pandas 讀取excel文件的操作代碼
一 read_excel() 的基本用法
import pandas as pd file_name = 'xxx.xlsx' pd.read_excel(file_name)
二 read_excel() 的常用的參數:
io: excel路徑 可以是文件路徑, 類文件對象, 文件路徑對象等。
sheet_name=0: 訪問指定excel某張工作表。sheet_name可以是str, int, list 或 None類型, 默認值是0。
str類型 是直接指定工作表的名稱
int類型 是指定從0開始的工作表的索引, 所以sheelt_name默認值是0,即第一個工作表。
list類型 是多個索引或工作表名構成的list,指定多個工作表。
None類型, 訪問所有的工作表
sheet_name=0: 得到的是第1個sheet的DataFrame類型的數據
sheet_name=2: 得到的是第3個sheet的DataFrame類型的數據
sheet_name=‘Test1′: 得到的是名為’Test1’的sheet的DataFrame類型的數據
sheet_name=[0, 3, ‘Test5′]: 得到的是第1個,第4個和名為Test5 的工作表作為DataFrame類型的數據的字典。
header=0:header是標題行,通過指定具體的行索引,將該行作為數據的標題行,也就是整個數據的列名。默認首行數據(0-index)作為標題行,如果傳入的是一個整數列表,那這些行將組合成一個多級列索引。沒有標題行使用header=None。
name=None: 傳入一列類數組類型的數據,用來作為數據的列名。如果文件數據不包含標題行,要顯式的指出header=None。
skiprows:int類型, 類列表類型或可調函數。 要跳過的行號(0索引)或文件開頭要跳過的行數(int)。如果可調用,可調用函數將根據行索引進行計算,如果應該跳過行則返回True,否則返回False。一個有效的可調用參數的例子是lambda x: x in [0, 1, 2]。
skipfooter=0: int類型, 默認0。自下而上,從尾部指定跳過行數的數據。
usecols=None: 指定要使用的列,如果沒有默認解析所有的列。
index_col=None: int或元素都是int的列表, 將某列的數據作為DataFrame的行標簽,如果傳遞瞭一個列表,這些列將被組合成一個多索引,如果使用usecols選擇的子集,index_col將基於該子集。
