python實現精準搜索並提取網頁核心內容

文 | 李曉飛
來源:Python 技術「ID: pythonall」
爬蟲程序想必大傢都很熟悉瞭,隨便寫一個就可以獲取網頁上的信息,甚至可以通過請求自動生成 Python 腳本[1]。
最近我遇到一個爬蟲項目,需要爬取網上的文章。感覺沒有什麼特別的,但問題是沒有限定爬取范圍,意味著沒有明確的頁面的結構。
對於一個頁面來說,除瞭核心文章內容外,還有頭部,尾部,左右列表欄等等。有的頁面框架用 div 佈局,有的用 table,即使都用 div,不太的網站風格和佈局也不同。
但問題必須解決,我想,既然搜索引擎抓取到各種網頁的核心內容,我們也應該可以搞定,拎起 Python, 說幹就幹!
各種嘗試
如何解決呢?
生成PDF
開始想瞭一個取巧的方法,就是利用工具(wkhtmltopdf[2])將目標網頁生成 PDF 文件。
好處是不必關心頁面的具體形式,就像給頁面拍瞭一張照片,文章結構是完整的。
雖然 PDF 是可以源碼級檢索,但是,生成 PDF 有諸多缺點:
耗費計算資源多、效率低、出錯率高,體積太大。
幾萬條數據已經兩百多G,如果數據量上來光存儲就是很大的問題。
提取文章內容
不生成PDF,有簡單辦法就是通過 xpath[3] 提取頁面上的所有文字。
但是內容將失去結構,可讀性差。更要命的是,網頁上有很多無關內容,比如側邊欄,廣告,相關鏈接等,也會被提取下來,影響內容的精確性。
為瞭保證有一定的結構,還要識別到核心內容,就隻能識別並提取文章部分的結構瞭。像搜索引擎學習,就是想辦法識別頁面的核心內容。
我們知道,通常情況下,頁面上的核心內容(如文章部分)文字比較集中,可以從這個地方著手分析。
於是編寫瞭一段代碼,我是用 Scrapy[4] 作為爬蟲框架的,這裡隻截取瞭其中提取文章部分的代碼 :
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
response是頁面的一個響應,其中包含瞭頁面的所有內容,可以通過xpath提取想要的部分"body//div"的意思是提取所以body標簽下的div子標簽,註意://操作是遞歸的- 遍歷所有提取到的標簽,計算其中包含的
div數量,和p數量 p數量 和div數量的差值作為這個元素的權值,意思是如果這個元素裡包含瞭大量的p時,就認為這裡是文章主體- 通過比較權值,選擇出權值最大的元素,這便是文章主體
- 得到文章主體之後,提取這個元素的內容,相當於 jQuery[5] 的
outerHtml
簡單明瞭,測試瞭幾個頁面確實挺好。
不過大量提取時發現,很多頁面提取不到數據。仔細查看發現,有兩種情況。
- 有的文章內容被放在瞭
<article>標簽裡瞭,所以沒有獲取到 - 有的文章每個
<p>外面都包裹瞭一個<div>,所以p的數量 和div的抵消瞭
再調整瞭一下策略,不再區分 div,查看所有的元素。
另外優先選擇更多的 p,在其基礎上再看更少的 div。調整後的代碼如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
- 方法主體裡,先挑選出
p數量比較大的節點,註意if判斷條件中 換成瞭>=號,作用時篩選出同樣具有p數量的結點 - 經過篩選之後,按照
div數量排序,然後選取div數量最少的
經過這樣修改之後,確實在一定程度上彌補瞭前面的問題,但是引入瞭一個更麻煩的問題。
就是找到的文章主體不穩定,特別容易受到其他部分有些 p 的影響。
選擇最優
既然直接計算不太合適,需要重新設計一個算法。
我發現,文字集中的地方是往往是文章主體,而前面的方法中,沒有考慮到這一點,隻是機械地找出瞭最大的 p。
還有一點,網頁結構是個顆 DOM 樹[6]
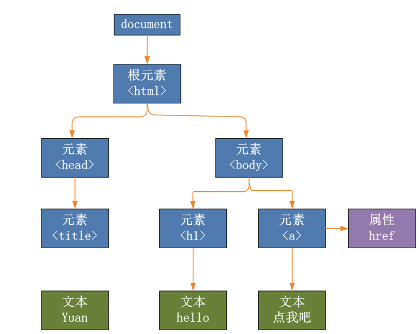
那麼越靠近 p 標簽的地方應該越可能是文章主體,也就是說,計算是越靠近 p 的節點權值應該越大,而遠離 p 的結點及時擁有很多 p 但是權值也應該小一點。
經過試錯,最終代碼如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
- 定義瞭一個
find函數,這是為瞭方便做遞歸,第一次調用的參數是body標簽,和前面一樣 - 進入方法裡,隻找出該節點的直接孩子們,然後遍歷這些孩子
- 判斷如果孩子是
p節點,提取出其中的所有文字,包括子節點的,然後將文字的長度作為權值 - 提取文字的地方比較繞,先取出直接的文本,和間接文本,合成
list,對每部分文本做瞭去除前後空字符,最後合並為一個字符串,得到瞭所包含的文本 - 如果孩子節點不是
p,就遞歸調用find方法,而find方法返回的是 指定節點所包含的文本長度 - 在獲取子節點的長度時,做瞭縮減處理,用以體現距離越遠,權值越低的規則
- 最終通過 引用傳遞的
sel參數,記錄權值最高的節點
通過這樣改造之後,效果特別好。
為什麼呢?其實利用瞭密度原理,就是說越靠近中心的地方,密度越高,遠離中心的地方密度成倍的降低,這樣就能篩選出密度中心瞭。
50% 的坡度比率是如何得到的呢?
其實是通過實驗確定的,剛開始時我設置為 90%,但結果時 body 節點總是最優的,因為 body 裡包含瞭所有的文字內容。
反復實驗後,確定 50% 是比較好的值,如果在你的應用中不合適,可以做調整。
總結
描述瞭我如何選取文章主體的方法後,後沒有發現其實很是很簡單的方法。而這次解決問題的經歷,讓我感受到瞭數學的魅力。
一直以來我認為隻要瞭解常規處理問題的方式就足以應對日常編程瞭,可以當遇到不確定性問題,沒有辦法抽取出簡單模型的問題時,常規思維顯然不行。
所以平時我們應該多看一些數學性強的,解決不確定性問題的方法,以便提高我們的編程適應能力,擴展我們的技能范圍。
期望這篇短文能對你有所啟發,歡迎在留言區交流討論,比心!
參考資料
[1]
Curl 轉 Python: https://curlconverter.com/
[2]
wkhtmltopdf: https://wkhtmltopdf.org/
[3]
xpath: https://www.w3school.com.cn/xpath/xpath_syntax.asp
[4]
Scrapy: https://scrapy.org/
[5]
jQuery: jquery.com
[6]
DOM 樹: https://baike.baidu.com/item/DOM%20Tree/6067246
以上就是python實現精準搜索並提取網頁核心內容的詳細過程,更多關於python搜索並提取網頁內容的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- python實現Scrapy爬取網易新聞
- 使用scrapy實現增量式爬取方式
- Python Scrapy實戰之古詩文網的爬取
- python實現csdn全部博文下載並轉PDF
- Python scrapy爬取起點中文網小說榜單