MySQL必備基礎之分組函數 聚合函數 分組查詢詳解
一、簡單使用
SUM:求和(一般用於處理數值型)
AVG:平均(一般用於處理數值型)
MAX:最大(也可以用於處理字符串和日期)
MIN:最小(也可以用於處理字符串和日期)
COUNT:數量(統計非空值的數據個數)
以上分組函數都忽略空NULL值的數據
SELECT SUM(salary) AS 和,AVG(salary) AS 平均,MAX(salary) AS 最大,MIN(salary) AS 最小,COUNT(salary) AS 數量 FROM employees;

二、搭配DISTINCT去重
(以上函數均可)
SELECT SUM(DISTINCT salary) AS 和,AVG(DISTINCT salary) AS 平均,COUNT( DISTINCT salary) AS 去重數量,COUNT(salary) AS 不去重數量 FROM employees;

三、COUNT()詳細介紹
#相當於統計行數方式一 SELECT COUNT(*) FROM employees;
#相當於統計行數方式二,其中1可以用其他常量或字段替換 SELECT COUNT(1) FROM employees;
效率問題:
MYISAM存儲引擎下,COUNT(*)的效率高
INNODB存儲引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)高
因此一般用COUNT(*)統計行數
四、分組查詢
#其中[]內為可選 SELECT 分組函數,列表(要求出現在 GROUP BY 的後面) FROM 表 [WHERE 篩選條件] GROUP BY 分組列表 [ORDER BY 子句]
示例:
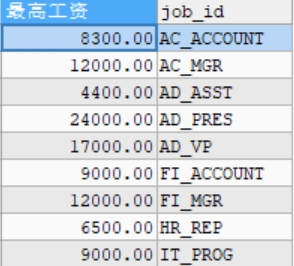
#查詢每個工種的最高工資 SELECT MAX(salary) AS 最高工資,job_id FROM employees GROUP BY job_id;
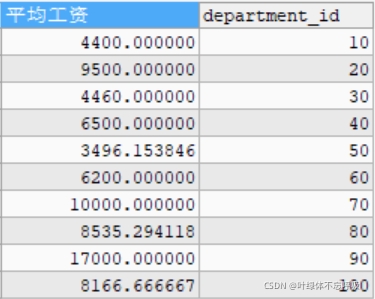
#查詢每個部門中,郵箱包含a的員工的平均工資(分組前的篩選) SELECT AVG(salary) AS 平均工資,department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id;
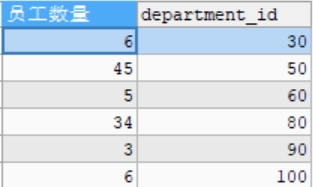
#查詢部門員工數量大於2的部門的員工數量(分組後的篩選) #使用HAVING SELECT COUNT(*) AS 員工數量,department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2;
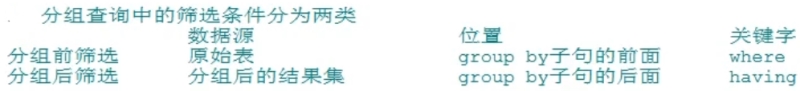
#按照多字段 SELECT COUNT(*) AS 員工數量,job_id,department_id FROM employees GROUP BY job_id,department_id;

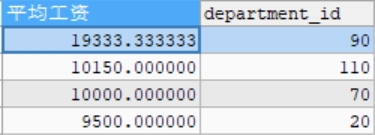
#完整結構 SELECT AVG(salary) AS 平均工資,department_id FROM employees WHERE department_id IS NOT NULL GROUP BY department_id HAVING AVG(salary)>9000 ORDER BY AVG(salary) DESC;
到此這篇關於MySQL必備基礎之分組函數 聚合函數 分組查詢詳解的文章就介紹到這瞭,更多相關MySQL 分組函數 內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- SQL實現LeetCode(185.系裡前三高薪水)
- MySQL如何對數據進行排序圖文詳解
- mysql查詢優化之100萬條數據的一張表優化方案
- MySQL子查詢的使用詳解上篇
- MySQL多表查詢的案例詳解