squeeze=False, 佈爾值,默認False。 如果解析的數據隻有一列,返回一個Series。
dtype=None: 指定某列的數據類型,可以使類型名或一個對應列名與類型的字典,例 {‘A': np.int64, ‘B': str}
nrows=None: int類型,默認None。 隻解析指定行數的數據。
三 示例
如圖是演示使用的excel文件,它包含5張工作表。
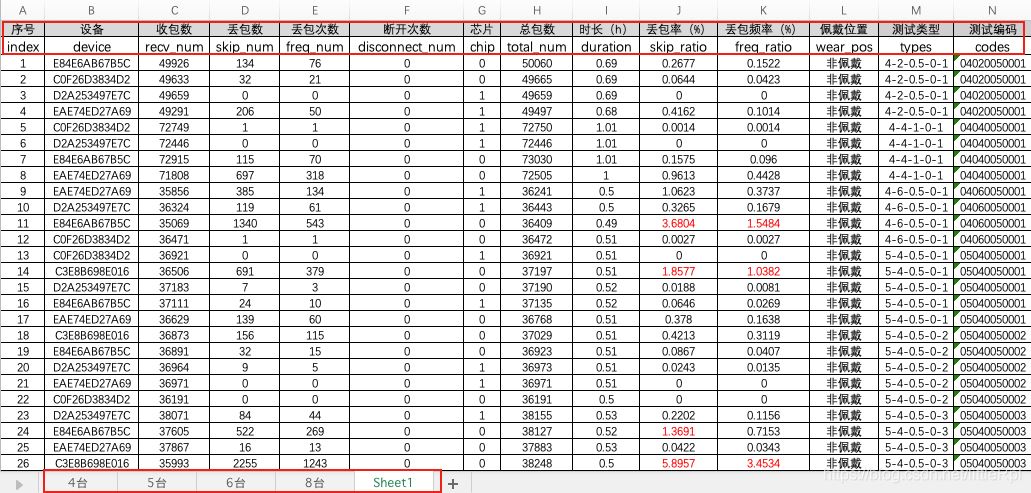
1. IO:路徑
舉一個IO為文件對象的例子, 有些時候file文件路徑的包含較復雜的中文字符串時,pandas 可能會解析文件路徑失敗,可以使用文件對象來解決。
file = 'xxxx.xlsx'
f = open(file, 'rb')
df = pd.read_excel(f, sheet_name='Sheet1')
f.close() # 沒有使用with的話,記得要手動釋放。
# ------------- with模式 -------------------
with open(file, 'rb') as f:
df = pd.read_excel(f, sheet_name='Sheet1')
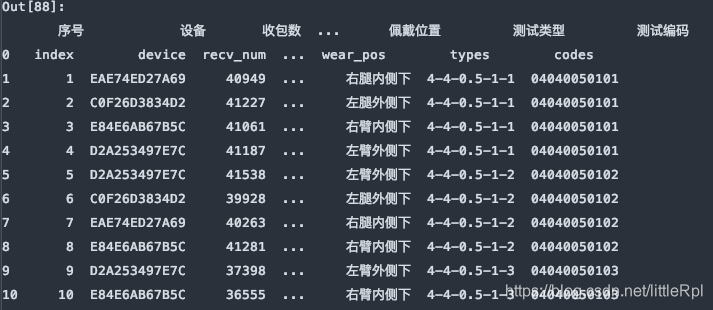
2. sheet_name:指定工作表名
sheet_name=‘Sheet’, 指定解析名為”Sheet1″的工作表。返回一個DataFrame類型的數據。
df = pd.read_excel(file, sheet_name='Sheet1')
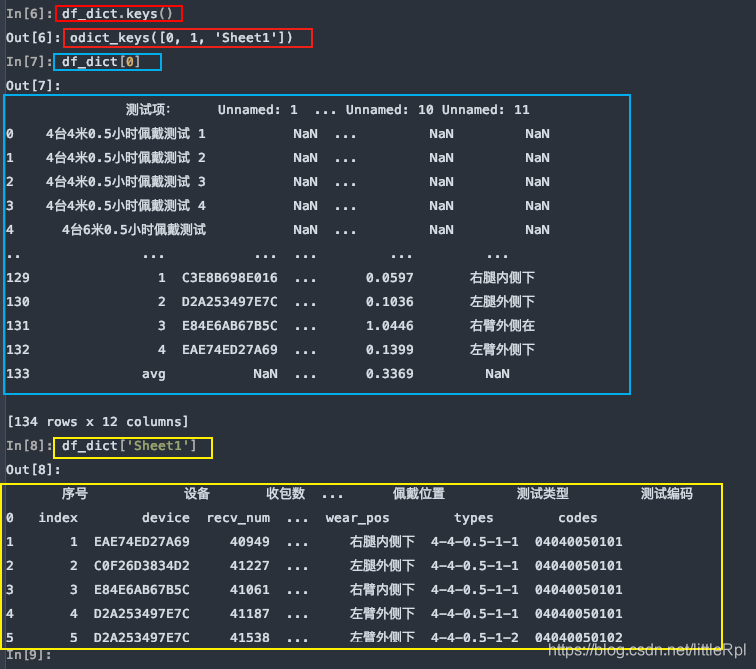
sheet_name=[0, 1, ‘Sheet1′], 對應的是解析文件的第1, 2張工作表和名為”Sheet1″的工作表。它返回的是一個有序字典。結構為{name:DataFrame}這種類型。
df_dict = pd.read_excel(file, sheet_name=[0,1,'Sheet1'])
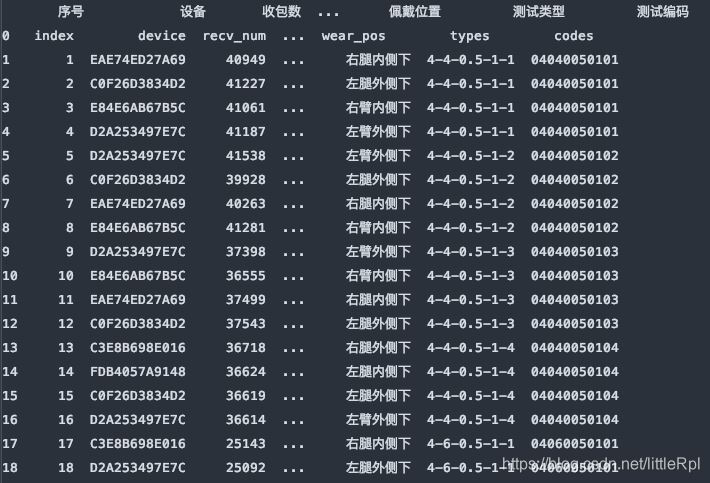
sheet_name=None 會解析該文件中所有的工作表,返回一個同上的字典類型的數據。
df_dict = pd.read_excel(file, sheet_name=None)

