Python實現數據透視表詳解
用Python裡的Pandas可以實現,雖然感覺Excel更方便
1.groupby + agg
不夠直觀,不好看
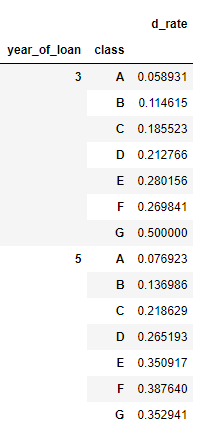
對貸款年份,貸款種類創建數據透視
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))
2. crosstab
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
主要用到的參數:
index:選哪個變量做數據透視表的行
columns:選哪個變量做數據透視表的列
values:要聚合的值
aggfunc:使用的聚合函數
margins:是否添加匯總列/行
margins_name:匯總行/列的名字
例子
對貸款年份,貸款種類創建數據透視
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = '合計')

可以直接看出交叉組合之後違約比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')

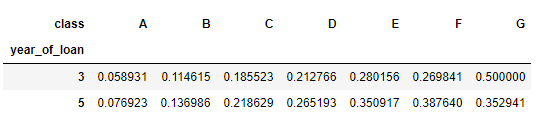
3.groupby + pivot
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')
pivot_table
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
常用參數與crosstab一致
例子
實現同樣的數據透視表
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)

pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')

總結
本篇文章就到這裡瞭,希望能夠給你帶來幫助,也希望您能夠多多關註WalkonNet的更多內容!
推薦閱讀:
- Python+Pandas實現數據透視表
- 一文搞懂Python中pandas透視表pivot_table功能
- python 用pandas實現數據透視表功能
- 一文搞懂Pandas數據透視的4個函數的使用
- Python Pandas模塊實現數據的統計分析的方法