollow" ') #問題鏈接
findid = re.compile(r'<div class="css-blkmyu">(.*?)</div>') #問題排名
findtitle = re.compile(r'<h1 class="css-3yucnr">(.*?)</h1>') #問題標題
findintroduce = re.compile(r'<div class="css-1o6sw4j">(.*?)</div>') #簡要介紹
findscore = re.compile(r'<div class="css-1iqwfle">(.*?)</div>') #熱門評分
findimg = re.compile(r'<img class="css-uw6cz9" src="(.*?)"/>') #文章配圖
def getData(baseurl):
datalist = []
html = askURL(baseurl)
# print(html)
soup = BeautifulSoup(html,'html.parser')
for item in soup.find_all('a',class_="css-hi1lih"):
# print(item)
data = []
item = str(item)
Id = re.findall(findid,item)
if(len(Id) == 0):
Id = re.findall(r'<div class="css-mm8qdi">(.*?)</div>',item)[0]
else: Id = Id[0]
data.append(Id)
# print(Id)
Link = re.findall(findlink,item)[0]
data.append(Link)
# print(Link)
Title = re.findall(findtitle,item)[0]
data.append(Title)
# print(Title)
Introduce = re.findall(findintroduce,item)
if(len(Introduce) == 0):
Introduce = " "
else:Introduce = Introduce[0]
data.append(Introduce)
# print(Introduce)
Score = re.findall(findscore,item)[0]
data.append(Score)
# print(Score)
Img = re.findall(findimg,item)
if (len(Img) == 0):
Img = " "
else: Img = Img[0]
data.append(Img)
# print(Img)
datalist.append(data)
return datalist
def askURL(baseurl):
# 設置請求頭
head = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
"User-Agent": "Mozilla / 5.0(iPhone;CPUiPhoneOS13_2_3likeMacOSX) AppleWebKit / 605.1.15(KHTML, likeGecko) Version / 13.0.3Mobile / 15E148Safari / 604.1"
}
request = urllib.request.Request(baseurl, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
print()
def saveData(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
sql = '''
insert into Top50(
id,info_link,title,introduce,score,img)
values("%s","%s","%s","%s","%s","%s")'''%(data[0],data[1],data[2],data[3],data[4],data[5])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = '''
create table Top50
(
id integer primary key autoincrement,
info_link text,
title text,
introduce text,
score text,
img text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ =="__main__":
main()
到此這篇關於如何使用python爬取知乎熱榜Top50數據的文章就介紹到這瞭,更多相關python 爬取知乎內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 如何使用python爬取B站排行榜Top100的視頻數據
- 用Python實現爬取百度熱搜信息
- Python自動爬取圖片並保存實例代碼
- Python 批量下載陰陽師網站壁紙
- Python進階篇之正則表達式常用語法總結