3. header :指定標題行
header是用來指定數據的標題行,也就是數據的列名的。本文使用的示例文件具有中英文兩行列名,默認header=0是使用第一行數據作為數據的列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1')
header=1, 使用指定使用第二行的英文列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=1)
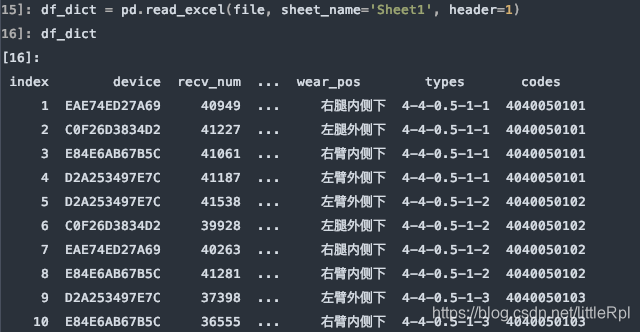
需要註意的是,如果不行指定任何行作為列名,或數據源是無標題行的數據,可以顯示的指定header=None來表明不使用列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=None)

4. names: 指定列名
指定數據的列名,如果數據已經有列名瞭,會替換掉原有的列名。
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'))
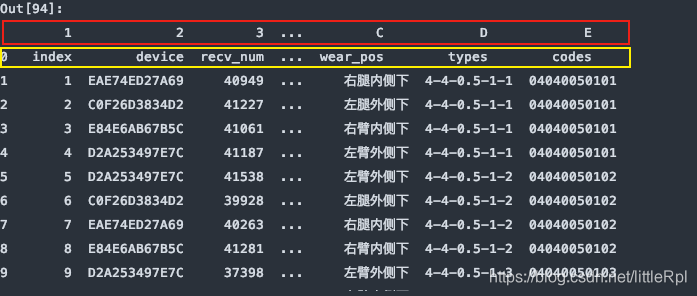
上圖是header=0默認第一行中文名是標題行,最後被names給替換瞭列名,如果隻想使用names,而又對源數據不做任何修改,我們可以指定header=None
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'), header=None)
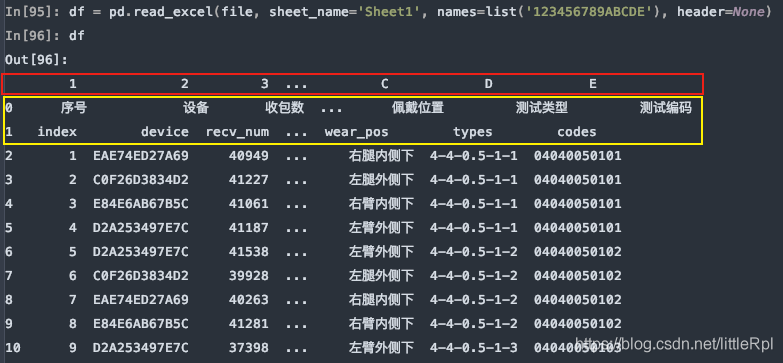
5. index_col: 指定列索引
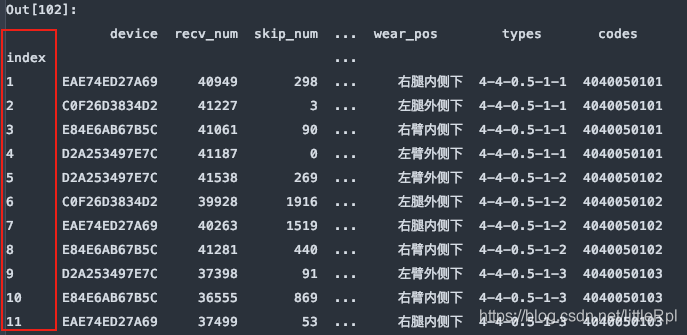
df = pd.read_excel(file, sheet_name='Sheet1', header=1, index_col=0)
6. skiprows:跳過指定行數的數據
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=0)
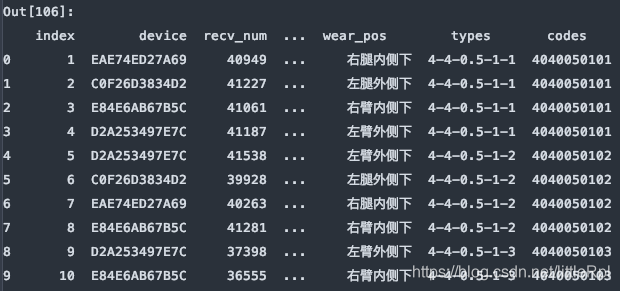
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=[1,3,5,7,9,])
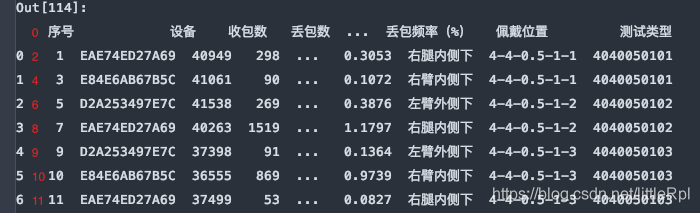
header與skiprows在有些時候效果相同,例skiprows=5和header=5。因為跳過5行後就是以第六行,也就是索引為5的行默認為標題行瞭。需要註意的是skiprows=5的5是行數,header=5的5是索引為5的行。
df = pd.read_excel(file, sheet_name='Sheet1', header=5)
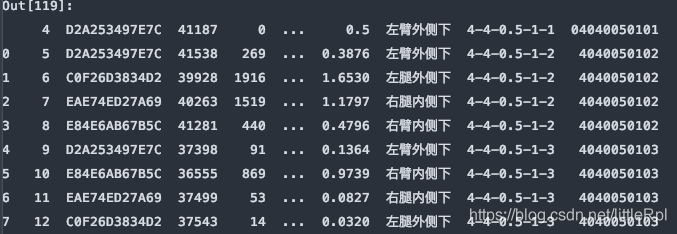
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=5)
7. skipfooter:省略從尾部的行數據
原始的數據有47行,如下圖所示:
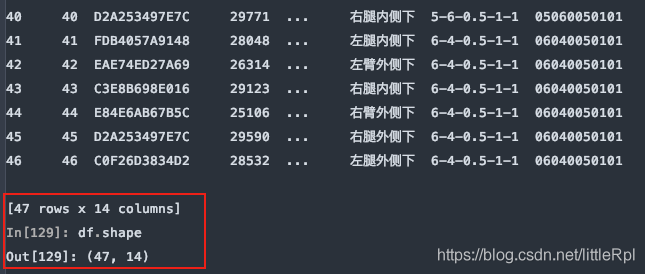
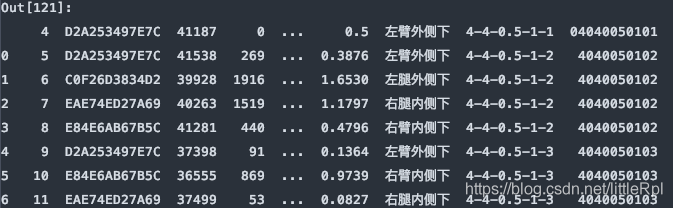
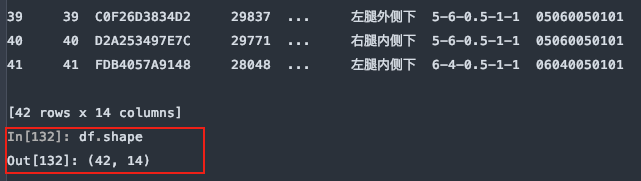
從尾部跳過5行:
df = pd.read_excel(file, sheet_name='Sheet1', skipfooter=5)
8.dtype 指定某些列的數據類型
示例數據中,測試編碼數據是文本,而pandas在解析的時候自動轉換成瞭int64類型,這樣codes列的首位0就會消失,造成數據錯誤,如下圖所示
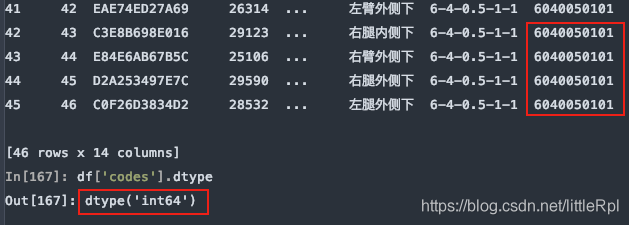
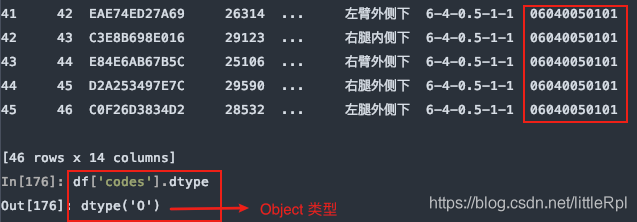
指定codes列的數據類型:
df = pd.read_excel(file, sheet_name='Sheet1', header=1, dtype={'codes': str})
到此這篇關於pandas 讀取excel文件的文章就介紹到這瞭,更多相關pandas 讀取excel文件內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python Pandas讀取csv/tsv文件(read_csv,read_table)的區別
- python使用pandas讀寫excel文件的方法實例
- python pandas合並Sheet,處理列亂序和出現Unnamed列的解決
- pandas pd.read_csv()函數中parse_dates()參數的用法說明
- python pandas處理excel表格數據的常用方法總結